
今回は、機械学習の予測精度を高くするために使われるアンサンブル学習について解説します。
アンサンブル学習とは何か
アンサンブル学習(Ensemble Learning)とは、複数の学習器(モデル)によってそれぞれ学習をした後で、それらを統合的に用いることで精度を高める手法のことです。機械学習の有名なアルゴリズムの中では、ランダムフォレストがアンサンブル学習(バギング)を用いています。バギング以外にも組み合わせ方には様々種類があるので、後述します。
メリットとデメリット
アンサンブル学習のメリットは、単体のモデルで過学習が発生している時に精度を向上させられることです。一方デメリットは、複雑なモデルを組み合わせるほど処理に時間がかかることです。
バイアスとバリアンス
アンサンブル学習を理解するうえで重要な概念として、バイアスとバリアンスがあります。これらは2つとも、予測精度を評価するための考え方です。
バイアス(偏り)は予測値と正解値の差、バリアンス(分散)は予測値のばらつき具合です。バイアスとバリアンスは以下のような図を用いて説明されることが多いので、今回も以下の図を用います。
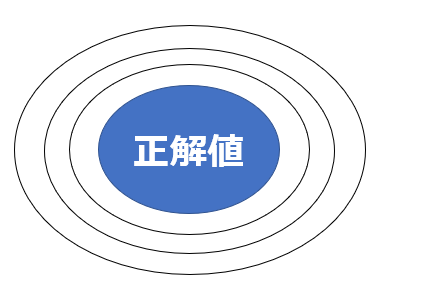
以下の黒い点はモデルによる予測値を示します。この黒い点が青い円の”正解値”の範疇に入っていればそのモデルの精度が高いと考えてください。以下が最も望ましい状態です。

バイアスが高い、則ち予測値と正解値の差が大きいというのは、以下のような状態です。
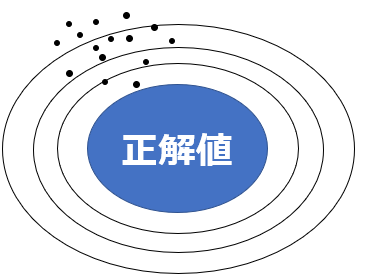
バイアスが高いときは、そもそも学習データの説明変数と目的変数の規則性を適切に学習できていない、学習不足である可能性が示唆されます。
バリアンスが高い、則ちばらつきが大きいというのは、以下のような状態です。
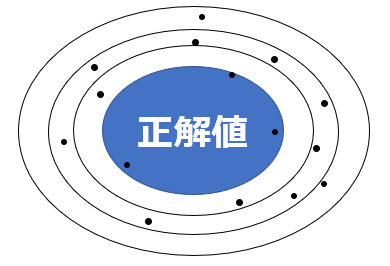
バリアンスが高いときは、過学習が示唆されます。過学習については以下の記事を参照ください。

