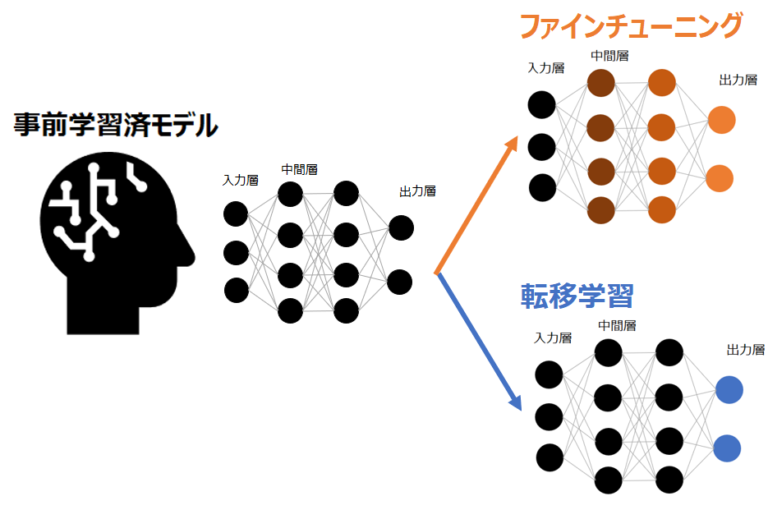
AI、特にディープラーニングの世界では、事前学習(Pretraining)、ファインチューニング(Finetuning)、そして転移学習(Transfer Learning)という言葉を頻繁に耳にします。今回は、これらの技術が何であるか、そしてそれぞれの違いは何なのかを解説していきます。
なお、ディープラーニングや機械学習については以下を参照ください。


事前学習、ファインチューニング、転移学習とは何か
まずはそれぞれの概念を説明します。
事前学習(Pretraining)
事前学習は、大きなデータセットを使って、ディープラーニングのモデルを学習させることです。なぜ”事前”学習なのかと言うと、ここで学習されたモデルは、その後ファインチューニングや転移学習を経て、モデルに大なり小なりの修正を加えた上で使用されることが前提になっているからです。
事前学習ではしばしば、非常に大規模なデータで学習が行われます。例えばOpenAI社の大規模言語モデルのGPTでは、7,000冊もの未出版本のデータと10億単語分のデータセットを用いて、あるk個の単語から次の単語を予測するというタスクを実行することで事前学習されました。GPTについては以下を参照ください。
ファインチューニング(Fine-tuning)
ファインチューニングは、事前学習で訓練されたモデルのパラメータを再学習するプロセスを指します。この際パラメータ再学習の対象になるは出力層だけでなく、出力層以外の全体もしくはその一部も含まれます。
例えば前述のGPTのファインチューニングでは、事前学習済のGPTのモデルを、解きたいタスク(2択問題を解くのか、文章を生成するのかなど)に合わせて最終層を取り換えた上で、少ない回数でモデル全体のパラメータを再学習します。
転移学習(Transfer-learning)
転移学習は、あるタスク(ドメイン=領域)で事前学習済のモデルを別のタスク(ドメイン)に転用することです。この時、事前学習済のモデルのパラメータは、通常ほとんどそのまま使われ、出力層のみタスクに応じて変更・再学習がされます。
ファインチューニングと転移学習の違い
では、ファインチューニングと転移学習は何が違うのでしょうか。一見すると両者は似ていますが、主な違いは事前学習モデルの取り扱いです。文献によっても定義が異なるので、確立された概念ではありませんが、一般には以下の図のように理解して問題ないでしょう。
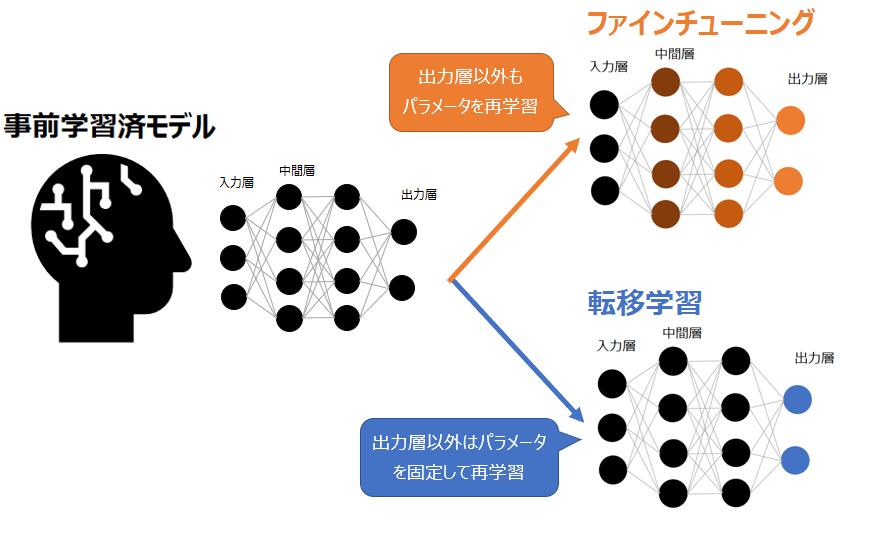
吹き出しで示した通り、転移学習では通常出力層以外のパラメータは固定されているのに対し、ファインチューニングは最終層以外のパラメータも再学習されます。大規模モデルでは中間層だけで何億というパラメータが用意されていますから、ファインチューニングと転移学習では再学習のコストが全く異なります。
もし上図でもうまく理解できない場合は、ファインチューニングと転移学習を直感的に理解してみましょう。まず転移学習は、既に習得している能力や理解している内容を基に、その能力や理解をできるだけそのまま活かせる別のタスクを実行するようなものです。よく見かける”犬を分類する事前学習済モデルを、猫を分類するモデルに転移学習させる”という例も、犬を分類するための能力の中身は、動物の基本パーツの形状や質感を理解する能力が含まれるので、それを活用すれば猫を見分ける能力は比較的簡単に習得できる、と解釈できます。
一方ファインチューニングは、既に習得している能力や理解している内容を十分参考にしながらも、別の能力や理解を得ることと言えるかもしれません。例えば英語を習得した人がフランス語を習得したり、バスケットボールを習得した人がハンドボールを習得することと言えるかもしれません。英語を習得した人は、そのまますぐにフランス語を使いこなすことはできませんが、英語を全く知らない人よりも高速にフランス語を習得できるはずです。

コメント