今回は自然言語処理の性能を著しく向上させたディープラーニング言語モデルのための手法であるAttention機構について説明します。
Attentionとは何か
ディープラーニングにおけるAttention機構とは、系列データ処理において、入力データの一部に選択的に着目するための技術を指します。ここでいう”入力の一部に着目する”というのは、例えば英仏翻訳タスクにおいて、以下(Attentionの元論文より)のように、それぞれの単語を訳す時にどの単語をどのくらい参照して翻訳するかを明示しています。例えばarrord(仏)とagreement(英)はほぼ1対1の関係翻訳できているが、zone economique europeenne(仏)とEuropean Economic Area(英)は、3つの単語の纏まり動詞を対応させて処理していることがわかります。

上記のように、注目すべきデータに動的に焦点を合わせることができたことで、特に機械翻訳の分野で劇的に性能を向上させることができました。以下、詳細を説明します。
seq2seqモデルの問題
そもそもAttention機構が開発される前、機械翻訳で注目を集めていたのはseq2seq言語モデルでした。seq2seqモデルについては以下の記事を参照ください。
seq2seqモデルの記事でも説明した通り、そのデメリットは中間表現が固定長ベクトルであるという点でした。そのような状況で2015年に発表された”NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE”という論文では、seq2seqの性能を向上焦るための手段としてAttention(論文中ではSoft Alignment)が提案されたのです。
Attention機構(Soft Alignment)
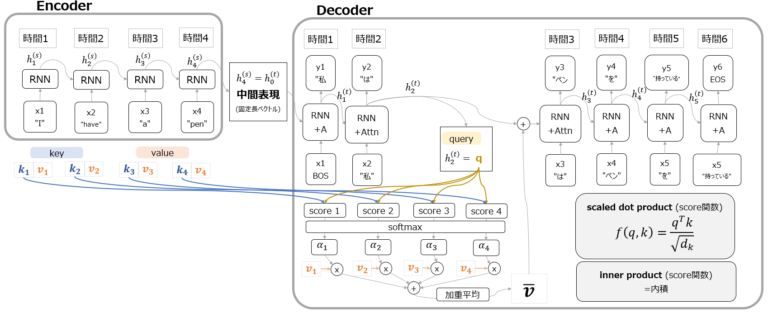
では、seq2seqの弱点を克服したAttention機構の内容を見てみましょう。全体図は以下の通りです。
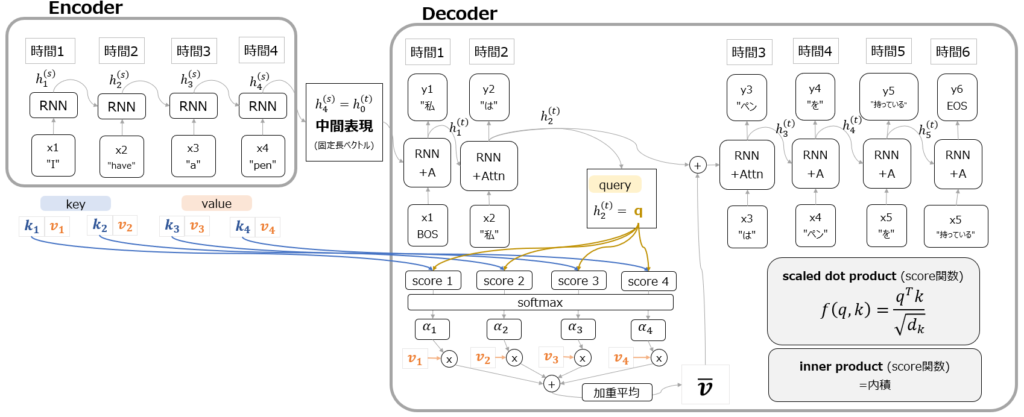