バイアスとバリアンスはトレードオフの関係にある為、どちらかを極端に追及すると、もう一方は悪化します。アンサンブル学習によるモデル構築をするときは、このバイアスとバリアンスが最適なバランスになる様にモデルを調整していきます。
バギング
バギング(Bagging)の”Bag”は”Bootstrap Aggregating”の略で、ランダムフォレストなどに用いられているアンサンブル学習の代表的な手法です。バギングの説明をするのに、以下のようなデータ集合を想定します。
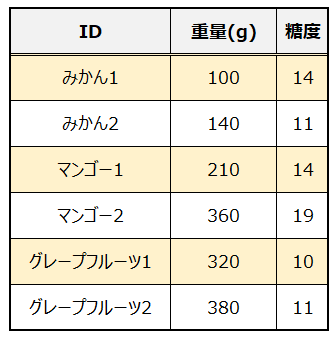
みかん・マンゴー・グレープフルーツが各2個ずつあり、それぞれの重量と糖度のデータがあります。重量と糖度を説明変数とし、果物の種類を目的変数とするも予測モデルを作成し、重量と糖度からどの果物なのかを予測できるようにします。このデータからバギングの手法を用いて予測モデルを構築する流れを、以下の図で表しています。
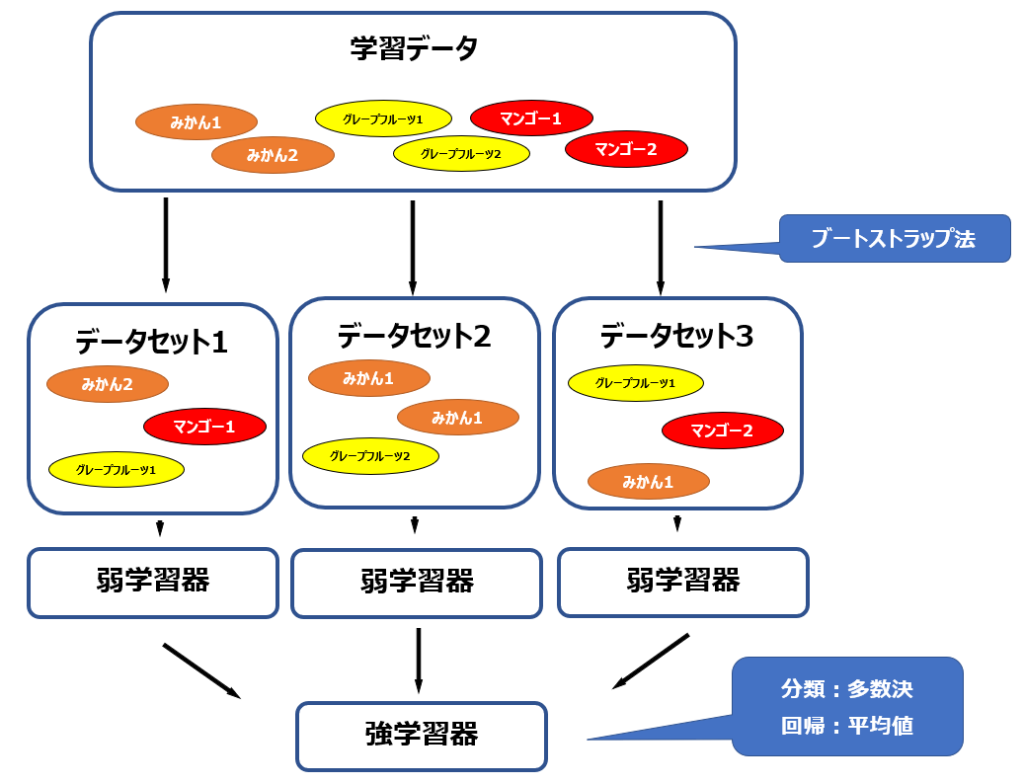
詳細は後述しますが、概略としてはデータ集合からブートストラップ法を使ってデータセットを複数用意し、それぞれのデータセットに対して予め設定しておいた弱学習器と呼ばれる、単体では精度が不十分なモデルを適用して学習を行います。最後に弱学習器による結果を多数決もしくは平均値を取る形で最終的なモデル(強学習器)を構築します。
ブートストラップ法
バギングはその名(Bootstrap Aggregating)の通り、ブートストラップという手法を用います。ブートストラップ法というのは、復元抽出法によってランダムにデータを抽出して作成したデータセットを基に学習や分析を進める手法です。このランダムにサンプリングした部分集合のことをブートストラップと呼びます。
復元抽出法というのは一言でいうと重複してもよい抽出のことで、くじ引きでいうと一度引いたくじを箱の中に戻してから次のくじ引きをすることです。1人が同じくじを何度も引く可能性もありますし、最初に引いた人と次に引いた人が同じくじを引く可能性もあるということになります。
