
今回は第2次AIブームについて詳しく解説します。
第2次AIブーム (知識の時代)
1970年代には米英でAIの研究資金供給が打ち切りになるなど、第1次AIブーム終焉後の“AIの冬第1期”に突入していました。人工知能の歴史の概観と第1次AIブームについては以下をご参照ください。


その後、70年代後半から80年代に第2次AIブームが到来します。第2次AIブームで中心的な役割を果たしたのは、知識表現の研究とエキスパートシステム、そして第5世代コンピュータです。
知識表現
知識表現というのは、人間の知識をAIが理解できるように記述する手法のことです。
人口無能
チャットボットのように、真に会話の内容を理解しているわけではなく、既定のルール・手順に従って処理するコンピュータプログラムのことを人口無能と呼びます。
ELIZA
人口無能の起源となったのが、MITのワイゼンバウムが1966年に開発したELISAです。ELIZAは、初期の自然言語処理プログラムです。ワイゼンバウムは、一部のユーザーがELIZAが会話を理解できているわけではないことを理解せずにELIZAとの会話にのめり込んでしまう(イライザ効果)など反響の大きさに衝撃を受け、1979年にはコンピュータを万能と信じている人々に警鐘を鳴らす著書”Computer Power and Human Reason: From Judgment to Calculation”を書いています。
このELIZAは、チューリングテストの合格を1つの目標として開発したことでも知られています。チューリングテストについては以下の記事を参照ください。

エキスパートシステム
エキスパートシステムとは、専門分野の知識を取り込むことで、専門家のようにふるまうプログラムです。1970年代に開発され、80年代には商用適用されるようになりました。代表例としてはMYCIN,DENDRALが上げられます。
Dendral
Dendralは1965年にスタンフォード大学で開始された人工知能のプロジェクト、及びファイゲンバウムが開発したエキスパートシステムの名称です。名前の由来はDendritic Algorithm(樹枝状アルゴリズム)です。
Dendralは、未知の有機化合物を質量分析にかけ、化学の知識ベースを使ってその化合物を特定するエキスパートシステムです。知識ベースというのは、コンピュータで検索できるように知識を組織化し・集合させたデータベースのことです。
ファイゲンバウムは1977年に知識工学を提唱しました。知識工学では汎用性の高い理論の構築よりも、エキスパートシステムを使って現実の問題を解決することが目指されます。
Mycin
Mycin(マイシン)は、1970年代にスタンフォード大学で開発されたエキスパートシステムで、Dendralを大幅に修正したプログラムです。名前の由来は多くの抗生物質で末尾に”-mycin”がついていることによります(日本語で”~マイシン”)。
Mycinは緑膿菌など伝染性の血液疾患の診断支援プログラムです。Yes/Noの質問とIf Then文によるルールベースがあらかじめ用意されていて、患者からの情報入力により適切な抗生物質を処方する、というものです。
Mycinの精度は69%で、これは専門医の診断精度80%を鑑みても良い結果でしたが、実現場でMycinは使われませんでした。これは性能の面よりもむしろ、誤診の責任を誰がどのように取ればいいのか、という問題によります。
エキスパートシステムの限界
知識ベースを構築するためには、専門家の暗黙知を組織化したり、情報量が増えた時に知識ベース内での整合性を保つ必要があり、これがとても難しい作業でした。そのためにインタビューシステムや意味ネットワーク、オントロジーの研究が進んでいく契機となりました。
意味ネットワーク
意味ネットワークというのは、人間の意味記憶の構造のモデルです。意味記憶というのは、短期記憶の対概念である長期記憶の1種です。長期記憶には大きく言語化可能な陳述記憶と言語化不可能な非陳述記憶があり、陳述記憶には意味記憶(犬は動物、牛乳は飲み物、など)、エピソード記憶(息子が公園で転んだ)、非陳述記憶には手続き記憶(自転車の乗り方)等の種類があります。
意味ネットワークでは、概念と概念の間の意味関係が線で結ばれて表現されます。主要な関係として、”属性(part-of)“と”継承関係(is-a)“が挙げられます。属性というのは例外を除いて共通して備わっている特徴のことです。人間は共通して”目”を持っていて、鯨は共通してヒレを持っています。継承関係というのは、原則的に下位概念が上位概念の属性をすべて引き継ぐような関係性のことです。哺乳類の属性としては乳房、体毛、横隔膜、心臓、血液などがあります。哺乳類の下位概念である人間は、これらの特徴をすべて引き継いでいます。哺乳類は、動物の属性である”多細胞の真核生物”や”従属栄養生物”、”運動性”などをすべて引き継いでいます。
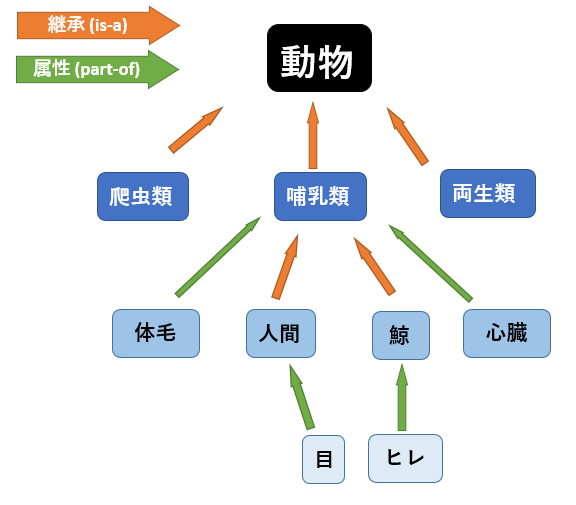
この時継承関係(is-a)においては、推移律が成立します。推移律というのは人間が哺乳類であり、哺乳類が動物であるならば、人間は動物であるという類の論理関係です。
オントロジー
オントロジー(Ontology)の説明は非常に難しいですが、誤解を恐れずに簡単に言ってしまえば“知識のネットワークを構築するためのフレームワーク”であると言えるでしょう。我々の世界を記述するために、共通のルールや考え方を提供することが目的です。より簡単に言ってしまえば、知識を記述する際のマニュアル(仕様書)でしょうか。
詳しくは以下の記事を参照ください。