まず大枠の構造としては、seq2seqモデル同様、Encoderへの入力から固定長ベクトルの中間表現を得て、Decoderに渡し、出力を得るという構造になっていることがわかります。(以下赤字部分)
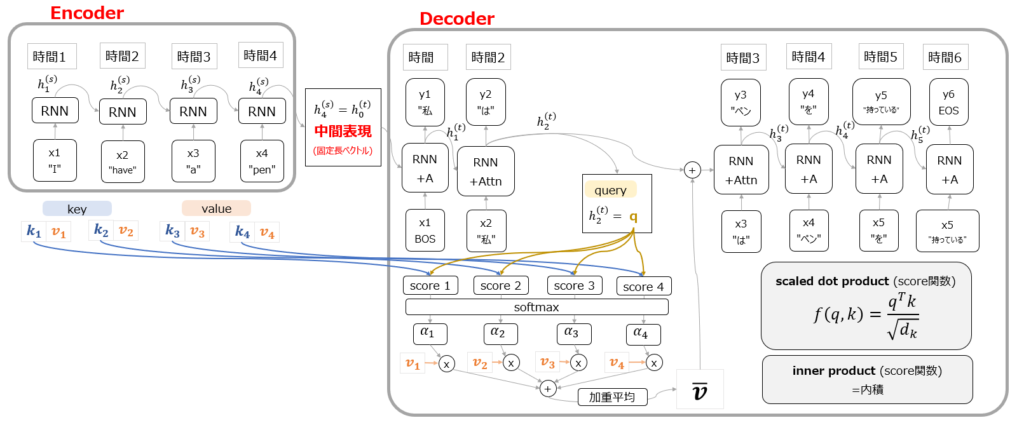
Attention機構で特徴的なのは、Encoderにkeyとvalue、そしてDecoderにqueryという合計3種類のベクトルが用意されていることです。(以下赤枠部分)
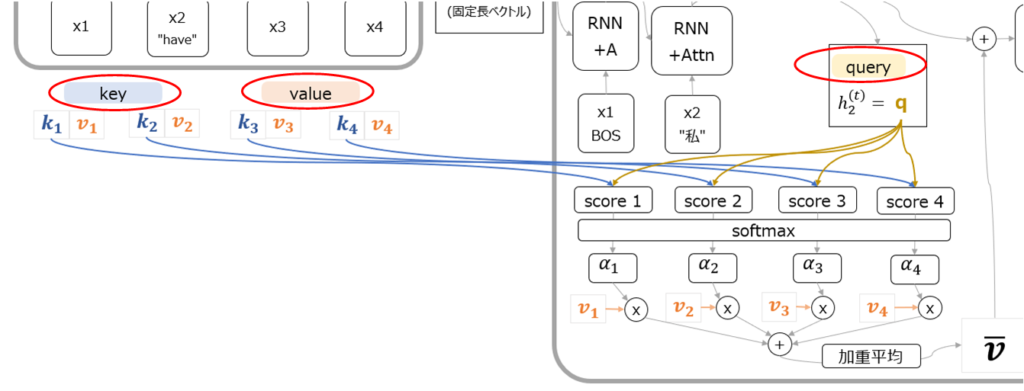
図を見てもらうとわかる通り、encoder側のkeyベクトルとdecoder側のqueryを基にscoreが計算されています。scoreの計算方法は以下の赤字部分の通りで、内積もしくは内積を正規化したscaled dot productです。
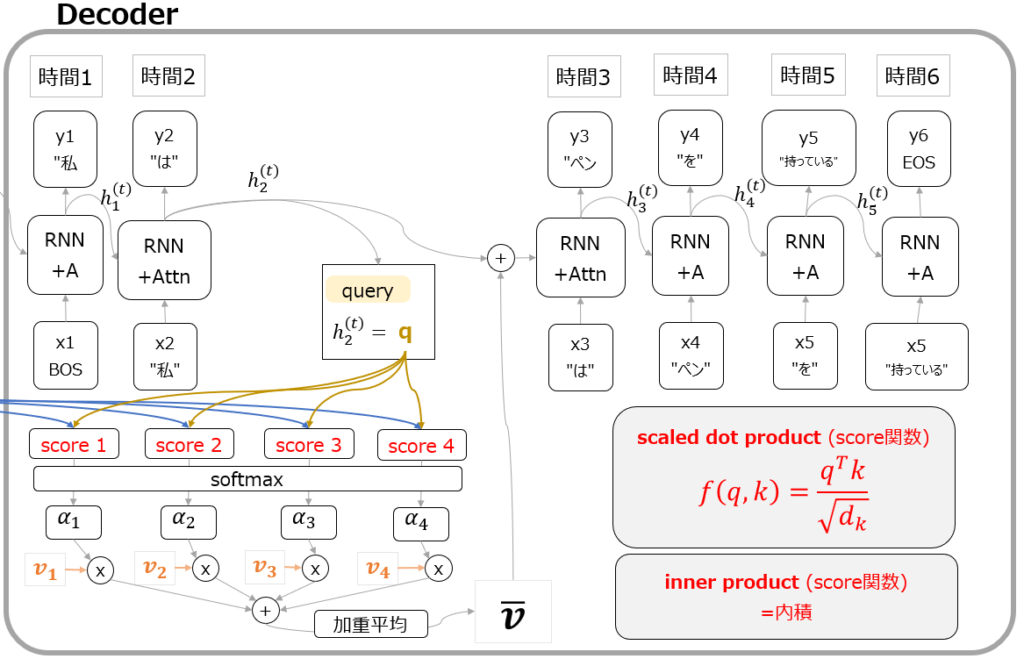
これを直感的に理解するなら、encoder側のどのkeyとDecoder側のqueryが似ていますか?という類似度スコアを計算しているということになります。そして冒頭の例で言えば、zone economique europeenne(仏)という3つの単語はそれぞれ、European Economic Area(英)という3つの単語との類似度スコアが高くなるのです。この類似度スコアをsoftmaxに通した後、それぞれのkeyに対応するvalueと掛け算して加重平均することで、次の出力で使うベクトルを生成しています。
ここでなぜ同じようなものに見えるkeyとvalueが別々に設定されているのかという疑問が出てくると思いますが、これに直感的に回答するのは非常に難しいです。強いて言えば、各入力の特徴量(意味)そのものであるvalueと、queryとの関連度を計算するための情報であるkeyは必ずしも同じ値ではない、といった回答になるかと思います。
いずれにしても、上記のような仕組みでdecoderの出力がどの単語に注意を向けるべきかというベクトルを付与した上で次のタイムステップの処理に移ることができるのが、Attention機構です。
ITシステムにおけるkey, value, query