復元抽出法を用いているため、上の図”みかん1″のように同じデータセット内に同じサンプルが複数存在していたり、他のデータセットにも”みかん1″が存在しえるのです。
弱学習器
弱学習器は、単体では精度の低い単純なモデルで、バイアスが高く、バリアンスが低くなる傾向にあります。弱学習器の具体例としては、ランダムフォレストや勾配ブースティングで用いられる決定木がよく使われます。
強学習器
弱学習器は単体では精度が高くありませんが、複数の弱学習器を統合したり足し合わせたりすることで、精度の高い予測モデルを構築することができます。このモデルを強学習器を呼びます。
ブースティング
ブースティング(Boosting)というのは、逐次的に学習を進める手法です。逐次的というのは、バギングのように複数の学習器を並列的に学習していって最後に統合するのではなく、前の学習器の結果に基づいて更に次の学習器を構築するような、直列的な学習方法です。
以下では、ブースティングの中でもとりわけ重要なAdaBoostと勾配ブースティングを紹介します。
AdaBoost(アダブースト)
AdaBoostでは、1つ手前の学習器で予測がうまくいかなかったデータに対して大きな重みを与えた(ミスを強調した)データ集合を用意して学習器を構築します。さらに次の学習器でも、1つ手前の学習器でのミスを強調したデータを基に学習器を構築します。そうして構築された複数の学習器の予測値を足し合わせていって、最終的な予測値を算出するという手法です。
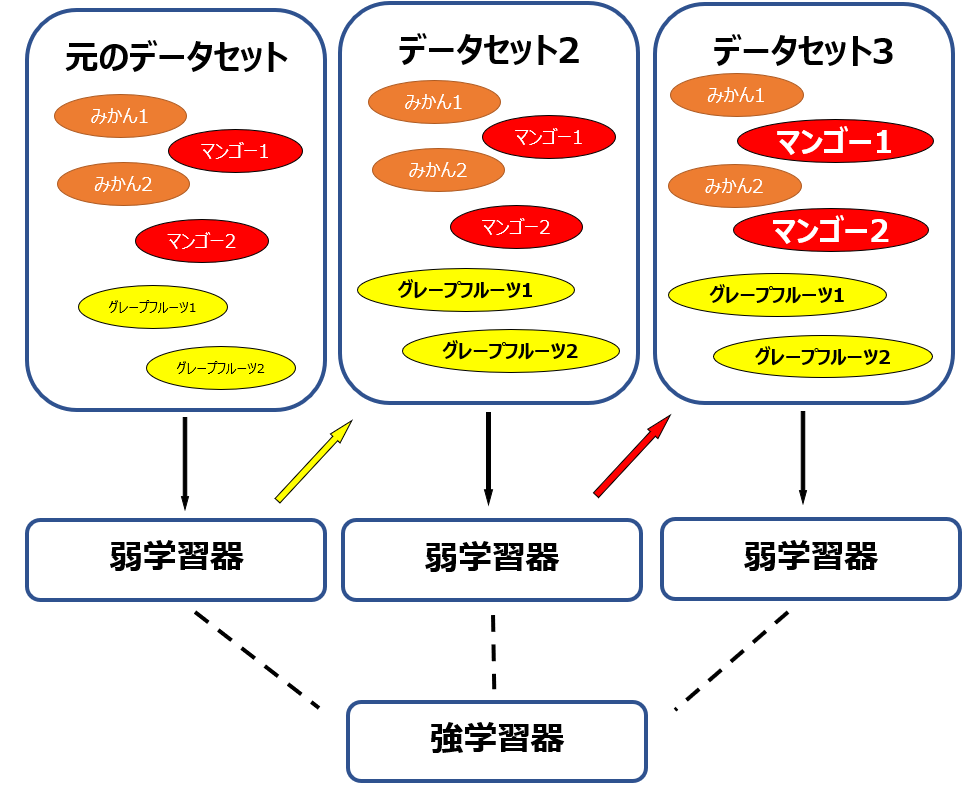
上の図例では、最初の学習器ではグレープフルーツの予測がうまくいかなかったので、グレープフルーツに重みづけをした上で次の学習器を構築。次はマンゴーに重みづけをして学習器を構築。3つの学習器を合わせて最終的な学習器を構築するという図式になっています。
勾配ブースティング
AdaBoostの場合は予測を誤ったデータに重みをつけることで精度を高めたのに対し、勾配ブースティングは予測値と正解値の差(残差)を修正するような弱学習器を作っていきます。勾配ブースティングの中でもよく使われるアルゴリズムとしてXGBoostが挙げられます。以下では決定木を使った勾配ブースティングのイメージを説明しますので、決定木については以下を参照ください。
