2022年末にリリースされたOpenAIのサービスChatGPTが世界中で話題になっています。ChatGPTはGPT-3.5という言語モデルを使ったサービスですが、GPTというのはGenerative Pre-trained Transformerのことです。今回は、ChatGPTの元ネタであるTransformerについて解説します。
過去の関連記事を参照してもらうことで、文系出身者にも直感的に理解してもらうことを心がけていますので、是非過去の記事も併せて参照ください。


Transformerとは何か
Transformerは、2017年に論文”Attention is All You Need”で紹介された自然言語処理のためのディープラーニングのモデルです。
名前からもわかる通りAttention機構を採用しており、特にMulti-Head Attention機構を用いて系列データの全要素間の関係を距離に関わらず把握でき、可変長の入力を扱うことができ、またRNNを使わずに計算を並列化することで学習と予測の高速化を実現しています。
Transformerは自然言語処理の中でも機械翻訳などのタスクで非常に強力であることが証明されており、以下の図の通り自然言語処理における多くの最先端モデルのバックボーンとなっています。

詳細は後述しますが、以下が元論文にも掲載されているTransformerの図を一部修正した図です。

自然言語処理・言語モデルとは何か
Transformerの中身を説明する前に、そもそも自然言語処理・言語モデルとは何かについて説明します。自然言語処理(NLP, Natural Language Processing)は自然言語をコンピュータに扱わせることを指し、具体的には文書の分類や要約、機械翻訳、対話などが含まれます。
ではそもそも自然言語(natural language)とは何かというと、英語、フランス語、日本語、手話など、人間が互いにコミュニケーションをとるための手段で、自然発生的に形成された言語のことを指します。一方特定の目的のために人間が作り出した言語のことを人工言語(artificial language)と呼びます。例としてはエスペラント、数学の数式や表記方法、モールス信号等が挙げられますが、特にコンピュータが通常処理する人工言語がプログラミング言語です。プログラミング言語のような人工言語は高度に構造化されており、曖昧さがなく、自然言語のような豊かさや複雑さがありません。そのため、自然言語をコンピュータに処理させるアルゴリズムやモデルの開発が目指されてきたのです。
そして言語モデル(Language Model)というのは、自然言語処理の分野において文章生成、穴埋め問題、機械翻訳、質問応答などのタスクに応用される特定の確率分布です。具体的には、言語モデルはある文章が途中まで与えられたときの次の単語の確率を計算することができ、最も確率の高い単語を出力します。”I have a”と入力した時に次に来る単語は何かを予測するとイメージするとわかりやすいかもしれません。
古くは1950年代から統計的手法による言語モデルが存在しましたが、言語モデルが一般に認知されるようになったのは、Google翻訳やDeepLなど機械翻訳やChatGPTといったディープラーニングを用いた手法でしょう。言語モデルについての詳細は以下を参照ください。

Transformerが出現した背景背景
Transformerの論文が発表された当時、自然言語処理、特に機械翻訳のためのディープラーニング技術としては、RNNを用いたseq2seqモデルが一般的でした。RNN及びseq2seqモデルについては以下の記事を参照ください。
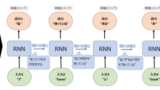
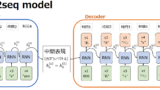
その中で出現した課題を解決するための技術として考案されたのがTransformerです。どのような課題があったのか、以下に紹介します。
固定長ベクトルの限界
seq2seqモデルでは、中間表現として予め決められた固定長のベクトルを使って推論されていました。そのため、学習時に使った文章より著しく長い文章が入力として与えられた際に中間表現のベクトルの表現力が足りず、出力の精度が高くならないという問題がありました。
これは、Transformerの中でも使われるAttention機構によって解決されます。Transformerが紹介された論文のタイトルが”Attention Is All You Need”であることから伝わる通り、Transformerの核がAttention機構です。Attention機構については以下を参照ください。
逐次計算を並列計算に変えたい
RNNの場合、単語を1つずつ入力し、その内容をもとに次の単語を処理するため、長文を入力すると、処理が非常に重たくなります。Attention機構が開発されて以降も、基本的にはRNNを用いたseq2seqモデルの中でAttention機構が用いられていたため、この課題は未解決でした。これを解決するために、当時はCNNを用いたモデルなども考案されましたが、それだと今度は離れた単語同士の関係性を反映できず精度が上がらない、という別の課題に直面しました。
これらを一挙に解決するために考案されたのが、後述のMulti-Head Attentionです。Mutli-Head AttentionによってRNNもCNNも使わずに高速に単語同士の関係性を捉えることができるようになったことが、論文のタイトル”Attention Is All You Need”にも表れていますね。
Transformerのアーキテクチャ
ではいよいよTransformerについて説明します。冒頭で示したTransformerの図ですが、個人的には省略されている部分が多く想像しにくいと感じますので、かなりbusyになりますが以下の図を使って説明します。
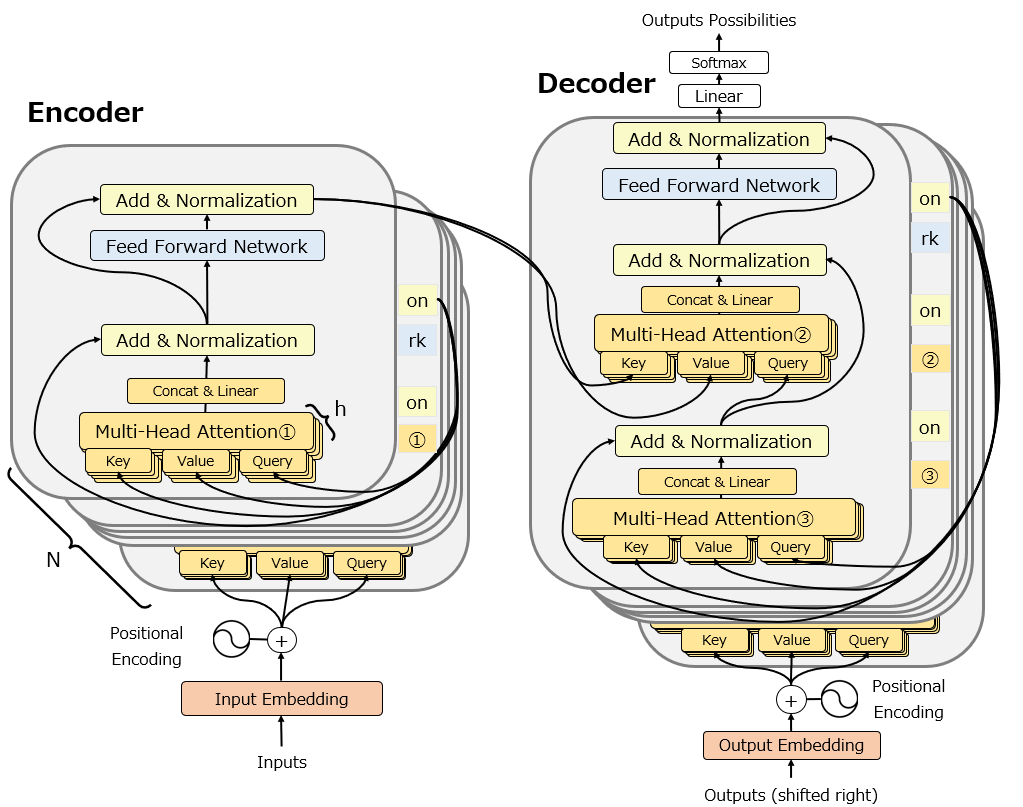
Mutli-head attention
まずはTransformerの最重要要素であるMulti-Head Attentionです。その名の通り、Attention機構を重ねて使う機構です。詳細は以下の記事を参照ください。

