
今回は、シーケンシャルなデータに対して用いられるAIであるRNN(Recurrent Neural Network, 再帰的ニューラルネットワーク)について解説します。過去に解説したディープラーニングの記事は以下を参照ください。

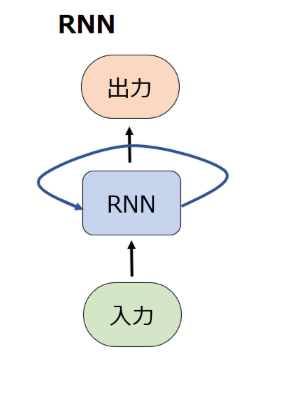
RNNとは何か
RNN概略
RNN(Recurrent Neural Network)は、シーケンシャルなデータ(連続データ、系列データ)を扱うために設計されたニューラルネットワークの一種です。RNNは、従来のfeedforward NNとは異なり、ある時間ステップから次の時間ステップに渡される隠れ状態を持ち、過去の入力に関する情報を保持できます。このためRNNは、言語モデリング、機械翻訳、音声認識など、入力データに時間的な関係があるタスクに適しています。RNNはセルの中身をLSTMやGRUなどに変更することで消失勾配問題を緩和することができます。
それぞれの言葉の意味は、以下で一つずつ解説します。
シーケンシャルデータとは何か
シーケンシャルデータとは、時間的または順序的な構造を持つデータで、要素の順序がデータの意味を決定する上で重要なデータです。最も分かりやすい例として、時系列データや自然言語のデータ、音声データなどが挙げられます。
例えば”I have a pen.”という文章が存在した場合に、この文章は単語の順番が変わってしまえば文の意味が変わってしまうことは理解できると思います。これが、”要素の順序がデータの意味を決定する”ということです。
時系列データは言わずもがな、2021/12/31のデータと2022/1/1のデータを入れ替えてしまっては、データの意味が変わってしまいますよね。
feedforward neural network
まずフィードフォワード(feedforward)という言葉についてですが、これはよく耳にするフィードバック(feedback)の反対概念です。この言葉は分野において言葉の使われ方が様々です。
例えばビジネス分野では、問題解決や意思決定に対する積極的なアプローチを”フィードフォワード”と呼ぶことがあります。ここでいう”フィードフォワード”とは、フィードバックを待ち、問題が起きてから対応するのではなく、潜在的なリスクや課題を予測し、前広に対処することを意味します。
また医療分野では、症状が出るのを待って治療するのではなく、予測分析を用いて特定の症状のリスクが高い患者を特定したり、予防薬などの先制治療を行うことで病気や症状の発生を予防するための積極的なアプローチを”フィードフォワード”と呼びます。
