今回は自然言語処理のためのニューラル言語モデルであるseq2seq言語モデルを紹介します。
seq2seqモデルの概要
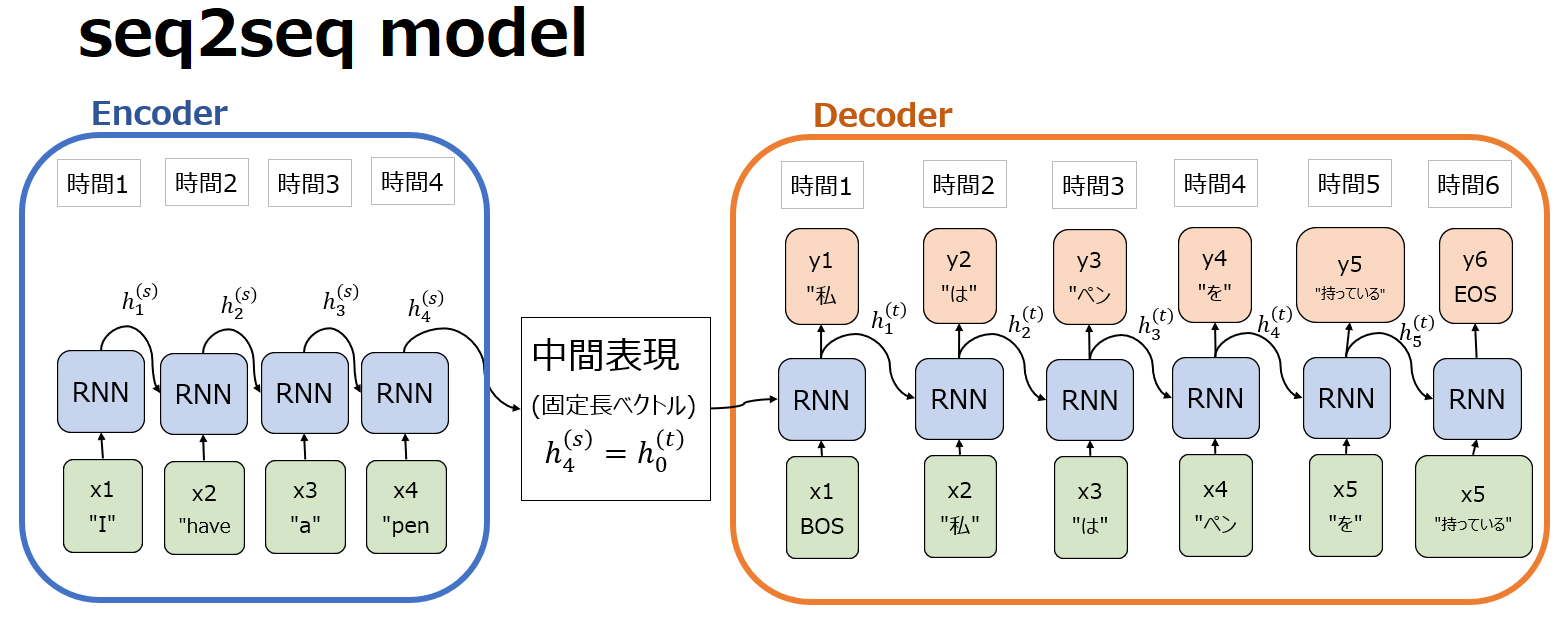
seq2seq 言語モデル(sequence-to-sequence language model)は、機械翻訳、要約、対話生成などの自然言語処理タスクで使用されるディープラーニングモデルの一種です。その名の通り、ある系列データ(sequence)を別の系列データに変更します。このモデルはエンコーダ部とデコーダ部を持つため、エンコーダ・デコーダモデル(Encoder Decoder model)の一種でもあります。エンコーダでは、文章などの入力データ列を受け取り、”隠れ状態(hidden state)”と呼ばれる固定長のベクトル表現に圧縮します。デコーダは、この隠れ状態を利用して、ターゲットとなる出力データ列を生成します。典型的には以下のようなアーキテクチャです。