第5世代コンピュータ
第5世代コンピュータ(FGCS:Fifth Generation Computing System)とは、バブル真っ盛りの1982年から92年の間に、500億円をかけて現在の経産省中心に進められた日本の国家プロジェクトです。それまではアメリカなどがAI研究の中心であったこともあり、世界から注目されました。
人間の脳と同じように並列処理を適用することで言葉の理解を達成することを目指しましたが、結局このプロジェクトは目ぼしい成果を上げることのないまま、終了してしまいます。
なお第5世代の意味は”人工知能対応”であり、第1世代の真空管、第2世代のトランジスタ、第3世代の集積回路、第4世代の大規模集積回路に続くものとして定義されています。
第2次AIブームの終焉
知識獲得のボトルネック
第2次AIブーム終焉の理由の1つは”知識獲得のボトルネック“と呼ばれます。オントロジーの項目を読んでみてもらえればわかる通り、エキスパートシステム構築は非常に大きな労力を要します。
知識獲得のボトルネックの例としてよく出されるのが、以下の英文の自動翻訳です。
He saw a woman in the garden with a telescope.
この英文は意味を1つに絞ることができない文章です。in the gardenが修飾するのはHeなのかWomanなのか、また望遠鏡を持っているのがHe なのかWomanなのか、わかりません。この文章は、ほとんどの人が”彼は望遠鏡で庭にいる女性を見た”と訳すそうですが、それを自動翻訳に反映するには、辞書的な知識だけでなく広範な常識があって初めて可能となります。このような知識獲得のボトルネックが突破されるには、ディープラーニングを使用したニューラル機械学習を待たなくてはなりませんでした。ニューラル機械翻訳を使ったGoogle翻訳が発表されたのが2016年であることからも想像される通り、2000年代には再びAI冬の時代が訪れることになります。


コメント