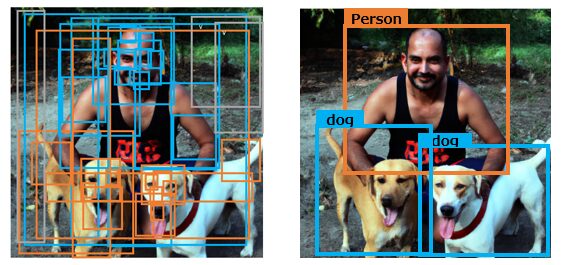
前回記事で説明した通り、物体検出モデルとは、画像内に何の物体がどこにあるのかを、バウンディングボックス(長方形の箱)とクラス(例:犬、猫、自動車等)で出力するモデルです。過去の記事は以下を参照ください。

今回はその中でも2段階物体検出モデルと呼ばれるアプローチについて解説します。
2段階物体検出モデル(Multi Shot Object Detection Model)
上述の通り物体検出モデルとは、画像内に何の物体がどこにあるのかを推定しますが、“何”=クラスを推定することと“どこ”=バウンディングボックスを推定することは本来別のタスクです。2段階物体検出モデルの場合、これらを別々のプロセスで扱います。
その第一段階では、“物体候補領域”または“領域提案”の生成を行います。これは、画像内に存在しうる物体の位置を大まかに特定するステップです。画像の各部分を見て、物体が存在しそうな場所を数多く出力します。このステップでの目標は、全ての物体が少なくとも一つの提案内に含まれることで、逆に背景など物体でない部分はなるべく除外することです。犬と人間と背景の画像なのに、”人”であることを提案する候補領域が存在しない、ということがないように、たくさん候補を生成するのです。

次に第二段階では、これらの候補領域それぞれについて、どのクラスに属する物体が存在するのか(あるいは物体が存在しないのか)、そしてその物体の具体的な位置(バウンディングボックスの座標)を精確に予測します。つまり、物体の「存在」を「何であるか」(クラス)と「どこにあるか」(位置)の問題に分解し、それぞれに対応する学習と予測を行うのが2段階物体検出モデルの特徴です。
R-CNN、Fast R-CNN、Faster R-CNNは、この2段階物体検出モデルの流れを採用しつつ、それぞれに独自の工夫を加えて性能の向上を図ったモデルです。
R-CNN (Regions with CNN features)
R-CNNは2013年に提案された初の2段階物体検出モデルです。当時はまだAlexNetがILSVRCで活躍してまもなく、CNNの普及期でした。R-CNNも名前の通りCNNを用いて特徴抽出を行う点が画期的でした。ILSVRCについては以下を参照ください。