Word Embedding(単語埋め込み)
モデルのアーキテクチャ図において、入力も出力も初めに”Embedding”が登場します。これはWord Embeddingのことで、日本語では単語埋め込みと訳されます。自然言語処理で単語を扱う際、例えば”apple”という単語を扱うとき、”apple”という言葉をそのままコンピュータに処理させることはできないので、”apple”という単語に固有の番号、正確にはベクトル(方向と大きさを表す数学的表現)を与えて表現します。この処理をWord Embeddingと呼びます。
Word Embeddingのためにすぐに思いつく方法は、以下のようにどこか1つだけ”1″を振って他を0で表すOne Hot Encodingという手法です。

しかしこれだと、単語数分だけの列が必要になってしまい数十万次元という巨大なベクトルが必要になってしまう上に、単語同士の意味を反映させることができません。
2012年に発表されたword2vevはこの単語埋め込みをディープラーニングで実行することで、少ない次元数で単語をコンピュータが扱える次元数で表現できるうえに、それぞれの単語の意味も反映できるという手法でした。非常に有名な話で”王様”と”女王様”という言葉をベクトルで表現すると、”王様”-“男”+”女”が”女王様”に最も近いという数学的な演算を行うことができます。つまり、word2vecの単語埋め込みによって、”女”が”男”に関係するのと同じように、”女王”が”王”に関係することをコンピュータに理解させることができたのです。
word2vecを含めたword embeddingの手法については今後記事を掲載しますが、ひとまずその出力としては以下のようなものをイメージしてください。ここでは4単語ですが、もっと多くの単語数を5つの特徴ベクトルだけで表現できるものとして理解してください。
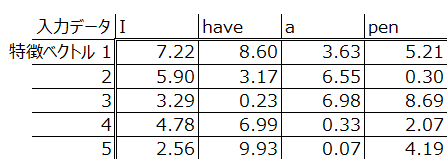
Positional Encoding
Transformerのアーキテクチャで、Multi-Head Attention以外で説明が必要なのがPositional Encodingです。Positional Encodingは、Word Embeddingで埋め込まれた特徴ベクトルに、位置ベクトルを追加します。詳細は以下の記事を参照ください。
その他のアーキテクチャ
TransformerにおけるMulti-Head Attentionとpositional encoding以外のアーキテクチャは、いたって普通です。以下では簡単に説明します。
Add & Normalization
AddというのはCNNのResNetで導入されたようなskip connectionのことを指します。前の層の値を、処理しない形でもスキップして次のステップに送ることで勾配消失を回避する手法です。ResNet及びskip connectionについてはまた今後詳細記事を掲載します。
Normalizaitonは正規化です。TransformerではLayer Normalizationが実装されています。バッチ正規化については以下を参照ください。
Feed Forward Network
この部分は2層の全結合NNであり、言ってしまえば”普通のニューラルネットワーク”の順伝播処理です。ニューラルネットワークによる順伝播については以下を参照ください。

Transformerの応用
以上、Transformerについて解説しました。Transformerによって自然言語処理の世界は大きく変わりました。 Transformerの登場以後は、巨大テック企業がとにかく巨大な言語モデル(LLM)を事前学習させて、それらをファインチューニングして使う、もしくはそのまま使う、という環境が急速に整備されました。
GPTシリーズやBERTはTransformerの翌年にはリリースされています。特にGPTシリーズはその後もモデルの巨大化が進み、GPT-3が人間のものと見分けのつかないブログ記事を書いたり、GPT-3.5がChatGPTに搭載されたりと、言語モデルはついに一般人にまで広まる様になりました。

今後、Transformerを使った各モデルについても解説記事を掲載しますので、お待ちください。

コメント