
今回は、AIとは何かということについて書きます。
AIの定義
AIはArtificail Intelligenceの頭文字で、日本語では人工知能と呼ばれます。
ではAI・人工知能とは何かということですが、実は明確・かつ唯一の定義があるわけではありません。1956年のダートマス会議(米国NH州)で初めてその言葉を使ったジョン・マッカーシーは、”知能を持ったコンピュータプログラム“と定義しましたし、日本におけるAI研究の第一人者である東大大学院の松尾豊教授は”人工的につくられた人間のような知能“と言っています。映画『ターミネーター』のイメージで語られるものもAIですし、Amazonのレコメンド機能もAIと言えます。その言葉が使われる文脈によって、様々な意味を持ちえます。
その意味では、人間の知的作業を代替するものはすべて”AI”と呼びうるのかもしれません。また、その対比として、人間の身体的作業を代替するものを”ロボット”と呼ぶことができるでしょう。
強いAIと弱いAI
とはいえ、”なんでもアリ”では、結局AIが何なのか、イメージができないでしょう。そこで、以下では理解の助けになる様に、“強いAI”と“弱いAI”という概念をご紹介します。
強いAI
ターミネーターに代表される、心や精神を持ったコンピュータのこと、もしくは「本物の心を持つ人工知能は、コンピュータで実現できる」と考える立場です。AIに対する漠然とした不安や恐れとともに語られることが多く、一昔前まで、AIと言えばこの強いAIのことをイメージしていたのではないでしょうか。
本物の心を持つ人工知能は、コンピュータで実現できる
弱いAI
一方弱いAIというのは、特定の問題を解決するための道具としてのAI、もしくは「コンピュータは人間の心を模倣するだけで、本物の心を持つことはできない」と考える立場です。AmazonのレコメンドやGoogle翻訳のように、すでに社会実装されている”弱いAI”は心も精神も宿していませんが、特定の問題を見事に解決しています。また、実証実験段階である自動運転の技術も、弱いAIの一種と言えるでしょう。
強いAIは実現可能か?
では、ターミネーターのような”強いA”Iは実現可能なのでしょうか?人間の心や精神を情報処理として捉える立場からは、”強いAI”は実現可能と考えられています。一方、人間のように意味や文脈を理解できるような”強いAI”は実現不可能という意見もあります。
さまざまなレベルの人工知能
また、人工知能を技術的な視点から分類する場合、従来からの単純な制御プログラムと合わせて、以下のように分類可能です。
単純な制御プログラム
洗濯機・エアコンのような家電製品を想像してください。これらに搭載された単純な制御プログラムでは、入力に対する出力が全て決められています。
古くからある、古典的な人工知能
掃除ロボットやチャットボットのように、推論・探索・知識ベースなどを用いるもので、”ルールベース(rule base)とも呼ばれます。プログラミングを経験した人なら誰でも知っている”If A Then B else C”といったルール設定し、そのルールと整合するように答えを導くプロセスを搭載しています。
機械学習
機械学習では、元々ルールが与えられているわけではない点がそれ以前のレベルの人工知能と大きく異なります。与えられているのはルールではなく、アルゴリズムと大量のデータです。こういったアルゴリズムと大量のデータを与えることで、ルールを自ら学習するのが、機械学習の特徴です。使用例としては、Googleの検索エンジンやマップの渋滞予測などがイメージしやすいかと思います。
単純化した具体例を出します。アルゴリズムをここでは”入力と出力を関連付けるための、ある方法”と考えてください。例えばアルゴリズムをy=ax+bとしましょう。
この時、サンプルデータが3つあり、入力(x)と出力(y)の組み合わせ(x,y)がそれぞれ、(1,3)、(2,5)、(3,7)だったとします。このデータを受け取ったコンピュータが、”これらのデータはy= 2x +1というルールで説明できるはずだ”と学習する、というイメージです。
機械学習については以下の記事で詳しく説明していますので、ご参照ください。

ディープラーニング(深層学習)
画像認識や自動翻訳に使われているのがディープラーニングです。スキャンアプリ、名刺アプリ、顔認識、Google翻訳など、広く実装されています。ディープラーニングを簡単に説明するのは難しく、通常は「機械学習の”特徴量”を自動的に学習すること」と説明されます。
これも、単純化して説明します。例として、”手書きの数字が1かどうかを判別する“というケースを想定してください。行(R)列(C)10マスずつのスペースに、著者が自分で”1″と書いてみました。この時R1C1からR10C10までの100個のマスが、白いマスか、黒いマスかを考えます。話を単純化するために、”マスの半分以上が黒くなってたら黒”とします。ざっと見た限り、11個のマス(R2C5,R3C4,R3C5,R4C5,R5C5,R6C5,R7C5,R8C5,R9C4,R9C5,R9C6)が”黒”です。残りの89個のマスは”白”です。
この時、“特徴量”というのは、100個の各マスの色(“黒”もしくは”白”)です。もしこれがフルカラー画像であれば、白黒の代わりに、色を表す数字が特徴量になるようなイメージです。
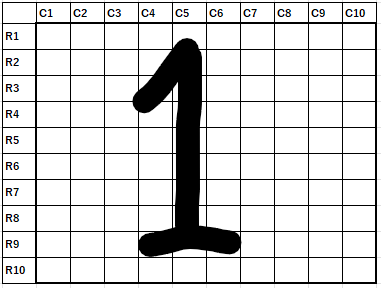
このとき、特徴量を自動的に学習するというのは、例えば大量の手書きの”1″のデータを用意し、どこのマスが”白”で、どこのマスが”黒”なのか(特徴量)を学習するということになります。例えば、R2C5-R8C5までは”黒”という特徴量が学習されると、そのルールに基づいて、初めて見た手書きの数字も、R2C5-R8C5が黒ならば”1″と判断できる、というイメージです。
詳しくは、以下の記事を参照ください。


コメント