
今回は、物体検出モデルの中でも1段階検出器の代表的な存在であるSSD(Single Shot MultiBox Detector) を解説します。
なお、物体検出の全体像は以下を参照ください。

SSD(Single Shot MultiBox Detector)とは何か
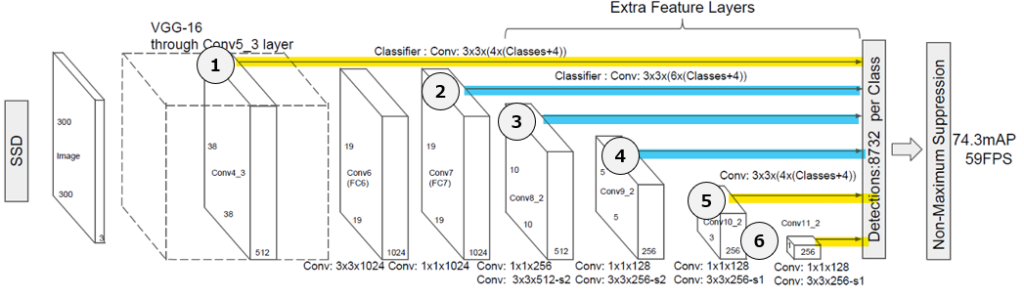
SSD(Single Shot MultiBox Detector)は名前の通り1段階検出器です。同じく1段階検出器として有名なモデルにはYOLO(You Only Look Once)があります。分割したグリッド単位でしか予測ができないYOLOとは異なり、SSDは後述の通りグリッド分割が多様であり、デフォルトボックスを使って様々なサイズとアスペクト比の物体を検出できるようになります。また、一つの位置で複数の物体を検出することも可能なため、小さな物体や密集した物体の検出にも強いです。ただし、複数のスケールで推論を行うため、YOLOより計算コストが高いです。SSDの元論文に掲載されているSSDのアーキテクチャです。
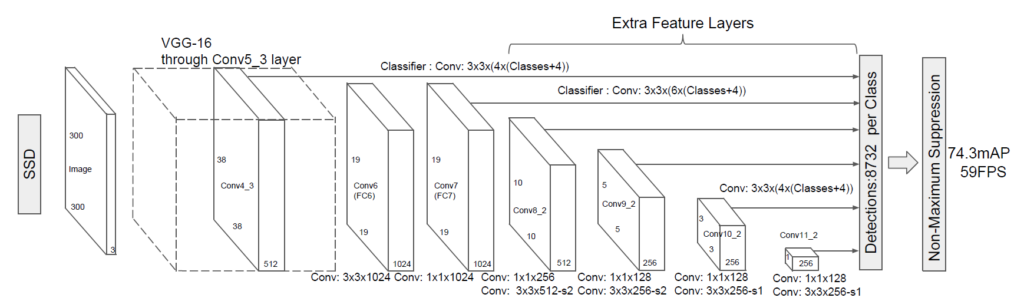
SSDのアルゴリズムは以下の通りです。
- 入力画像の準備: 入力画像を固定のサイズにリサイズ(YOLOと同様)
- 特徴抽出: 入力画像はCNN(通常VGG16)を通じて処理され、特徴マップが生成される
- 複数のスケールでの予測: SSDでは、CNNの複数の層の特徴マップを用いて、各特徴マップに対して”デフォルトボックス”または”アンカーボックス”と呼ばれるバウンディングボックスを設定する。これらのボックスは、各特徴マップの各位置で異なるアスペクト比(例えば1:1、1:2、2:1など)とスケール(例えば特徴マップの)を持つものとします。
- 予測: 各デフォルトボックスに対して、物体の存在確信度とクラス確率、そしてボックスのオフセット(デフォルトボックスから物体の真の位置までの相対的なシフト)を予測します。
- NMSとHNM: 最後に、重複した検出を削除するために、非最大抑制(NMS)が適用されます。
SSDの最大の特徴はCNNの複数の層の特徴マップを用いて各特徴マップに対して”デフォルトボックス”(アンカーボックス)を用意するということですが、これがなかなかイメージしにくいので、以下では詳しく解説します。なおSSDではVGGという有名かつシンプルで強力なCNNのモデルに、”Extra Feature Layers”を追加して用いています。VGGについては以下を参照ください。

なぜ複数の層の特徴マップを使うのか
まずなぜCNNの複数の層の特徴マップを使うのでしょうか。この理由としてよく“各特徴マップは1つの解像度しか持たないから”と説明されますが、これではよくわかりませんね。
CNNの畳み込みの記事で解説したように、特徴マップとは、CNNに入力したときの中間層で得られるデータで、入力画像から重要な特徴を抽出し、それらを表現したものです。