R-CNNのアーキテクチャは以下の通りです。
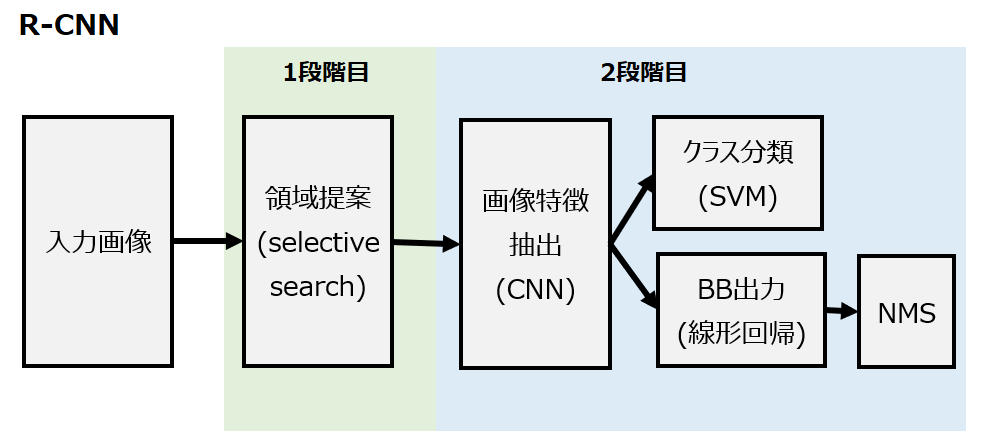
これを手順で示すと以下のようになります。
- Selective searchによる領域の提案
- 各領域提案にCNNを適用して特徴マップを抽出
- SVMを使って各領域提案を特定のクラスに分類
- 線形回帰を用いて、各領域提案のBBを予測
- 予測BBにNMSを適用して、重複や冗長なボックスを排除
第一段階でSelective Searchという手法を用いて物体候補領域を生成します。Selective Searchはピクセル単位で色やテクスチャ、サイズなど様々な尺度と類似性を用いて画像を細かな領域に分割し、それらを組み合わせて物体の候補領域を約2千個選出します。この候補領域は単なる位置情報ではなく元画像から切り出した長方形の画像2千個であり、画像内で物体が存在しそうな領域を切り出した画像です。
第二段階ではCNNを通じて2千個すべての候補領域から特徴を抽出します。領域提案はサイズもアスペクト比(縦横比)もバラバラですが、ここではそれらを固定サイズ(例:224×224)にリサイズしてからCNNに入力します。そしてそれぞれSVMを使ってクラス分類し、かつ線形回帰を使ってBB(バウンディングボックス)を出力します。その後、BBの数が多すぎるので、NMSを使って無駄なボックスを排除しています。
このプロセスを見てもらえればわかる通り、R-CNNは計算コストが非常に高いです。それを今後のFast R-CNNやFasterR-CNNが解決していきます。
原著論文は以下です。

CNN、SVM、線形回帰、NMSについては以下を参照ください。

Fast R-CNN
Fast R-CNNは2015年に提案されました。上述の通りR-CNNは物体候補領域すべてに対してCNNを通過させるため、計算が重複し、処理速度が遅いという問題が生じました。そこでFast R-CNNでは、画像全体を一度だけCNNに通すことで特徴マップを作成し、その上に物体候補領域を投影するという手法を採用し、処理速度を高速化しました。また、クラス予測とバウンディングボックスの位置調整を一つのネットワークで同時に行うように改良されました。
アーキテクチャは以下の通りです。

