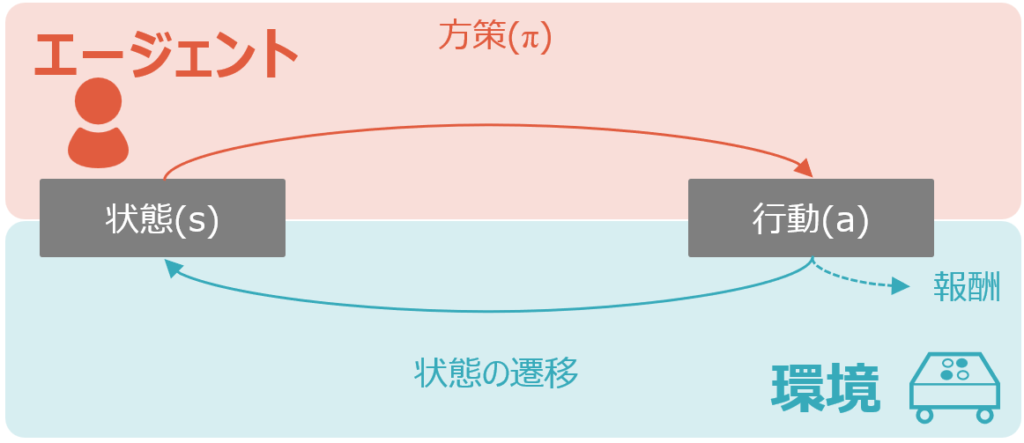
今回は、強化学習の基本構造を解説します。今回は、強化学習の基本構造を解説します。全体像の概略図は以下の通りです。
強化学習のわかりにくさ
詳細の説明に入る前に、強化学習がなぜわかりにくいかを説明します。
1つの原因は、用語の相互の関係のわかりにくさが挙げられます。エージェントが環境内で行動し、報酬を得て学習するというサイクルは、経験や知識がないと実際にどう進むのかがイメージしづらいです。
また強化学習は、時間の経過とともに学習が進むプロセスであるため、”現在の行動が将来の報酬にどう影響するか”といった時間的な依存関係が絡んできます。これが、よく出てくる図ではわかりにくく、理解を妨げる原因となります。
以下の説明では、これらのわかりにくさをできるだけ克服することに勤めます。
強化学習の基本用語
冒頭の図を再掲します。
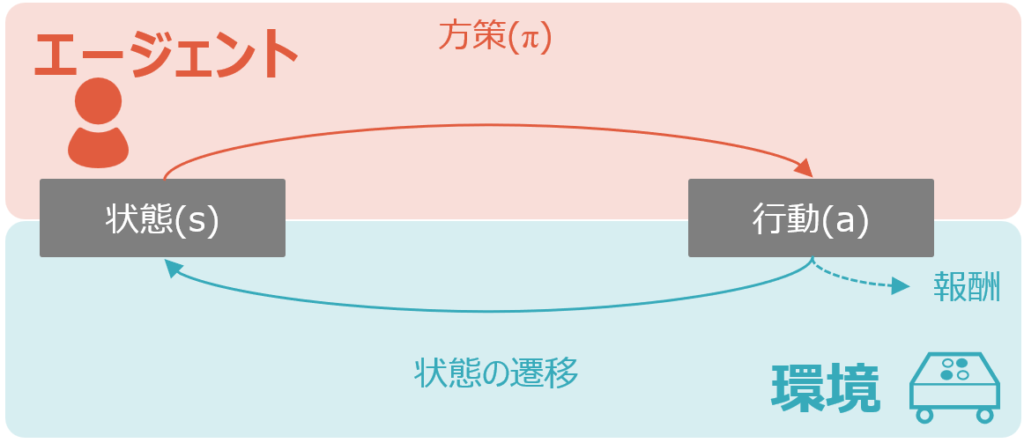
まずは、基本構造を理解するために基本用語を説明します。
エージェント
エージェントは、学習を行う主体、つまり”行動する存在”です。強化学習のAIプログラムであり、自動運転の車事態であり、ゲームのキャラクターなどを指します。
状態(s, status)
状態は、エージェントが現在置かれている環境の状況を示します。エージェントはこの状態を基に、後述の”行動”を選択するので、非常に重要な概念です。
