今回はChatGPTによって世界的に大きな注目を集めるGPT(Generative Pretrained Transformer)について解説します。
GPTとは何か
GPT(Generative Pretrained Transformer)はOpenAIが2018年に公開した自然言語処理(NLP)のモデルです。GPTが一体何なのかを知るためには、その名前の由来を知ることが大切です。
まず“Generative”は生成的という意味です。このモデルが文章の生成のような生成タスクに使用されることを目的に作られたことがわかります。ChatGPTをイメージしてもらえれば、この点は理解しやすいでしょう。
次に“Pretrained”は事前学習済みという意味です。GPTは大量のテキストデータで事前に学習を行い、その後特定のタスクに対応するようにフィンチューニングを行います。詳しくは後述しますが、この事前学習とファインチューニングによって、手元のデータが少なくても高い精度を実現できるようになりました。
最後に”Transformer”は自然言語処理のディープラーニングアーキテクチャであるTransformerを使用しているという意味です。詳しくは後述しますが、GPTは特にデコーダを使うことで生成タスクに適したモデルになっています。Transformerについては以下を参照ください。
事前学習とファインチューニング
ではGPTにおける事前学習とファインチューニングとは一体どういったものでしょうか。
事前学習(Pretraining)とは何か
GPTのモデルは、7,000冊もの未出版本のデータと10億単語分のデータセットを用いて、あるk個の単語から次の単語を予測するというタスクを実行することで事前学習されました。
大量のデータを使って次の単語予測という問題をひたすら解かされることで、言語を広く抽象的に理解することにつながりました(少なくとも表面上はそう見える)。なお、ここで次の単語予測というタスクを解いているのは、手元の大量のデータから予測問題を作るのが簡単だったことと、このタスクで文法や単語など様々な側面から言語を理解できることがわかっていたためです。
ファインチューニング(Fine-tuning)とは何か
ファインチューニングでは、事前学習済のGPTのモデルを、解きたいタスク(2択問題を解くのか、文章を生成するのかなど)に合わせて最終層を取り換えて、少ない回数で再学習します。なおこの時、転移学習(Transfer learning)とは異なり、パラメータ全体を学習します。
これによって、例えば自社の顧客対応に特化したカスタマーサポートシステムを構築したり、業界の専門知識を有したチャットボットを構築することができます。
事前学習とファインチューニングの意義
では、事前学習とファインチューニングの意義は何でしょうか。これは、手元に大量のデータがなくとも高精度の自然言語処理モデルを構築できるようになったということです。
2010年代前半にはGAFAMのような超巨大IT企業でなければ作れないし使えないと思われていたLLM(大規模言語モデル)ですが、GPTが示したように事前学習とファインチューニングを行うことで、少量の自前のデータを用意するだけでLLMであるGPTを使えるようになったのです。
この意味でGPTが実現したことはLLMの民主化です。実際その最たる例が、文章生成に特化したサービスとして無償公開されているChatGPTです。
Transformerのデコーダ
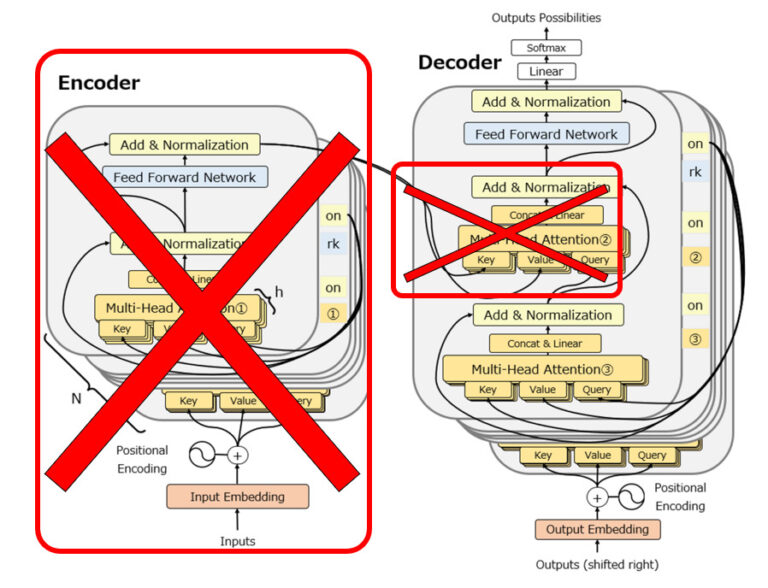
上述の様に、GPTはTransformerのデコーダを使うことで生成タスクに適したモデルになっています。ではなぜGPTはTransformerのデコーダだけを使っているのかと言うと、名前からもわかる通りGPTは生成モデル(Generative Model)だからです。過去にseq2seqモデルの記事でも解説したように、エンコーダーは入力の意味を理解し、デコーダーは理解内容から出力をします。