これを手順で示すと以下のようになります。
- Selective searchによる領域の提案
- 画像全体にCNNを適用して特徴マップを生成
- 領域提案(RoI)を特徴マップに射影
- RoIプーリング
- 全結合でクラスとBBをそれぞれ予測
Fast R-CNNでは、まず全体の画像をCNNに入力します。これにより画像全体に対する特徴マップが得られます。Selective Seachによる領域提案はR-CNNと同じです。
Fast R-CNNではその後、領域提案をこの特徴マップ上にマッピング(位置を合わせる)します。このマッピングは例えば、画像が1000×1000ピクセルで、特徴マップが10×10、領域提案が元画像で「左上から100ピクセル下、100ピクセル右の位置から200×200ピクセルの領域」を指定しているとします。この場合では、この領域提案を特徴マップ上で「1,1から2,2の位置」にマッピングします。(綺麗にマッピングできない場合(小数点)はROIプーリング時に切り捨て)
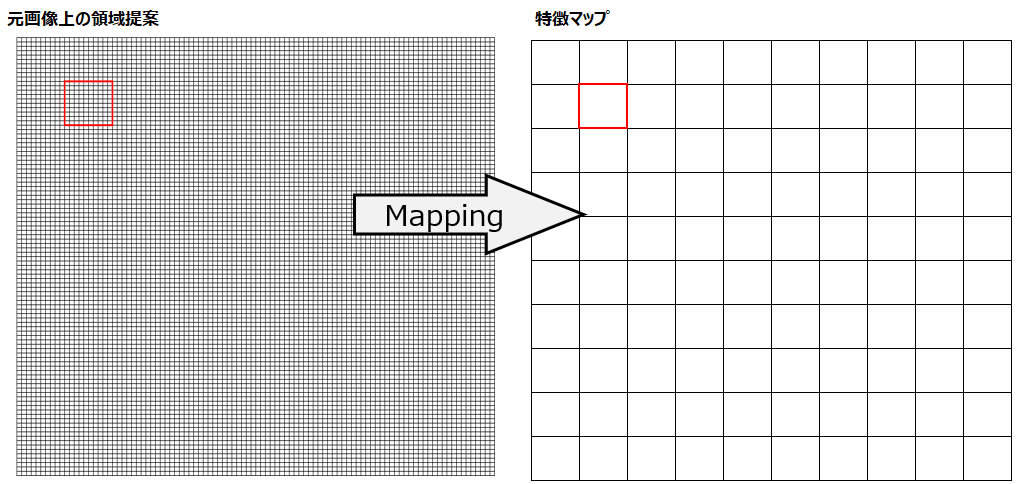
また、最終的に予測クラスとBBを出力する全結合層に入力しますが、全結合層に入力するには予め決められた固定のサイズ(例えば7×7)である必要があります。固定サイズにするための処理がROIプーリングです。
ここで問題となるのが、領域提案は画像の中で異なる位置とサイズ、形状を持つため、それぞれに対応した特徴マップもサイズと形状が異なるということです。しかし、最終的に予測クラスとBBを出力する全結合層に入力するためには、一定のサイズにする必要があります。
この問題を解決するために、Fast R-CNNではROI Poolingという手法を導入しました。ROI Poolingは、領域提案ごとの特徴マップを、決められたサイズ(例えば7×7)に変換します。これは、領域提案を等分し、各分割領域の最大値(Max Pooling)を取ることで行われます。その結果、どのようなサイズと形状の領域提案であっても、一定のサイズの出力を得ることができます。
以下は、8×8の特徴マップに射影された5×7の候補領域を2×2の固定サイズにリサイズする様子です。
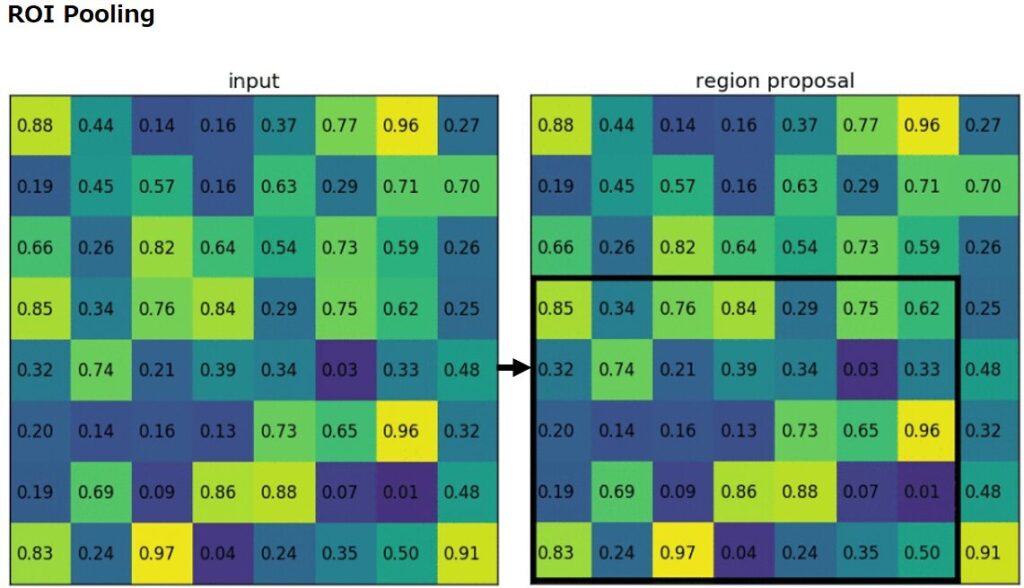
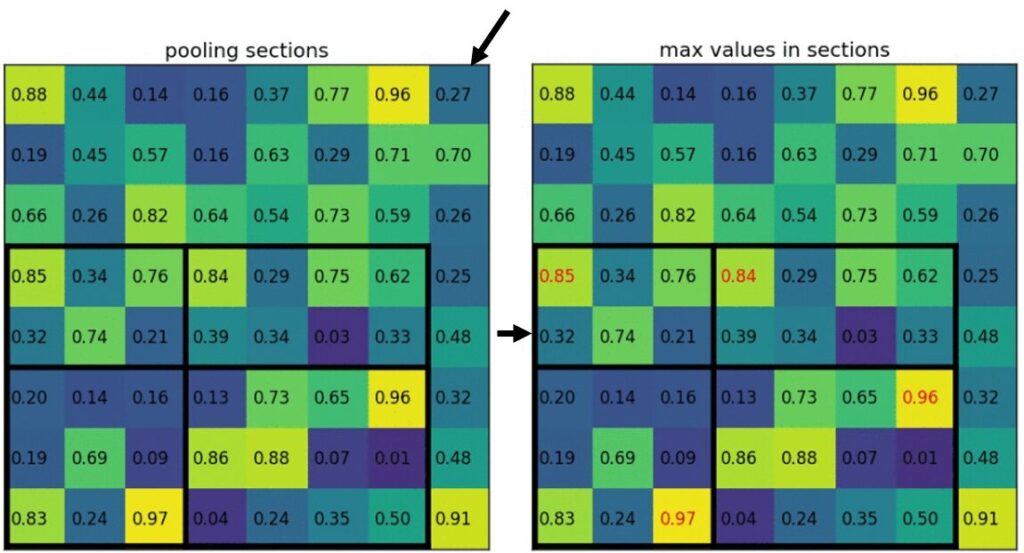
