強化学習では最適な方策を設定することで獲得できる報酬を最大化するように学習が進みます。学習を進める際には、γ(ガンマ)という記号で表される割引率というハイパーパラメータを設定する必要があります。今回はこの割引率γについて説明します。
なおハイパーパラメータというのは、機械ではなく人間が手動で任意に設定する必要のあるパラメータです。このハイパーパラメータである割引率を調整することで、学習の結果も変わってきます。
割引率の一般的な意味
割引率は、将来獲得できる報酬をどのくらい現在の価値に含むかという指標です。強化学習でのみ出てくる用語でなはなく、経済学や資産運用の世界でも頻繁に出てくる用語です。
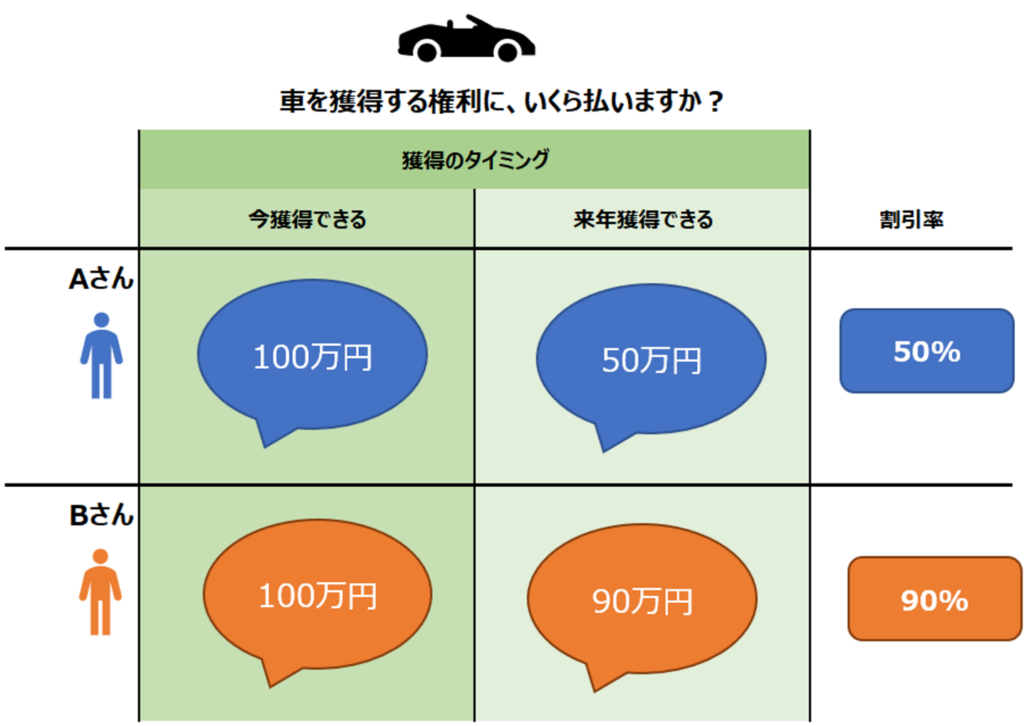
割引率という概念は、利子などの概念を知っていればより理解しやすいかもしれませんが、そうでない場合はイメージし難いと思います。直感的に理解するために、今100万円で自動車を獲得できるときに、来年同じ自動車を獲得できる権利にいくら払えますか?という問いについて考えてみます。
今自動車を獲得するのが大事なのであって、来年獲得することに価値を感じないAさんは、来年の自動車には50万円ほどの価値しか感じないかもしれません。一方で別に自動車を獲得するのは来年でもいいと感じるBさんであれば、来年獲得できる自動車にも90万円ほどの価値を感じるかもしれません。
Aさんにとって、今の100万円と来年の50万円は同じ価値であると考えると、割引率は50%となります。一方Bさんにとっては今の100万円と来年の90万円が同じ価値となり、割引率は90%となります。これが割引率です。
強化学習における割引率
強化学習における割引率γも、同じような考え方です。割引率は0~1の間で設定されます。ただし注意が必要なのは、1が全く割り引かない、0が最も割り引くという性質だという点です。割引率という名前から”どれだけたくさん割り引くか”の値だと誤解を招くかもしれませんが、実態としては”どれだけ割り引かずに将来の報酬を評価するか“というパラメータになっています。また冒頭でハイパーパラメータと紹介した通り、これは計算されるものではなく、人間が手で設定する値となります。
例えば割引率γ=0.9としましょう。この意味は、1つ先の行動による見込み報酬を0.9倍で評価し、2つ先の見込み報酬は(0.9×0.9=0.81)倍で評価し、3つ先の見込み報酬は(0.9×0.9×0.9=0.73)倍で評価する、ということです。直感的に理解するなら、割引率が低いほど、遥か先の報酬よりも、目先の報酬を優先するということになります。
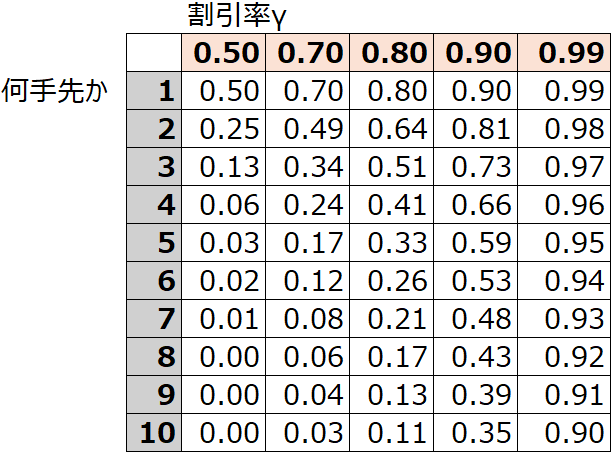
さらに具体例を出してみましょう。割引率を仮に0.5~0.99で設定した時に、1手先から10手先までで、報酬がどのように評価されるかを表にしています。割引率を0.5にすると、2手先くらいまでしか評価されにくい一方、割引率を0.99とすると10手先もしっかり評価されることがわかります。
強化学習が目指しているのは、将来的に得られる報酬の合計が最大になるような行動を選ぶことです。しかし、将来の報酬をすべて等しく評価してしまうと、特にシミュレーションが無限に続くような場合、報酬の合計が際限なく大きくなってしまう可能性があります。これを防ぐために、「割引率」という考え方を使います。
割引率は、時間が経つにつれて将来の報酬の価値を徐々に低く評価する仕組みです。これにより、今すぐ得られる報酬をより高く評価し、遠い将来の報酬はそれほど重要視しないようになります。遠い将来の報酬を大きく評価すると何が問題なのでしょうか。ボードゲームやスポーツであれば無限に続くことは想定しにくいですし、最終的に勝つかどうかがむしろ重要なので割引率は高く設定したいですが、例えば動画のレコメンドなどで考えると、初期は全くユーザーに刺さらないが1年後にユーザーがたくさん視聴してくれるようなレコメンドが評価されてしまうことになります(最終的な合計が大きければいい、となってしまう)。タスクによっては、敢えて近い将来までだけを評価してアルゴリズムを構築したいケースがあるのです。そういったケースでは、割引率を適切に設定する必要があります。

コメント