詳しくはseq2seqモデルの記事を参照ください。
ここから、なぜGPTがTransformerのデコーダだけを使っているのかを理解することができます。Transformerのエンコーダは言語の意味を理解するのに適したアーキテクチャですが、生成モデルであるGPTは、”言語の意味の理解”を完了した状態でリリースされます。既に言語を理解しているのだからエンコーダは不要です。
一方デコーダはどうでしょうか。Transformerの記事でも説明した通り、TransformerのデコーダにはMasked Multi Attentionが実装されていますが、これはRNNと同じように過去の単語にしか注意を向けないような仕掛けです。GPTが使われる文章の生成というタスクは、常に単語を1つ1つ前から順番に出力する必要があり、その際にまだ出力もしていない未来の単語を参照することはできません。GPTにとって、Transformerのエンコーダは不要である一方、デコーダがまさに必要なのです。
GPTシリーズとChatGPT
上で説明したGPTをGPT-1として、GPTシリーズは以下のように進化を続けました。
GPTシリーズ
GPT-1
GPT-1 (2018年): 上述の様に、Transformerを基にした最初のGPTモデルです。モデルのパラメータ数は1.2億個で、当時の多くのモデルと比較して非常に大きなモデルでした。
GPT-2
GPT-2 (2019年): GPT-2はGPT-1の次のバージョンで、パラメータ数は15億個と大幅増、さらに学習に使用したデータも約10倍でした。
GPT-3
GPT-3 (2020年): GPT-3はさらに大規模なモデルで、パラメータ数はなんと1750億個にも達しました。これにより、GPT-3はより長く、より深い文脈を理解し、あらゆるタスクで驚異的な性能を発揮しました。
また、GPT-3では、ファインチューニングが不要で、zero-shot、one-shot、few-showの3種類の方法で出力できます。zero-shotは”翻訳”や”文章生成”などタスクを指定するだけですぐに出力させること、few-shotはタスク指定後に2つ以上の例を教え、出力させることです。いずれにしても、ファインチューニングが不要になり、GPT-1,2と比較して精度だけでなく利便性も増しました。
GPTの名前を初めて世に知らしめたのもこのGPT-3です。ランキングトップだったブログ記事がGPT-3が書いたものだったり、ネット掲示板で誰にも気づかれずに投稿を続けていたり(あまりにも掲示板に常駐していてバレた)と、それまでの常識を打ち破る精度を達成しています。
GPT-3.5/4
その後もGPTシリーズは進化を続けています。2022年にChatGPTに搭載されたGPT-3.5ではパラメータ数3550億個に及びます。2023年にリリースされたGPT-4は、パラメータ数などは公表されていませんが、性能が更に飛躍的に向上したことが発表されています。
GPT-4の現時点での性能については、米国の弁護士試験や米国共通テストのSATで、上位10%に入る能力を備えている、というエピソードがよく出てきます。これだけでも非常に能力が高いことがわかりますが、後述するChatGPTで様々試してもらえれば、誰でもその凄まじい性能を実感できるはずです。
ChatGPT
ChatGPTはGPTシリーズの言語モデルをベースに、OpenAIがリリースしたチャットサービスです。2022年11月にリリースされたときにはGPT-3.5が搭載されていましたが、現在ではChatGPT Plusという優良サブスクリプションに加入することでGPT-4のモードを使用することができるようになっています。
GPT-3.5の状態では日本語の精度・速度が低かったり、説得力に欠ける回答が多かった印象でしたが、GPT-4では日本語で十分精度が高く、また様々な分野・内容のやりとりを満足に行えるようになっています。
コメント