
前回までCNNについて説明してきました。今回から物体検出、セマンティックセグメンテーション、インスタンスセグメンテーションについて説明します。

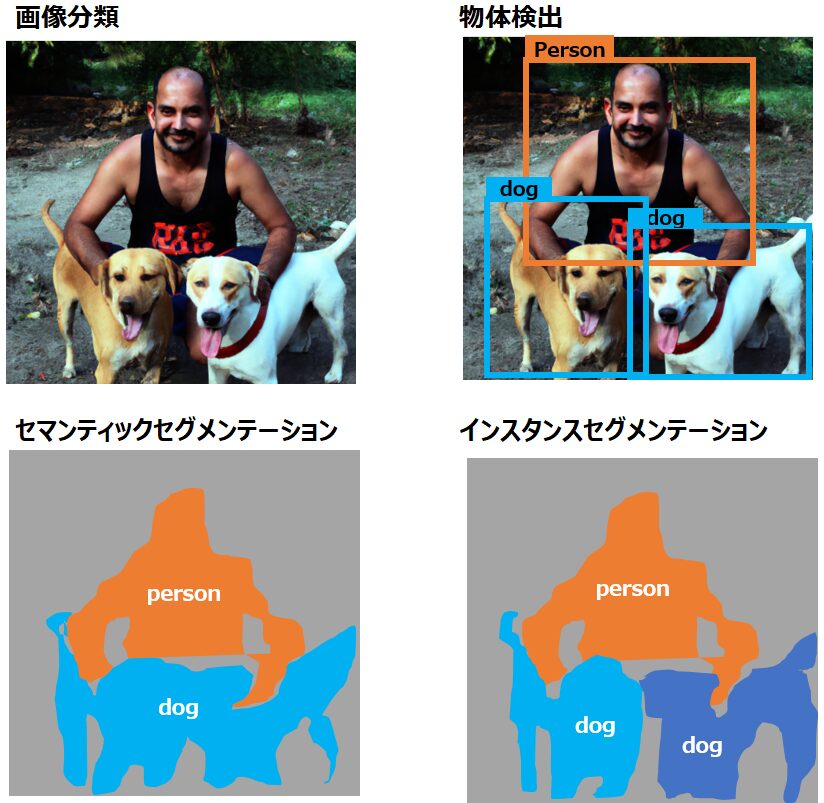
画像分類・物体検出・セグメンテーションの違いは何か?
物体検出、セマンティックセグメンテーション、インスタンスセグメンテーションはいずれも、前回までのCNNを核とした手法です。前回までは画像分類タスクを念頭にCNNがいかにして画像の特徴を抽出するのかを説明しましたが、今回紹介するこれらのタスクでは、CNNが抽出した特徴を用いて、各画像中のどこに特定の物体が存在するのかを判断する役割を果たしています。
詳解は追って説明しますが、それぞれのタスクの違いは以下の通りです。
- 画像分類タスク:画像全体が何を表現しているかを予測します(例:この画像=犬)
- 物体検出タスク:画像中に存在する各物体の位置をバウンディングボックス(BB=長方形のボックス)で指定し、その物体の種類を特定します(例:犬のボックス2つと人間のボックス1つ)
- セマンティックセグメンテーションタスク:画像中に何の種類の物体が含まれるかをピクセル単位で特定します。この時、同じ種類の物体が重なっていても区別しません(例:犬と人間が含まれ、他は背景)
- インスタンスセグメンテーションタスク:セマンティックセグメンテーションの一歩進んだもので、同じ種類の物体でも個々に区別します(例:犬が2つと人間が1つ含まれ、他は背景)
以下、詳細を説明します。
物体検出モデル
物体検出モデル(Object Detection Model)は、画像の中から特定の物体を見つけ出し、その位置と大きさを特定します。
画像分類と物体検出の違い
改めて画像分類との違いを確認しましょう。画像分類は、1枚の画像に対してそれが”犬”なのか、”猫”なのかといった、画像とクラスが1対1となります。一方物体検出は、ある画像に”犬”や”猫”が存在しているかどうかわからず、また存在している場合も、”犬”と”猫”が両方とも存在していたり、複数存在している場合はそれぞれ認識することもあります。

社会実装例
物体検出技術は、リアルタイム性を要求されるかどうかで社会実装のされ方が変わります。リアルタイム性が求められる利用例としては、自動運転車や防犯カメラが挙げられます。自動運転車は道路上の他の車、人、自転車など、あらゆる種類の物体をリアルタイムで検出し、その位置を正確に把握する必要がありますし、監視カメラでは盗難や不審行為を瞬時に検出したり、特定の人物を追跡したりする際に利用されます。
リアルタイム性が要求されないケースとしては、工場での不良品検知によく使われます。不良品は不良の種類それぞれの特徴を学習し、単にある画像が”不良品”であるという画像分類ではなく、どの場所にどの種類の不良(薬品の包装不良、半導体の欠損やハンダ不良、野菜の形状不良など)があるということを検出することができます。
Single-shotとMulti-shot
物体検出技術には主に”Single Shot“と”Multi Shot“の2つの手法が存在します。Single Shotアプローチは画像を一度だけ見て物体の位置とクラスを同時に予測するもので、高速な処理が可能です。社会実装例でみたように、リアルタイム性が要求される場合はこちらが適しています。一方、Multi Shotアプローチは画像から物体の候補領域を抽出(元画像のどこを見たらよいかという提案ボックスがたくさん出現)した後、その領域を別途評価して物体の位置とクラスを予測します。この手法は処理に時間がかかるものの、精度が高いという特性があります。
