今回は機械学習の1分野であるディープラーニングについて、その概要を解説します。過去の記事については以下を参照ください。


ディープラーニングとは何か
過去の記事でも紹介した通り、ディープラーニング(深層学習)とは、ニューラルネットワークを活用した機械学習の手法です。そして機械学習というのは、AI・人工知能の一部です。以下の図を参照ください。
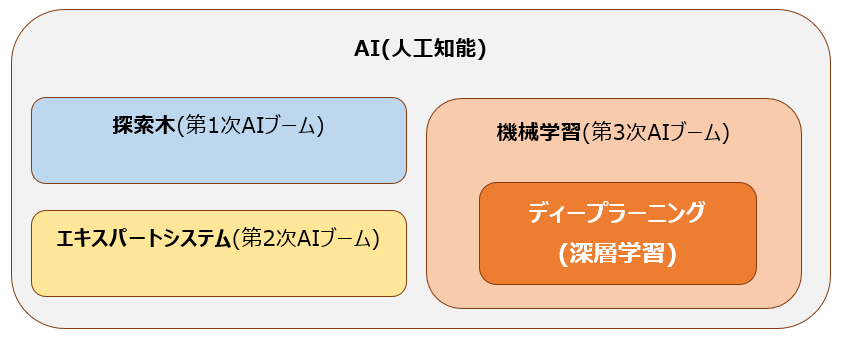
AI・人工知能と言ってもその中身は様々です。第1次AIブームで研究の進んだ探索木や、第2次AIブームでのエキスパートシステムもAIに該当します。その中で、2010年代以降の第3次AIブームで中心となっているのが機械学習であり、その中の一つの手法がディープラーニングです。
機械学習というのは文字通り、機械が自ら学習する仕組みのことです。英語ではML(Machine Learning)とも呼ばれます。別の言い方をすると、データから学習して自動で改善していくモデルのことです。モデルというのは、機械学習のプログラムのことです。
この機械学習の分野において、特にニューラルネットワークを活用するものを、ディープラーニングと呼びます。
ニューラルネットワーク
ではニューラルネットワークとは何でしょうか。ニューラルネットワークは英語にすると”Neural Network”です。”Neural”は”Neuron”つまり脳の神経細胞であるニューロンのことで、ニューラルネットワークというのは脳の神経細胞が構築する複雑なネットワークを指します。詳細は以下参照ください。
ディープラーニングというのは一言でいえば、ニューラルネットワークによって人間の脳の活動を真似することで、従来の機械学習では実現できなかった複雑なモデルを構築することであると言えます。