状態の具体例としては、ボードゲームの盤面、ゲーム内でのプレイヤーの位置・ライフポイント・敵の位置・持っているアイテムなど、 ロボットの現在の座標・周囲の障害物の位置・目標地点までの距離などがイメージしやすいでしょう。
行動(a, action)
行動は、エージェントがある”状態”で取る具体的なアクションです。重要なのは、エージェントがこの”行動”を実行することで、次の状態に遷移する点です。
自動運転で考えれば、ある道を走っていて交差点に差し掛かった際に(=当初の状態)、右折・左折・直進など行動することで状態が遷移します。
方策(π, policy)
方策(Policy)とは、“エージェント“が特定の”状態“においてどの”行動“を選択すべきかを決定するためのルールや戦略のことです。方策は、エージェントの行動方針を具体的に示すもので、入力として現在の状態を受け取り、その状態に基づいて最適な行動を出力します。
例えば将棋において、”状態”が中盤で自分の飛車が相手の角を狙える位置にあり、相手の玉が囲いの中にいるという内容だった時に、「飛車で角を取る」「飛車で玉に王手をかける」「飛車を温存しつつ別の駒を動かして相手の玉を追い詰める」といった複数の行動を評価し、方策に基づいて最も有利な手を選択します。
この方策がイメージし難いですが、必ず初めから決まっているわけではなく、最初はランダムに設定され、その結果を評価して2回目以降の方策が決められたりします。