ディープラーニングの分野では、データがループを形成せずに入力層から出力層への一方向にのみ流れるニューラルネットワークのことを指します。以下の図のようにDNNやCNNで一般的なfeedforward NNは複数の層から構成され、ある層は前の層から入力を受け取り次の層に出力を渡しますが、この時ある層の出力が前の層の出力に影響を与える(フィードバック)ことはありません。フィードバックせずフィードフォワードしかしないニューラルネットワークなので、feedforward neural networkと呼ばれます。
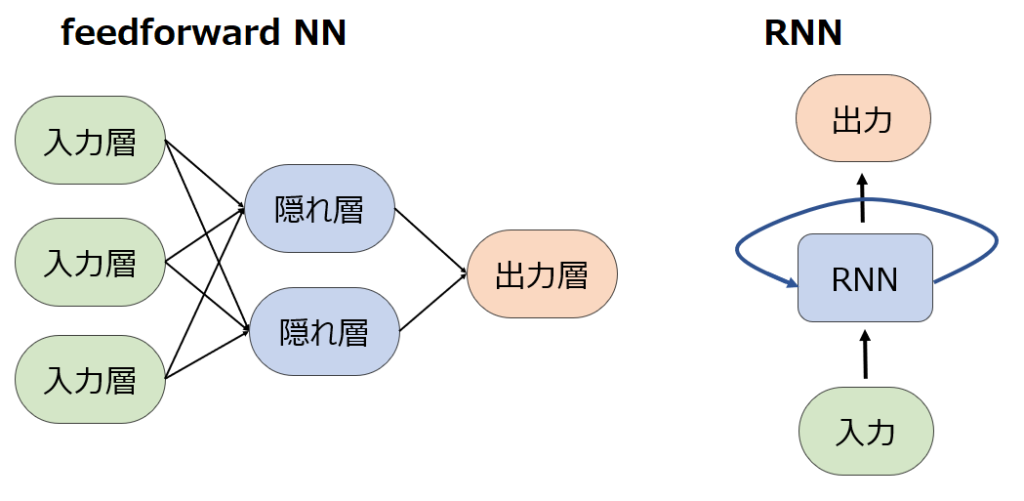
この時に重要なのは、feedfoward NNの場合、多層の場合の隠れ層はそれぞれ個別の重みパラメータを持っていますが、RNNの場合は再帰的という名前の通り、隠れ層に該当するブロックが1つしか存在しないため、常に同じ重みを共有して使い続けることになります。
隠れ状態(Hidden status)
冒頭で言及したRNNにおける”隠れ状態“というのは、ある時間ステップまでにネットワークが処理した情報をまとめたベクトルです。隠れ状態は、過去の入力からの情報を保持するために用いられ、ある時間ステップから次の時間ステップに渡されることで、ネットワークが過去の情報を現在の計算に取り込むことができます。直感的に説明するなら、”過去の入力全体に対する理解“と言えるかもしれません。
といっても、この説明だけでは全く意味が分からないと思いますので、ここで再びRNNの図をより詳細に見てみましょう。

先ほど”ループ”していると言っていた部分を分解してみました。例えば文章のデータであれば、実際には単語の数だけ時間ステップが存在します。上図では”I have a book.”という英語を日本語訳させています。
ここでいう隠れ状態(1~4)は、ベクトルで表される記憶の表現であり、時間ステップごとに現在の入力と直前の隠れ状態に基づいて更新されます。どういうことでしょうか。
例えば1単語目の”I”を入力した時点では、RNNは隠れ状態として“私”に関する情報としてベクトルが生成されます。あくまでイメージ図ですが、以下をご覧ください。。実際には何万次元という多次元ベクトル空間ですが、イメージしやすいように2次元の図としています。
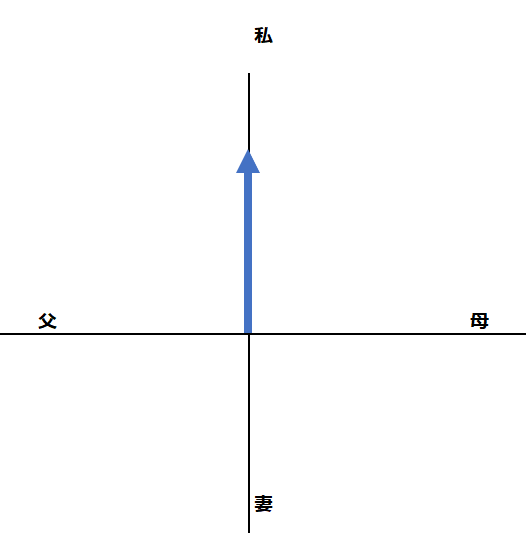
もし、1単語目が”I”ではなくて”My wife”であれば、隠れ状態のベクトルは以下のようになっていたはずです。
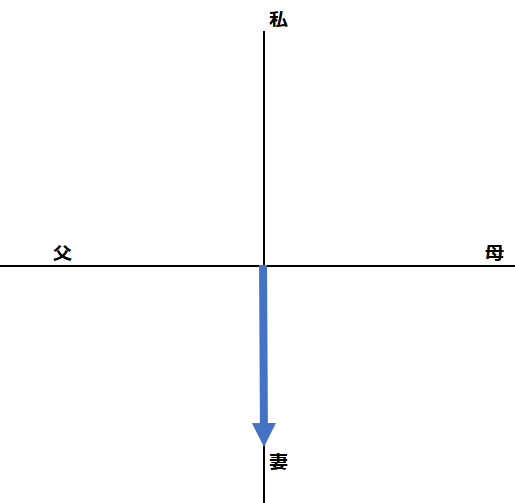
では、隠れ状態2はどのような状態でしょうか?こちらもベクトルを使って、以下の通り表すことができます。
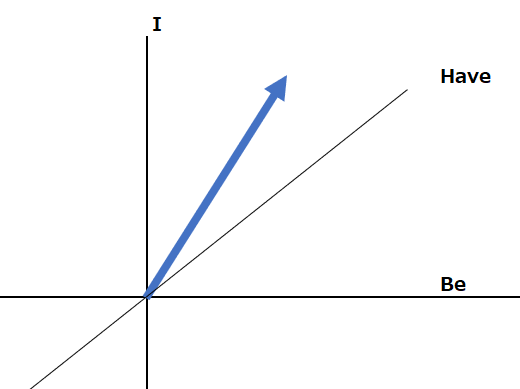
このように、隠れ状態を使用してこれまでに処理された単語に関する情報を保持することができます。隠れ状態は毎回更新され、更新された隠れ状態が次の時間ステップに渡されます。そうすることで、例えば”I have a”のあとに、”book”が来た時に、これが動詞の”予約する”ではなく名詞の”本” であると理解し、出力を生成することができます。