特徴マップが”1つの解像度しか持たない”というのは、それぞれの特徴マップが異なるスケールで特徴を捉えるという意味です。たとえば、”高解像度”(下図の40×40グリッド)の特徴マップは、小さな物体や細部の特徴を捉えるのに適していますが、大きな全体的な特徴を理解するのは難しいかもしれません。一方である特徴マップが”低解像度”(下図の5×5グリッド)であれば、それは大きな物体や背景のような広範な特徴を捉えるのに適していますが、小さな物体や細部の情報を把握するのは難しいかもしれません。
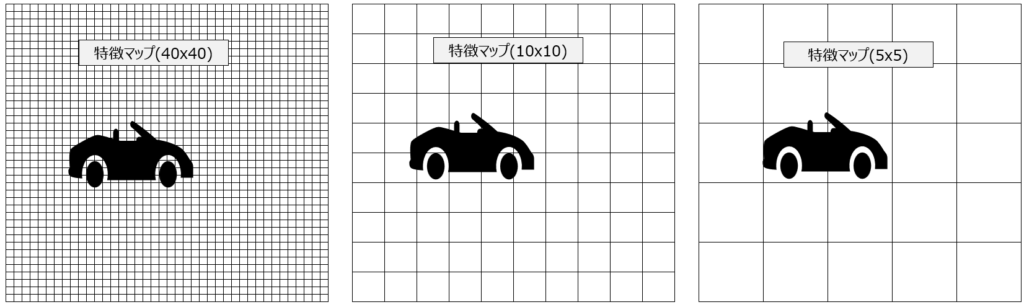
より具体的には、上図では、40×40の特徴マップでは車の細かな部品や傷を見るのには適していますが、車全体の情報はわかりません。10×10のマップは、タイヤくらいの大きさの物体の特徴を捉えられそうですね。そして5×5の特徴マップは車体の全体的な特徴(フィルム、オープンカー、乗車している人)を掴めるかもしれません。
これが、複数の層の特徴マップを使うことで複数の解像度で物体検出を可能にするということです。
デフォルトボックスの生成
次に、具体的にデフォルトボックスがどのように生成されるのか見ていきましょう。
黄色部分では、VGGの畳み込み層の途中(10/16層目に該当)の部分で、38×38の大きさの特徴マップを使って、デフォルトボックスを作成しています。
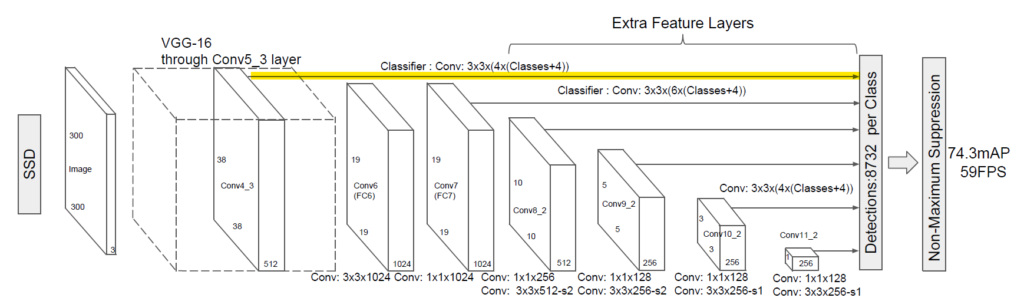
やや表記がわかりにくいですが、例えば10クラス分類するタスクであれば、この黄色部分だけで38 x 38 x 4 x (10+4)=80,864個のデフォルトボックスを作成します。各セル(38×38)に対して、アスペクト比(縦横比、1:2,1:1など)の異なるものを含む4つのボックスを作成します。この”4つ”は恐らく4つで試したら性能が良かった、程度の理由と思います(後述の部分では6つ作成されている)。以下の図は、あるセルに6つのデフォルトボックスを作成している図例です。
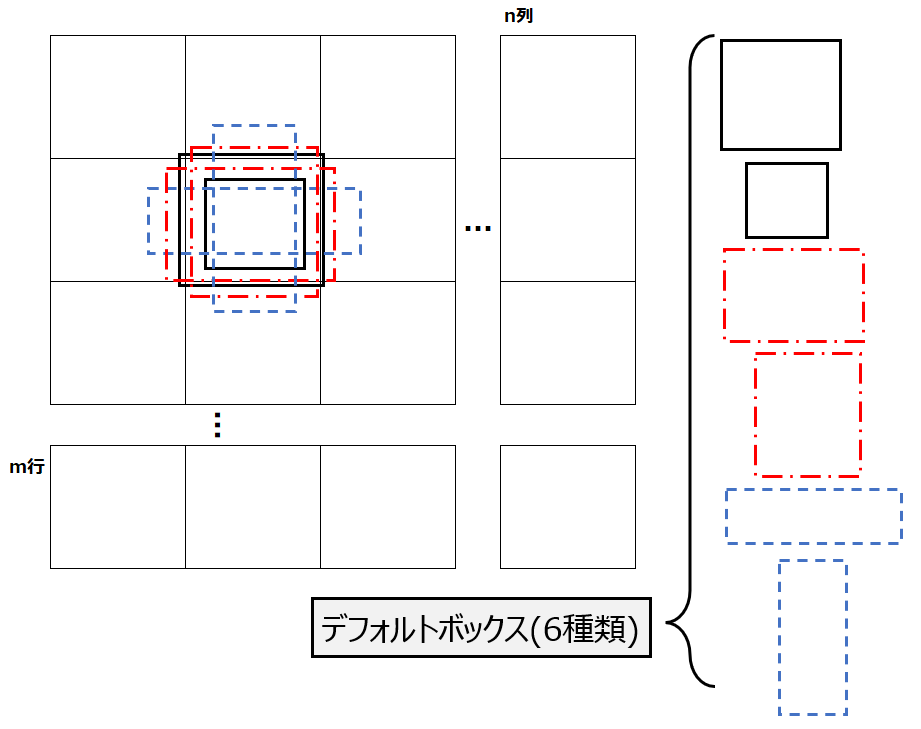
以上で、デフォルトボックス生成の38 x 38 x 4 x (10+4)のうち、”38 x 38 x 4″の部分はわかりました。次に(10 + 4)の部分を見てみます。”10″は上述の通りクラス分類数で、4はオフセット項と呼ばれます。これは、デフォルトボックスを出力する前に、適切な形にボックスの位置をずらす(オフセットする)ので、それをどのようにずらしたかを記録する値です。
なぜオフセットする必要があるのかを説明します。上では38×38というサイズの特徴マップを使ってデフォルトボックスを作成しました。これを例えば正解画像の検出したい物体のバウンディングボックス(Ground Truth BB)と比較した時、以下のような位置関係にあったとします。デフォルトボックスはある種、適当に設定したボックスなので、Ground Truth BBとはやや位置がずれています。下の例では冗長である(無駄なエリアが多い)ので、その部分をオフセットするには、以下のような作業が必要です。