なお、方策をpではなくπ(パイ)とするのは、恐らく確率をpとするので、区別するためかと推測されます。
環境(MDP)
続いて、環境です。これも非常にわかりにくい概念です。環境についてよく見る説明は、”エージェントが相互作用する世界や状況を指します。エージェントが行動を取ると、その行動に応じた結果が環境から返されます。”といった内容ですが、これだけではよくわからないので、もう少し具体的に考えてみましょう。
エージェントとの相互作用とは何か。エージェント側は、ある状態において方策に基づいて行動を選択します。これがエージェントから環境への作用です。例えば将棋で飛車を動かしたり、生肉をフライパンで焼く、サッカーでシュートを打つといったことです。
一方環境側は、“エージェント“の”行動“の結果を受けて“状態”の遷移と”報酬“を発生させます。報酬の詳細は後述します。状態の遷移というのは、例えば将棋でどちらかのプライヤーが優勢になったり、肉をグリルしてメイラード反応が起きたり、サッカーで点が入ることです。報酬については、ボードゲームは通常ゲームが終わるまで特典が入らないのでわかりにくいですが、肉がおいしい状態に近づいたらプラス、サッカーで得点したらプラス1点、といったことをイメージしてください。
なお、この環境はマルコフ性を満たしている場合には、MDP(マルコフ決定プロセス)となります。MDPについては今後の記事で説明します。
報酬(r, reward)