Multi Shotアプローチの代表的なモデルとしては、R-CNN(Regions with Convolutional Neural Networks)やその改良版のFast R-CNNとFaster R-CNNが挙げられます。Single Shotアプローチの代表的なモデルとしては、SSD(Single Shot MultiBox Detector)やYOLO(You Only Look Once)があります。これらの詳細は今後の記事で紹介します。
FCOS
FCOS(Fully Convolutional One-Stage Object Detection)は2019年に発表された新しい物体検出手法の一つで、一般的な二段階の検出手法やアンカーベースの一段階の手法とは異なり、全畳み込みネットワークを使用し、アンカーフリー(アンカーボックスを必要としない)で物体検出を行う手法です。
物体検出手法は大きく二段階の手法(例:Faster R-CNN)と一段階の手法(例:YOLO、SSD)に分けられます。二段階の手法は領域提案とその領域の分類を別々に行います。一方、一段階の手法は物体の位置とクラスを同時に予測します。一般的には、二段階の手法は精度が高い反面、計算量が大きいという特徴があります。逆に、一段階の手法は速度が速い反面、精度が若干低い傾向があります。
多くの一段階の手法(YOLOやSSDなど)は、アンカーボックスという事前に定義した形状のボックスを使用して物体の位置を予測します。しかし、アンカーボックスを適切に設定するのは難しく、また、アンカーボックスに依存すると多様な形状の物体の検出が難しくなるという問題があります。
こうした問題に対処するために開発されたのが、アンカーフリーの手法であるFCOSです。FCOSは全畳み込みネットワーク(Fully Convolutional Network)を使用して、特徴マップ上の各位置で物体の中心点を予測し、同時にその物体のサイズとクラスも予測します。これにより、アンカーボックスを必要とせずに一段階で物体検出を行うことができます。これにより、形状や大きさが異なる多様な物体に対しても高精度な検出を行うことが可能です。
セマンティックセグメンテーションモデル
セマンティックセグメンテーションモデル(Semantic Segmentation Model)は、画像中に何の種類の物体が含まれるかをピクセル単位で特定する技術で、物体検出よりも画像をより詳細に理解することができます。
“Semantic”は「意味論的」という意味の言葉で、言葉や記号などが持つ意味や関連性を研究する学問領域から来ています。セマンティックセグメンテーションの文脈では、画像の各ピクセルにおける”意味”が”物の種類”や”カテゴリー”として現れるものとして扱っています。言い換えるとセマンティックセグメンテーションは、画像内の各ピクセルが何を表しているのか、つまりどの種類の物体に該当するのかという「意味」を把握するために用いられます。
社会実装例