上で出てきたkey, value, queryという概念は、ITシステムに精通していない人にとっては理解しにくい概念です。これらの概念は、データをデータベースに蓄積してあり、そのデータベースで何かを検索するようなケースでよく使われます。以下ではkey, value, queryを理解しやすいように説明してみます。
1. Key(キー)
ECサイトで”ガムテープ”と検索しているとき、たくさん存在するガムテープの各商品は一意(unique)の商品ID(これがkey)を持っています。このIDは他の商品と重複せず、その商品を特定するための識別子の役割を果たしています。
2. Value(バリュー)
ECサイトで検索し、あるID(key)の商品のページを閲覧すると、そのページにはID(key)に紐づいた商品の詳細情報(価格、製品の説明、在庫情報など)が表示されます。この詳細情報がValueです。
3. Query(クエリ)
クエリはデータベースから情報を引き出すための質問(query)のようなものです。ECサイトの例では、”ガムテープ”がqueryで、それはデに”ガムテープ”に関する商品情報を要求するクエリとなります。このクエリによって、データベースは”ガムテープ”に関連する商品ID(key)と商品情報(value)を検索し、その結果を表示します。
Attentionの応用
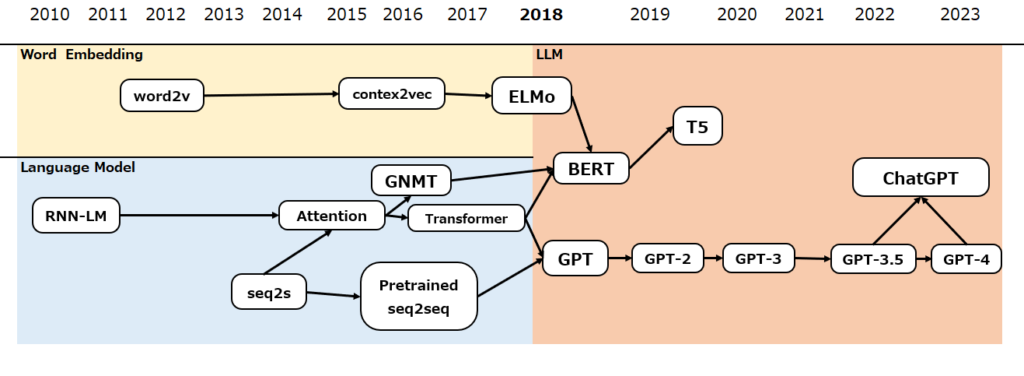
Attentionが大きく注目されるようになったのは、2017年の論文”Attention is All You Need”で、ここではAttentionを用いたエンコーダ・デコーダモデルのTransformerというアーキテクチャで、RNNを使わずともAttentionさえあえば自然言語処理で高い性能を実現できることが示されました。Transformerについては今後詳細記事を掲載しますのでお待ちください。
Transformer以後、自然言語処理の世界は大きく変わりました。GPTシリーズやBERTなどの大規模言語モデル(LLM)の登場により、巨大なリソースがなくとも高精度な言語モデルを使える環境が整いました。
その最たる例が、2022年末にリリースされたChatGPTです。今後それぞれ詳細記事を掲載しますのでお待ちください。

コメント