報酬とは、“エージェント“がある”行動“を取った結果として”環境“から受け取るフィードバックのことです。報酬は、エージェントがその行動が良かったか悪かったかを評価するための基準となります。たとえば、ゲームのAIが正しい手を打って勝利に近づけばプラスの報酬を得ますが、逆にミスをして不利になればマイナスの報酬を受け取ります。エージェントは、この報酬を基にどの行動が最適かを学習し、将来の行動選択を改善していきます。報酬が多く得られる行動を優先するように学習することで、最適な戦略を見つけることが目的です。
なお、ある行動に対するフィードバックが報酬(r)ですが、これらの報酬和のことを収益(return)と呼びます。頭文字が両方ともrですが、報酬和である収益の記載方法については、収益の方を大文字Rとしたり、慣習的にG(恐らくgain)と記します。
強化学習の目的
強化学習では上述のように、最適な方策を設定し、状態に応じた行動を選択することで報酬rを獲得し、その和を収益(G)とします。この獲得できるGを最大化することが、強化学習の目的となります。
強化学習の基本構造
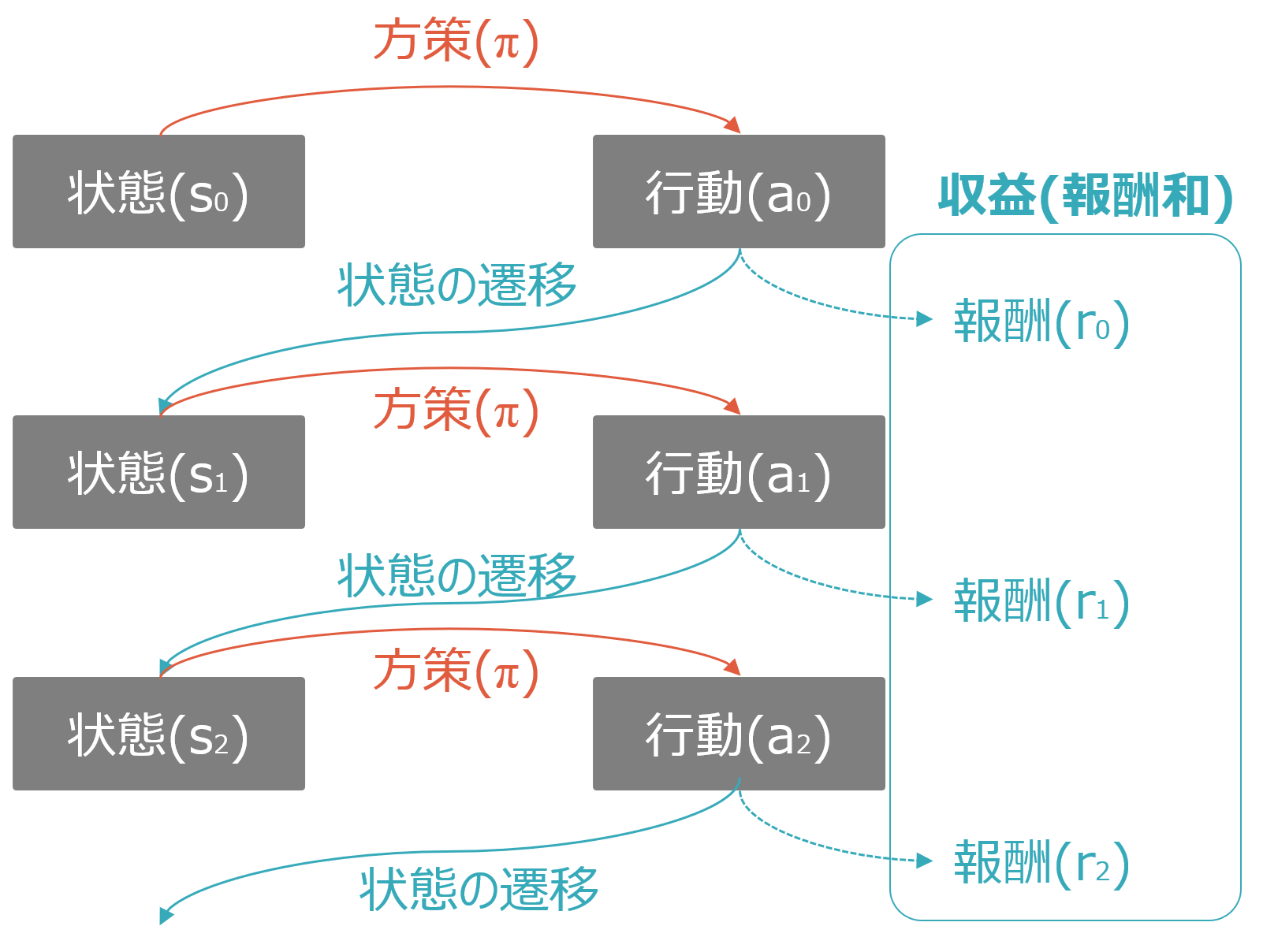
ここで、もう1度冒頭の図を再掲します。
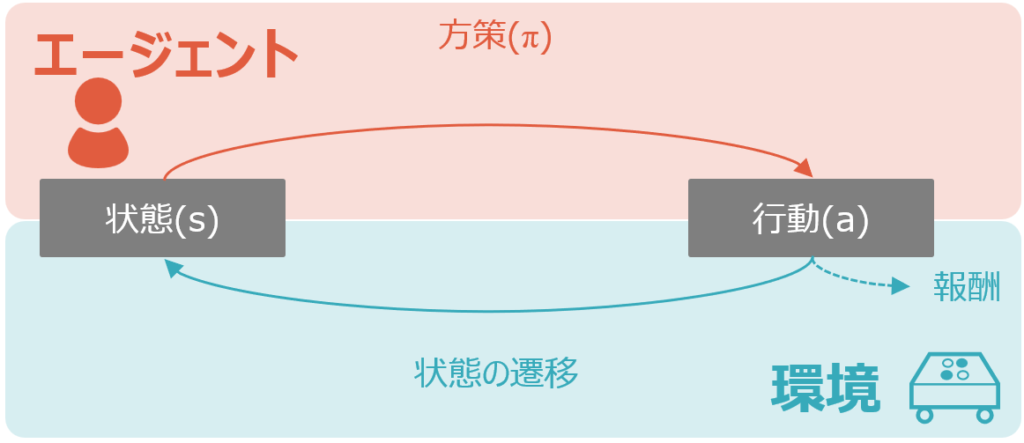