- x,y: ボックス中心位置をやや左に(Δx)かつ下(Δy)に移動
- w,h: ボックスのサイズをやや狭く(Δw)かつ低く(Δh)変更
これらx,y,w,hという観点でどのようにオフセットしたか、というデータも、デフォルトボックスとともに出力されるのです。これでようやく、38 x 38 x 4 x (10+4)=80,864個というデフォルトボックスの数が何を指すのかがわかりました。言語化すると以下の通りです。
特徴マップの縦 x 横 x デフォルトボックス数(4or6) x (クラス数 + オフセット項)
残りの部分も同じ計算で、デフォルトボックスがどのように何個生成されるかを計算可能です。以下の黄色部分はデフォルトボックス4個、青は6個です。
クラス数をCのままとすると以下のように全体の計算を表現できます。
① 38 x 38 x 4 x (C + 4) + ② 19 x 19 x 6 x (C + 4) + ③ 10 x 10 x 6 x (C + 4) + ④ 5 x 5 x 6 x (C + 4) + ⑤ 3 x 3 x 4 x (C + 4) + ⑥ 1 x 1 x 4 x (C + 4)
纏めると、8,732 x (C+4)となります。クラス数が10であれば、合計122,248個ものデフォルトボックスが生成されることがわかります。
HNM(Hard Negative Mining)
最後に、プロセスの5.NMSとHNMのうち、HNMについて解説します。NMSは物体検出の全体像の記事を参照ください。
物体検出系のタスクにおいては、大抵のケースで背景、つまりターゲットの物体が1つも存在しない領域が多く存在していますが、それらを“ネガティブ”サンプルと呼びます。しかし、ネガティブサンプルを積極的に学習に利用する、背景のデータが圧倒的に多くなり、訓練が不均衡になる可能性があります。これは、モデルが背景をうまく検知するように過学習し、重要なポジティブサンプル(物体)を見逃す可能性があるからです。
そこで、Hard Negative Miningでは、間違って物体と判断されやすいネガティブサンプル(Hard negative)を特定し、これらを積極的に学習に使用します。これは例えば学習段階初期のネットワークにおいて背景(Negative)であるのに物体(Positive)と検出されている、つまり予測が間違っているデータから選ばれたりします。
HNMによって、ネガティブサンプルとポジティブサンプルの数はバランスが良くなります。例えば1000個のネガティブサンプル(背景)と50個のポジティブサンプル(物体)があるとします。NMSを適用して1000個のネガティブサンプルのうち、最も「難しい」100個のサンプルを選び出すことで、Nagtive:Positive = 2:1となり、データの不均衡が緩和され、物体と背景の識別がより難しいケースに対するモデルの性能が向上します。
なおこの技術は、以下の記事でアンカーフリーの手法として紹介したFCOSでも取り入れられています。


コメント