今回は、機械学習の中の強化学習ついて解説します。強化学習は、教師あり学習、教師なし学習と並ぶ機械学習の手法の1つです。機械学習の概要や基本的な用語の説明については以下の記事を参照ください。

強化学習とは何か
強化学習というのは、ある行動の結果として状態が改善していたらより高い報酬を与えて学習していくような手法です。犬の躾けがイメージしやすいかもしれません。言いつけを守れたら(行動・状態)餌を与え(報酬)、守れなかったら与えないということを繰り返して躾け(学習)ます。
教師あり学習・教師なし学習との違い
このプロセスからわかる通り、強化学習は他の機械学習の手法である教師あり学習や教師なし学習よりも、人間が環境に適応したりスキルを習得するプロセスに近しいと言えるかもしれません。例えば、自転車に乗る時に”正解”を教えられてそれをもとに訓練した人は少ないのではないでしょうか。
料理を例に、それぞれの機械学習の手法を比較してい見ます。教師あり学習は、レシピが与えられていて、その通りに作れるようになることと言えます。教師なし学習は、とりあえず具材が与えられ、何かを作ってみた結果、その料理に名前を後からつけることもできる、というものと言えます。
一方強化学習は、具材や調理器具(環境)が予め決められたうえで、試行錯誤を重ね(行動)、その都度料理(状態)をチェックしてその美味しさ(報酬)を基に最適な調理方法(方策)を探していくようなものと言えます。()内のワードについては以下で詳述します。
強化学習の対象タスク
教師あり学習との比較から、強化学習はわかりにくいという印象を受けるかもしれませんが、しかし実際には、教師あり学習では扱えないような複雑なタスクも扱えるということだとも言えます。
教師あり学習の代表例としては、例えばある画像が犬か猫かを答える、ある単語の次に続く単語を予測する、といったものがあります。一方強化学習が得意とするのは、完了までに多くのステップを要するタスクや、目標達成の方法がたくさん存在するようなケース、目標達成の条件が複雑なケース、更には目標達成の基準が曖昧なケースです。
例えば強化学習のタスクとして有名な囲碁や将棋のようなゲームでは、プレイヤーが取るべき最善の手を見つけるために、多くのステップ先を見越した戦略が必要です。これらのゲームには、膨大な数の可能な盤面と手の選択肢があり、それぞれの手が最終的な勝敗に与える影響を事前に完全に予測することは難しく、更にゲームをクリアするためのプロセスや方法、条件が複雑に存在しています。
自動運転車やロボットの自律移動では、環境が常に変化する中で、安全かつ効率的に目的地に到達するための判断が求められます。これには、歩行者や他の車両の動き、道路状況、信号など多くの要素が関与し、それぞれがリアルタイムで変化します。
こういった、従来の機械学習では扱えないような人間の複雑なタスクにも適応できるのが、強化学習なのです。
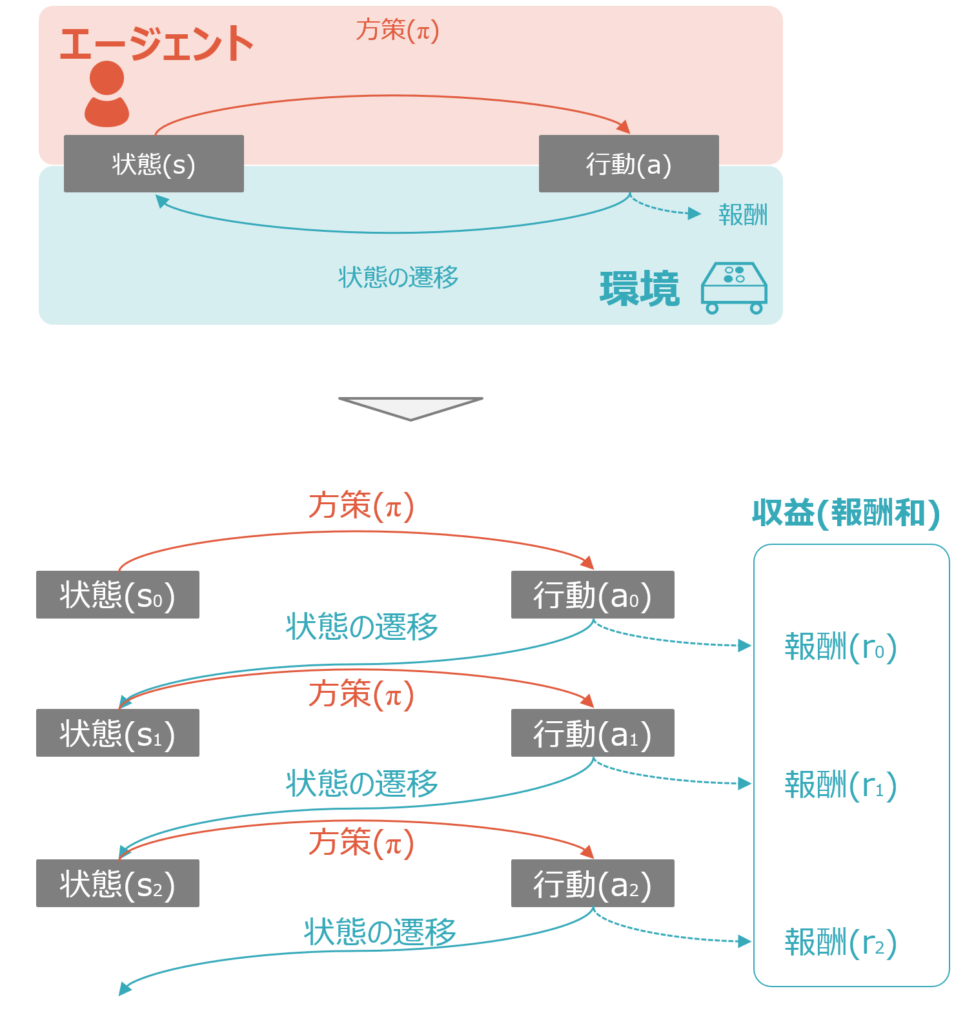
強化学習の基本構造
強化学習の基本構造は、環境・エージェント・行動・方策・状態・報酬という6つのキーワードを使って説明されます。以下が概略図です。
強化学習では、最適な方策を設定し、状態に応じた行動を選択することで報酬を獲得します。この獲得できる報酬の和を最大化することが、強化学習の目的となります。詳細は以下を参照ください。
関連事項
他、関連事項についての記事については、以下を参照ください。掲載し次第追加していきます。
MDP(マルコフ決定プロセス)
今後紹介する強化学習の価値関数やモデルでは、環境にマルコフ性を仮定しています。
割引率γ
強化学習が目指しているのは、将来的に得られる報酬の合計が最大になるような行動を選ぶことです。しかし、将来の報酬をすべて等しく評価してしまうとうまくいかないケースもあり、そのため割引率γがハイパーパラメータとして設定されます。
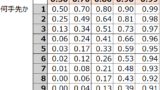
価値関数
強化学習の目標は報酬を最大化することですが、それを達成するための手段の一つが価値関数です。望ましい状態や行動を価値が高いと評価することで、結果的に報酬を最大化することが狙いです。

ベルマン方程式
ベルマン方程式によって、今の状態で取り得るすべての行動aと、その行動によって移行する次の状態 s′の価値 V(s′)がわかれば、今の状態の価値V(s)がわかる、ということが理解できます。

コメント