以下では、重量と糖度を説明変数、みかん・マンゴー・グレープフルーツの果物名を目的変数とした多値分類問題を想定しています。まず学習用データを元に決定木による予測モデルを構築したとします。
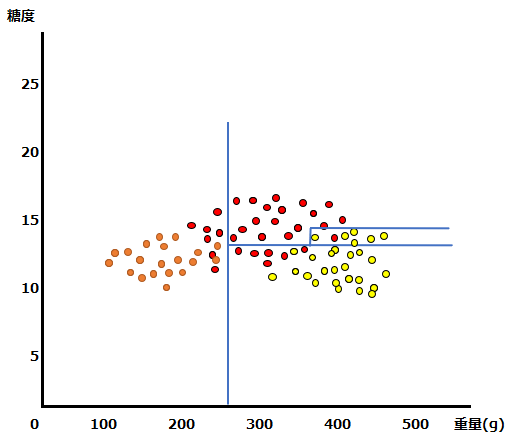
以下の青い線が決定木の予測モデルによる予測線、点は正解値です。オレンジ色がみかん、赤色がマンゴー、黄色がグレープフルーツです。
大まかには分類ができていますが、精度が高いとは言えません。この時予測が当たらなかった正解値と予測線との距離のデータを使って、元の予測モデルに修正を加えます。以下、修正のイメージです。
マンゴーのほとんどが分類されていたクラスに含まれていたグレープフルーツが分離されました。

更に、みかんとマンゴーの混在部分を修正されています。
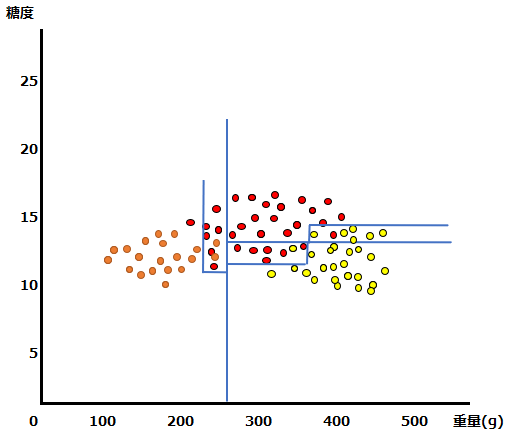
最終的には、非常に精度の高い予測モデルを構築することができました。
その他のアンサンブル学習
上記以外のアンサンブル学習としては、スタッキングやバンピングが挙げられます。
スタッキング(Stacking)
スタッキングはバギングの応用と考えられます。バギングではデータセットごとの単純平均や多数決で結論を出しましたが、それぞれのデータセットを平等に評価するのでは、外れ値の有無などそれぞれのモデルの重要性を考慮できていないという問題点があります。スタッキングでは、個々の予測値の単純平均ではなく、重みによって加重平均したものを最終的な予測値とすることで、重要性も反映させる手法を取っています。
バンピング(Bunping)
バギングやスタッキングが複数の弱学習器を組み合わせてその平均や多数決によって予測値を出しましたが、バンピングは複数の弱学習器から1つの最も当てはまりの良いモデルを選ぶ手法です。バンピングのメリットとしては、外れ値などを多く含んだ質の悪いデータを含んだデータセットを使った弱学習器の影響を無視することができる点が挙げられます。


コメント