パーセプトロン
では具体的にどのようにニューラルネットワークを構築するのかというと、その主なツールがパーセプトロンです。
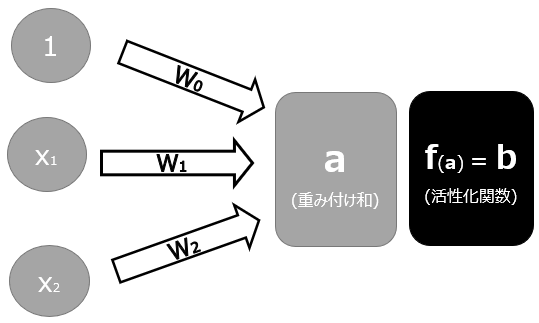
パーセプトロンというのは、複数の入力信号を受け取ってそこから1つの出力をするアルゴリズムです。以下がパーセプトロンの基本構造です。
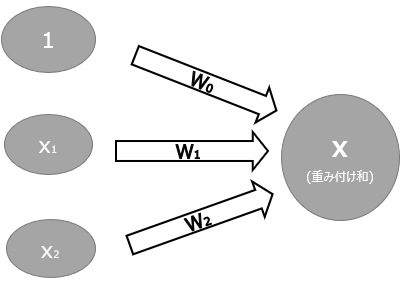
このパーセプトロンをたくさん組み合わせることで複雑なモデルの構築を目指します。パーセプトロンについての詳細は以下を参照ください。。
活性化関数
実際にディープラーニングで行われているような複雑な変換処理を実現するには、パーセプトロンを多層にするだけでは不十分です。そこで、さらに複雑な処理を可能にするために用いられるのが、活性化関数です。
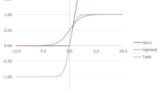
活性化関数(Activation function)とは、ニューラルネットワークの中間層において入力を別の形で出力するための関数です。
パーセプトロンによって一次関数の処理をどれだけ重ねても、複雑さは一定の域を出ません。そこで、上述の重み付け和を、何らかの活性化関数を使って変換することで、一次関数では実現できない複雑な変換を可能にするのです。活性化関数についての詳細は以下を参照ください。
複雑な関数
ここまでを纏めると、ディープラーニングの本質は、パーセプトロンや活性化関数によって線形分離に留まらない複雑な関数を実現することで、人間の脳のような複雑な処理を可能としているのです。
ニューラルネットワークの諸問題
機械学習よりも遥かに複雑な処理を実現したニューラルネットワークですが、問題も多くありました。以下では、ニューラルネットワークの問題と、どのように対応しているかを紹介します。
誤差逆伝播法
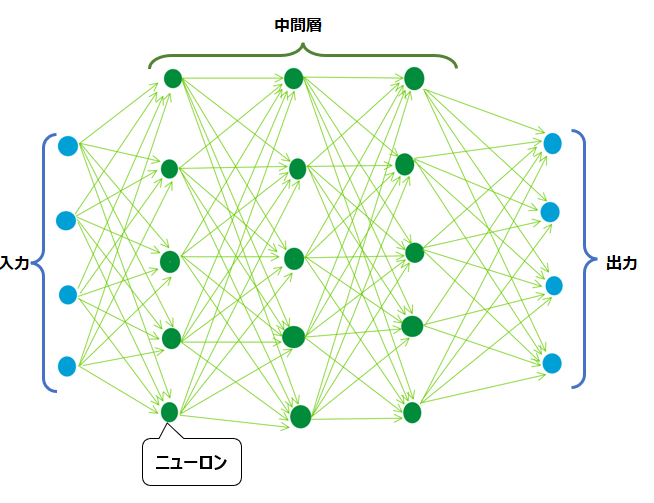
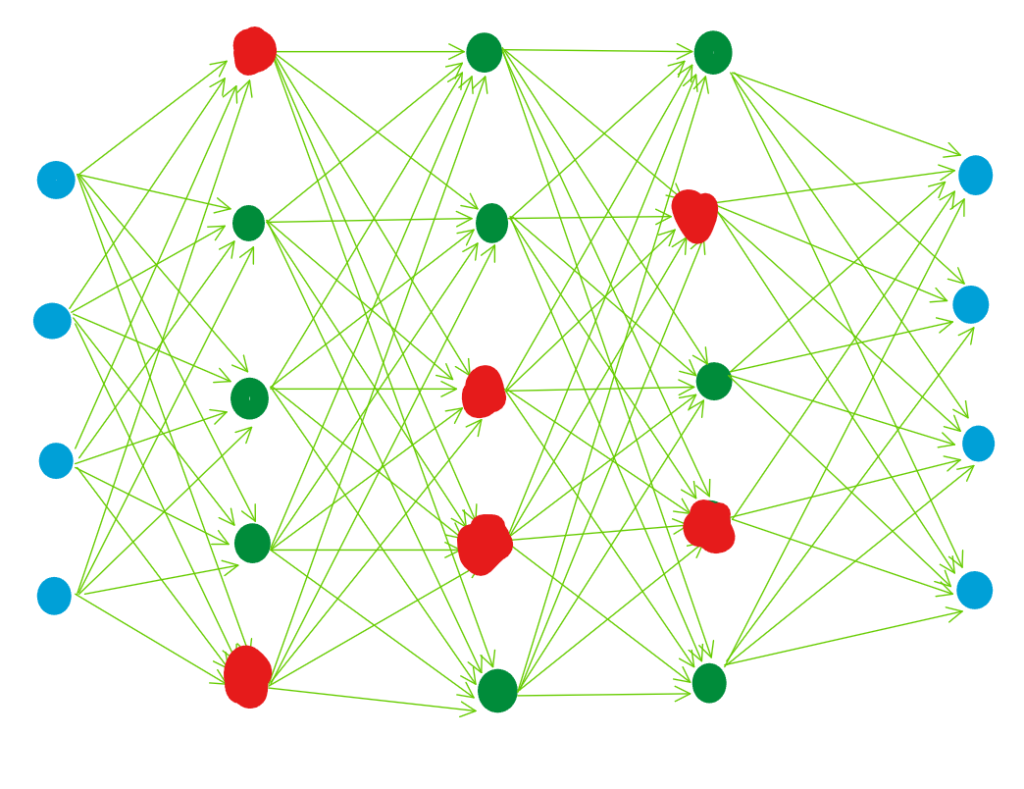
ニューラルネットワークの最大の特徴は複雑なネットワークです。下記の図のように、薄緑色の矢印の数だけ情報のやり取りがあり、その矢印1つずつに重みパラメータwが設定されています。下記のような簡単な構造のニューラルネットワークでさえ、50本の矢印が存在します。
機械学習と同様、ディープラーニングでも予測精度が高くなるような重みパラメータwを設定するために、勾配降下法を用います。勾配降下法については以下の記事を参照ください。

ただ、この勾配降下法をニューラルネットワークに対して適用しようとすると、計算量が多くなりすぎてしまいます。そこで、誤差逆伝播法を用いて、出力層側から順々に勾配を計算していくことで、計算量を減らす工夫がなされます。1990年代に定着した手法です。
詳細は以下を参照ください。