同様の処理が自然言語以外でもなされます。金融データのシーケンスを処理するRNNでは、各タイムステップである時刻の株価を受け取り、その隠れ状態は、これまでに処理された株価に関する情報を要約してくれます。隠れ状態は現在の株価に基づいて更新され、更新された隠れ状態は次のタイムステップに渡されます。これにより、RNNは経時的な株価の依存関係を把握し、将来の株価予測に活かせるのです。
セル
入力を処理するRNNのブロックをセルと呼びます。図における青枠部分です。
RNNの各セルは以下のイメージ図の通り、現在の入力(x)と過去の隠れ状態(hiddenのh)を入力として受け取り、出力(y)と更新された隠れ状態(h)を生成します。
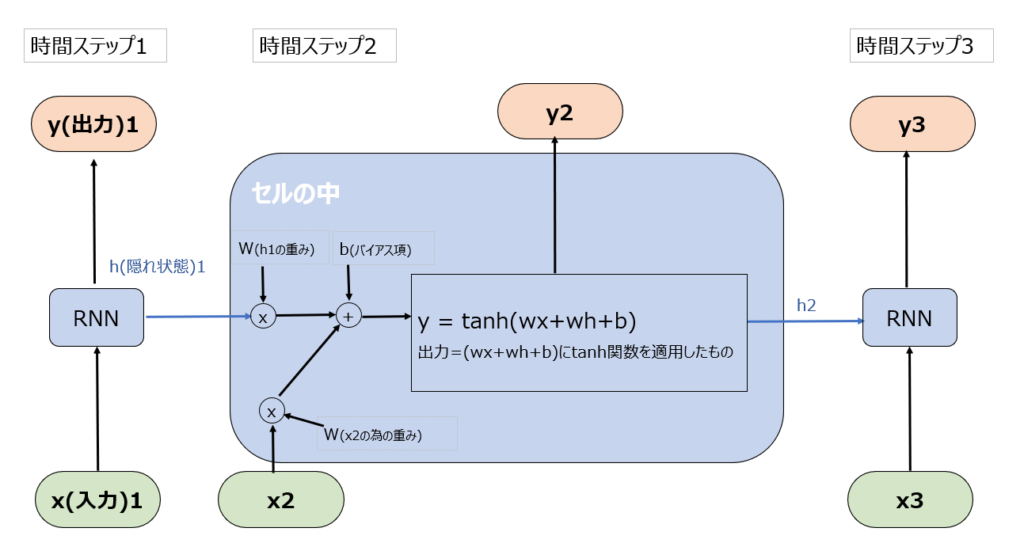
このセル部分がRNNの核心であり、同時に弱みでもあります。セルの中身を見てもらうと、掛けたり足したりしたものをtanh関数に突っ込んでいます。tanh関数については以下を参照ください。
長期記憶モデルの待望
単純なRNNはかなり昔から考えられていましたが、限られたタスクにしか使えませんでした。その理由は、複雑な記憶を保持できないためです。
tanh関数はどんな値であっても-1~+1に変換しますので、次の層に渡すh2の値も、最大+1、最小-1です。例えばh2とy2の値が+0.7だったとしても、x3の値に重みwをかけた値が例えば大きなマイナスの値だとすると、tanh関数の出力値であるh3とy3も-0.7になるようなケースが容易に想像できます。
tanh関数の出力で+0.7と-0.7というのは、大きな差です。あえて直感的なイメージとして仮に、例えば”私は本を持っている”を値にすると+0.7だったとして、”私は本を持っていない”が-0.7だとします。そうすると、ある1単語の影響が大きすぎて、隠れ状態=その時点での理解内容が、180度変わってしまったということになります。
自然言語の処理においては、例えば長文を要約するようなタスクが発生します。そこでは、”当初は本を持っていたが、紆余曲折あり今は持っていない。”といった要約を作成したい時に、”-0.7″の”本を持っていない”という内容に、隠れ状態が寄り過ぎてしまうのです。
そこで、RNN全体のアーキテクチャは活用しつつ、タスクの複雑さのレベルに応じてセルの中身を変化させる取り組みがなされました。それが今後紹介するセルであるGRU(Gated Recurrent Unit)やLSTM(Long Short-Term Memory)、更にその進化系のBi-LSTMです。
これらの開発によって自然言語処理へのディープラーニングの適用は大きく進展し、その後のAttentionとの併用で2016年にGoogle翻訳に搭載されたりと、RNNの進化系が大活躍するようになりました。
コメント