最初のSeq2Seq LMモデルは、2014年にSutskever氏らの論文”Sequence to Sequence Learning with Neural Networks”において、長期記憶と短期記憶を保持可能なLSTMを用いたエンコーダ・デコーダ・アーキテクチャに基づく機械翻訳のモデルとして紹介されました。この論文では、LSTM搭載seq2seqモデルによるニューラル機械翻訳(NMT, Neural Machine Translation)が、それまでの長年のノウハウの蓄積であり当時主流であった統計的機械翻訳(SML, Statistical Machine Learning)の精度を凌駕したことに対する驚きが述べられています。LSTMについては以下を参照ください。
seq2seqの言語モデルのアーキテクチャはその後AttentionやTransformerにも引き継がれ、GPTシリーズはBERTなど現在大活躍中の大規模言語モデル(LLM)にも部分的に搭載されており、大変重要です。一方でseq2seqモデルは前後の文脈なく説明されることが多く混乱する人も多いと思いますので、以下ではそもそもseq2seqがどのようなことをしているのかを直感的に説明した上で、言語モデルとは何か、またRNNとの関係性を説明します。
seq2seqモデルのエンコーダとデコーダの役割
そもそもseq2seqモデルにおいてエンコーダとデコーダは何をしているのでしょうか。上記の説明ではエンコーダは文章などの入力データを固定長のベクトル表現の”隠れ状態(hidden state)”に圧縮し、デコーダは隠れ状態を利用してターゲットとなる出力データ列を生成する、としました。しかし、これだけではイメージができないかもしれませんので、直感的に説明してみます。
ここでのエンコーダとデコーダの役割は、実は人間の脳の働きと似ているかもしれません。人間が何か情報(映像、文字、音など)を受け取った時、それらは入ってきた情報のまま保持されるわけではなく、脳内のニューロンの様々な経路を通じて処理され、特定の意味や抽象的な情報に変換されます。
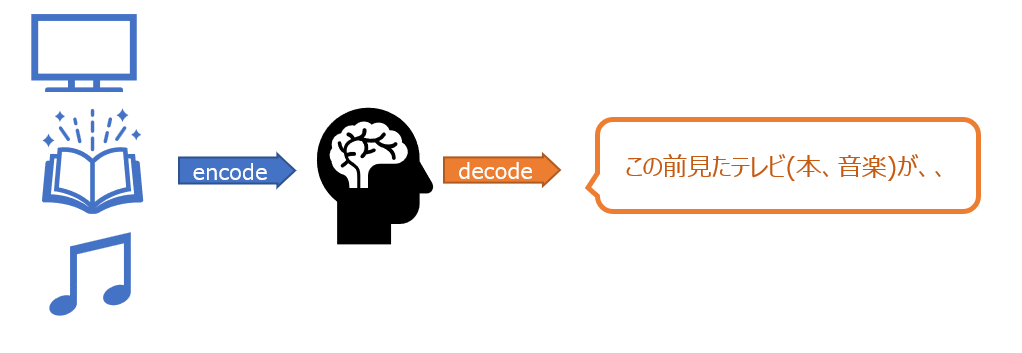
これと関連して理解するならば、エンコーダは情報の意味を理解する役割を、デコーダは理解した内容を基に元の情報と同じ意味の出力をする役割と言えるでしょう。
言語モデルとは何か(LM)
次に言語モデルについて解説します。言語モデル(Language Model)というのは、自然言語処理の分野において文章生成、穴埋め問題、機械翻訳、質問応答などのタスクに応用される確率分布です。具体的には、言語モデルはある文章が途中まで与えられたときの次の単語の確率を計算することができ、最も確率の高い単語を出力します。最もわかりやすい使い方は、”I have a”まで文章が与えられたときに次の単語は何かを予測する、というイメージです。詳細は以下の記事を参照ください。

RNN-LM
過去に説明したLSTMやGRUのようなゲート機能付きセルを使ったRNNにより、長期記憶と短期記憶を持つことができました。これは言い換えると、遠い単語も近くの単語も加味して次の単語を予測できる、より専門的に表現すれば単語間の長期的な依存関係を捉えられるようになったということです。RNN、LSTM、GRUについて以下を参照ください。

これらRNNを使った言語モデルのことをRNN-LMと呼びます。RNN-LM実装に成功した最初の例は、word2vecで有名なMikolov氏らが2010年に発表した論文で提案されています。
seq2seqはRNN-LMより何が優れているか
RNN-LMによって遠く離れた単語間の関係を捉え、単純な単語の生成確率をモデル化できるようになりました。これによって”I have a “の続きを予測させるような単純なテキスト生成はできるようになったものの、実際には単純な生成のタスクというのはそれほど多くなく、むしろ条件付きの生成確率、生成モデルが必要になるケースが多いことが想像できると思います。例えば入力を日本語、出力を英語という条件での生成確率であったり、入力を画像、出力を文章という条件での生成確率が必要になる、ということです。機械翻訳はまさに条件付生成モデルです。
こういったケースで条件付確率をモデル化するのが、seq2seqモデルです。エンコーダで条件を受け取ってそれを隠れ状態に反映させ、それをデコーダに渡すという構造が、条件を加味した生成に向いていることが直感的に理解できるのではないでしょうか。
seq2seq(エンコーダ・デコーダモデル)の限界
新たな可能性を開いたseq2seqモデルですが、一方で中間表現の隠れ状態が固定長ベクトルであるという制約があります。ここで固定長ベクトルというのはベクトルの大きさが決まってしまっているということで、入力の大きさに関係なく、常にある一定の数の要素、すなわちある一定の次元を持つベクトルになります。例えば、固定長を100とすると、隠れ状態は常に100個の数字からなるベクトルと決まってしまいます。
なぜベクトルの次元が決まってしまうことが問題なのでしょうか。以下の2軸で生徒のタイプを評価することを想定してみましょう。ここでは”論理的思考力”という軸と”理系指数”という2軸で評価しており、ベクトルで言えば2次元です。以下の青いベクトルは、論理的思考力が高いが文系寄りであることを表現できています。しかし、この2軸だけでは、”体育が得意”や”芸術に秀でる”などのスキルはわからず、更には非認知能力も全く評価できません。全ての生徒を2次元のベクトルで評価してしまうので、情報量が減ってしまうことがわかると思います。

ベクトルの固定長が小さすぎると情報が失われ、性能が低下することは理解できたかと思います。では固定長を大きくすればどうかと言えば、大きすぎるとモデルの計算量が多くなり、かつ過学習に陥る可能性が出てきてしまいます。これが、固定長ベクトルの問題点です。
seq2seqモデルでは長文、特に学習コーパスの文より長い文に対応することが困難になる場合があり、実際に入力文が長くなるにつれて急速に精度が悪化することを示した論文も発表されています。
こういったseq2seqモデルのデメリットを克服したのが、Transformerにも搭載されたAttention機構です。Attentionについては今後詳細記事を掲載しますのでお待ちください。

コメント