出展:https://github.com/deepsense-ai/roi-pooling
纏めると、Fast R-CNNはR-CNNと比較して、すべての候補領域に対して予測するのではなく、得られた特徴マップから各候補領域に該当する部分を特定して予測することで高速化しました。ただし、Selective Searchは継続使用しているので、その点はなお課題として残ります。
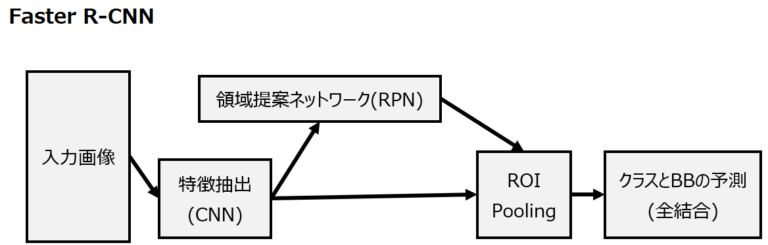
Faster R-CNN
Fast R-CNNでも物体候補領域を生成するSelective Searchがボトルネックとなっていました。同じく2015年に提案されたFaster R-CNNの主な進歩は、物体候補領域を生成する手法をSelective SearchからRegion Proposal Network (RPN)に変更したことです。RPNは全畳み込みのネットワークであり、特徴マップ上でスライドウィンドウを適用することで物体の存在と位置を効率的に予測します。

これを手順で示すと以下のようになります。
- 画像全体にCNNを適用して特徴マップを生成。
- Selective searchではなく領域提案ネットワーク(Region Proposal Network, RPN)を用いて領域提案(RoI)を生成
-以降はFast R-CNNと同じ– - 領域提案(RoI)を特徴マップに射影
- RoIプーリング
- 全結合でクラスとBBをそれぞれ予測
Faster R-CNNのポイントは領域提案ネットワーク(RPN, Region Proposal Network)です。R-CNN/Fast R-CNNで採用されていたSelective Searchは、ピクセル単位で色やテクスチャ、サイズなど様々な尺度と類似性を用いて画像を細かな領域に分割し、それらを組み合わせて物体の候補領域を約2千個選出します。この作業を毎回実行しないといけないことが。一方RPNでは、まずアンカーボックスを既定の数生成し、各アンカーボックスの中に物体が存在する確率を計算するCNNを構築します。学習が完了していればここで効率的に物体が存在しているアンカーボックスだけを絞り込むことができると同時に、特徴マップを特徴抽出のCNNとRPNで共有しているため、それも高速化に寄与しています。


コメント