勾配消失問題
勾配消失問題は、隠れ層が多いディープネットワークで特に顕著で、勾配を計算するための誤差逆伝播を出力層から入力層にむかって繰り返し適用する際に、ネットワークを逆行するにつれて勾配がどんどん小さくなってしまうことにより生じます。
勾配降下法の記事で説明した通り、勾配は偏微分の値で判断されます。そして活性化関数の記事で図示する通り、Sigmoid関数を使う場合は傾きの最大値が0.25です。誤差逆伝播法の詳細記事に掲載しますが、中間層では、それより後ろの層の値を偏微分値を掛け算に使います。ある値に0.00~0.25の小さな値をかけ、それを手前の層に送り、手前の層でまた偏微分された0.00~0.25の小さな値が掛け算されます。
結果的に、入力層付近の手前の層では、勾配が非常に小さく、実質的にゼロになる可能性があります。勾配が0ということは、”パラメータを変えても精度が良くならない”ということであり、ここで学習が進まなくなってしまいます。
勾配消失問題は、重みの初期化、活性化関数、正規化技術など、さまざまな技術で対処することが可能です。例えば、活性化関数の記事で紹介するようにReLUを使用すると、正の入力に対して勾配がゼロにならないようにすることができ、勾配消失問題の防止に役立ちます。
ドロップアウト
ドロップアウトは、ディープラーニングにおける過学習を防止する手法です。具体的には、隠れ層のニューロンの一定確率(例えば全体の10%など)で不活性(drop out)にして学習することで、毎回使用される回路が変わります。
これにより、ニューロンの構造が変わるために毎回異なるモデルで学習させられるような状態となり、過学習防止の効果があるとされています。2013年ころから多く使われるようになりました。
Early Stopping(早期打ち切り)
Early Stopping(早期打ち切り)は過学習を防ぐために用いられる正則化手法です。学習の1サイクルの終わりに都度精度を監視しして、一定回数以上連続で精度が向上しなかった場合に、その時点で学習を終了させます。
2000年代には定着した、古くからの手法です。
バッチ正則化(Batch Normalization)
バッチ正規化とは、深層学習モデルのある層への入力が大きすぎたり小さすぎたりしないようにするための方法です。通常の正規化については以下の記事を参照ください。
バッチ正規化の場合は、この正規化の処理を、各層への入力データに対して実施します。最初の入力データを正規化したとしても、活性化関数の影響などで各層への入力は正規化されていない状態となります。そこに対して特定の層で正規化を行うことで、入力データへの世紀かと同じ効果を得ることができます。
ディープラーニングのアルゴリズム
ディープラーニングの具体的なアルゴリズムとしては以下のようなものが挙げられます。
DNN(Deep Neural Network)
上記で説明したような、ニューラルネットワークを何層も積み重ねることによって構成される、最も初期的なディープラーニングのアルゴリズムです。特に4層以上の場合にDNNと呼ばれます。
CNN(Covolutional Neural Network)
畳み込み(Convolution)という数学的な処理を適用することで、主に画像に対して効果を発揮しているアルゴリズムです。詳細は以下を参照ください。

ILSVRC2012のAlexNet以降、CNNの存在感は非常に大きくなりました。AlexNet及びその他のCNNのモデルについては以下を参照ください。

Deep Generative Model
Deep Generative Model(深層生成モデル)はその名の通り、分類ではなく何かを”生成”するためのモデルです。”ゴッホのような絵”を描いたことで2017年ころから一躍有名になったGAN(Generative Adversarial Network, 敵対的生成ネットワーク)や、同じく画像生成に用いられるVAE(変分オートエンコーダ)が有名です。2022年に画像生成で爆発的な話題を呼んだDALL-EなどのDiffusion モデルも、これらの進化系といえます。
今後詳細記事を掲載します。
RNN(Recurrent Neural Network)
用意した基本的な機構に対して、再帰的(recurrent)、つまり何度も繰り返し入力データが通過するような構造にすることで、系列データ(自然言語の文章など)に対して効果を発揮しているアルゴリズムです。詳細は以下を参照ください。
Transformer
自然言語の文章など、いわゆる”シーケンシャル(連続的)なデータ”を処理するために設計されています。Self Attention機構を用いるため、RNNでは対応が難しかった可変長の入力を扱うことができ、自然言語の処理の精度が爆発的に高まりました。
Transformerは2017年の論文で紹介され、以後機械翻訳などのタスクで非常に有効であることが証明されており、Google翻訳など多くの最先端モデルのバックボーンとなっています。現在話題筆頭のChat GPTや、その大元のGPT-3もTransformerを採用しています(GPTのTはTransformer)。
詳細は以下を参照ください。


コメント