セマンティックセグメンテーションが活躍している分野の1つは医療画像です。MRIやCT画像から病変部を正確に切り出すことで、医師が診断を下しやすくなるのです。また、農業分野でも利用されています。ドローンが高解像度の農地の画像を撮影し、セマンティックセグメンテーションを用いて各種の作物や土地の状態を詳細に分析することができます。
モデルの紹介
セマンティックセグメンテーションの代表的なモデルとしては、”FCN(Fully Convolutional Network)”、”U-Net“、”SegNet“などがあります。これらはいずれもEnd-to-Endモデルで、1つのモデルで入力から出力までを直接生成することができます。これらの登場以前にもセマンティックセグメンテーションモデルは存在しましたが、中間ステップが必要で効率が悪いという問題がありましたので、ここではFCN以降に限定して紹介します。
FCNは2014年に提案された最初のEnd-to-Endセマンティックセグメンテーションモデルで、画像全体を畳み込み処理し、その後、Up Samplingして元のサイズに戻すというプロセスを行います。U-NetとSegNetはFCNの進化系です。U-Netは2015年に医療用に使うことを目指して発表され、SegNetは2016年に発表され、FCNよりも詳細なセグメンテーションを可能にしています。それぞれ詳細は今後解説しますが、以下にそれぞれの元論文から画像を引用します。

インスタンスセグメンテーションモデル
インスタンスセグメンテーションモデル(Instance Segmentation Model)は、セマンティックセグメンテーションをさらに進めた技術です。”Instance”とは「事例」や「実例」といった意味がありますが、ここでは”個別の実体”を意味します。つまり、インスタンスセグメンテーションとは「個々の物体を個別の実体として認識するセグメンテーション」のことを指します。セマンティックセグメンテーションでは物体の種類が同じ場合は同じカテゴリーとしてセグメンテーションしますが、インスタンスセグメンテーションの場合は同じカテゴリーの物体であっても別々の物体として識別します。そのため、冒頭で示したように、同じ”犬”というカテゴリーに属する2つの物体をそれぞれ別のものとしてセグメンテーションできるのです。
詳しくは今後詳細記事を掲載しますので、お待ちください。
NMS(非最大抑制)
物体検出・セグメンテーションではモデルごとに様々なアルゴリズムの工夫がなされていますが、その中でも多くのモデルで採用有れているのがNMS(Non Maximum Supression、非最大抑制)です。
物体検出において、しばしば同じ物体に対して膨大な数のBB(バウンディングボックス)が提案されます。これらBBの多くでは領域が重複しており、冗長です。具体的には以下の左のように、同じ物体をいくつものBBが違う形とサイズで検出しています。
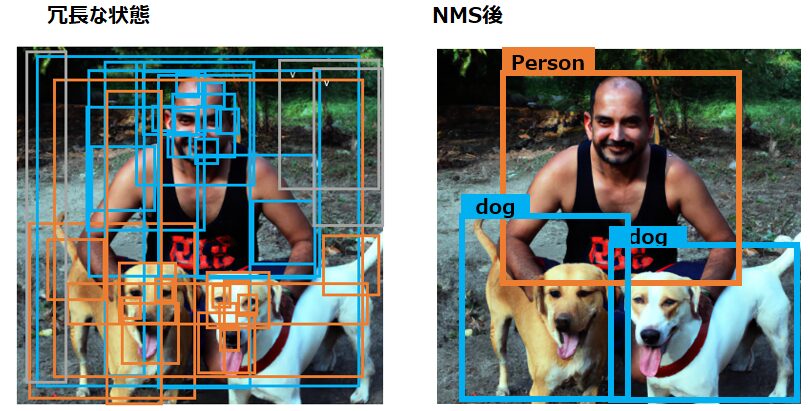
NMSは、それぞれの物体(クラス)に対して、信頼度スコアが最大のBBを選び、その他の重複したBBは抑制(削除)します。
物体検出の評価指標
物体検出タスクでよく使われる評価指標としては、IoU、再現率と適合率、mAP、Dice係数などが挙げられます。次回の記事で詳しく解説しますので、少々お待ちください。


コメント