この図から、エージェントと環境の役割が違うことはわかりますが、何度も繰り返される相互作用のプロセスがわかりにくいです。そのため、以下ではこれらを時系列ごとにバラシた図を掲載します。
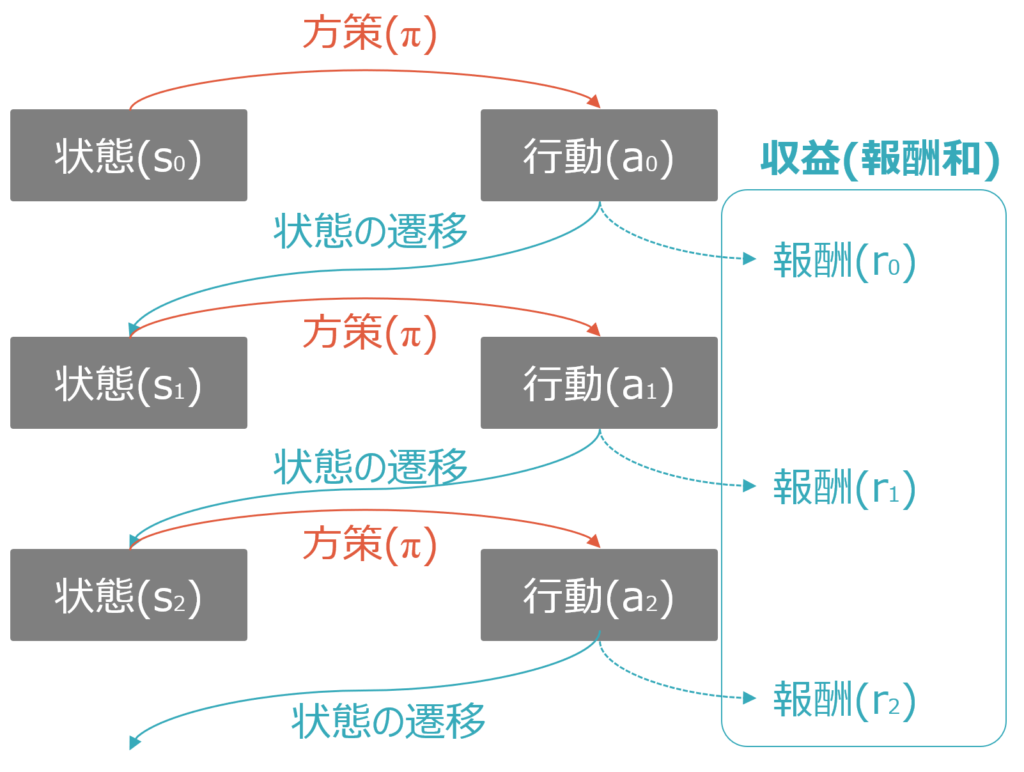
順に説明します。
まず以下のように初期状態(s0)があります。これは囲碁であれば石が置いていない状態、将棋であれば初期配置、スポーツであればゲーム開始時点です。
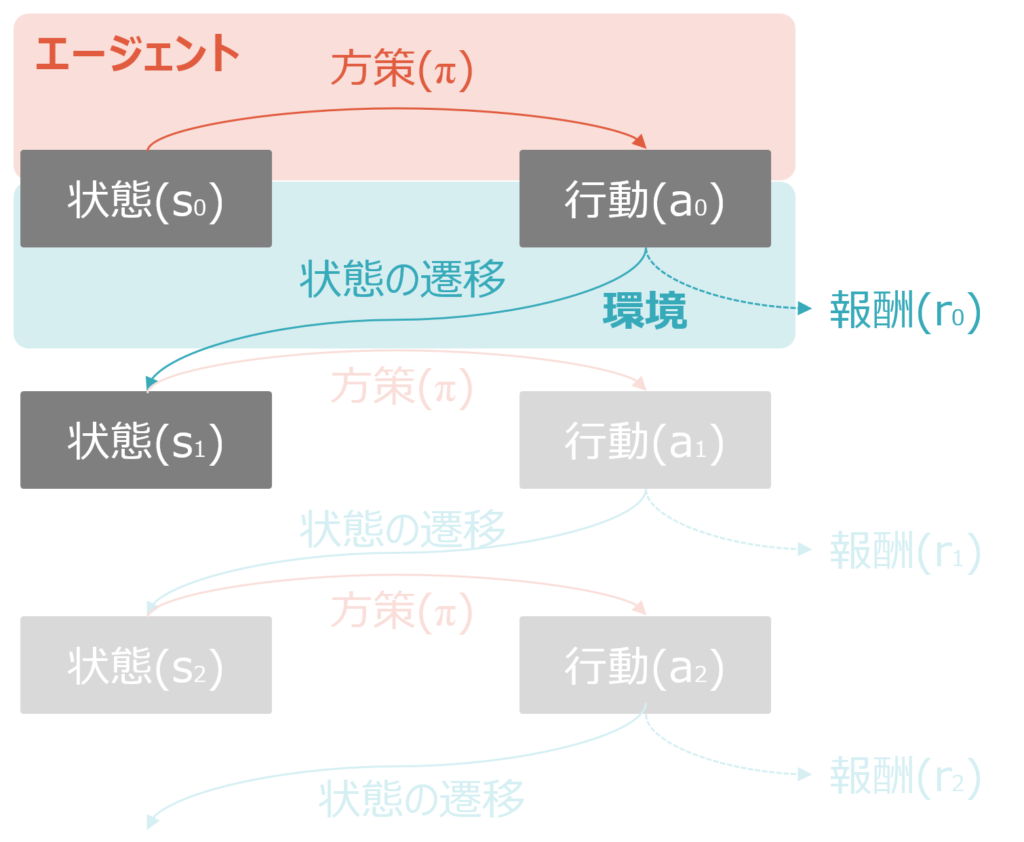
初期状態から、ある方策(π)に基づいてエージェントが行動(a0)を実行します。方策は最初はランダムですが、強化学習が進むとより良い方策になります。囲碁であれば、方策がランダムならど真ん中に打つかもしれないし、野球で1人目の打者に敬遠をしたり、自動運転の車が駐車場停止中にバックをするかもしれません。これが、学習が進むと”定石”を習得していきます。
行動(a0)が実行されると、環境側がその行動の結果を受けて状態を遷移させs1とし、更に報酬r0を発生させます。例えば野球で1人目の打者を申告敬遠しようとしたらマイナスの報酬、1人目の初級でストライクを取れたらプラスの報酬、といったイメージです。
状態s1以降も同様です。状態s1から、ある方策(π)に基づいてエージェントが行動(a1)を実行します。方策がランダムであれば、a1もランダムですが、強化学習が進んでいれば、s1の状態に応じたより良い方策が習得され、行動a1の質も改善されます。
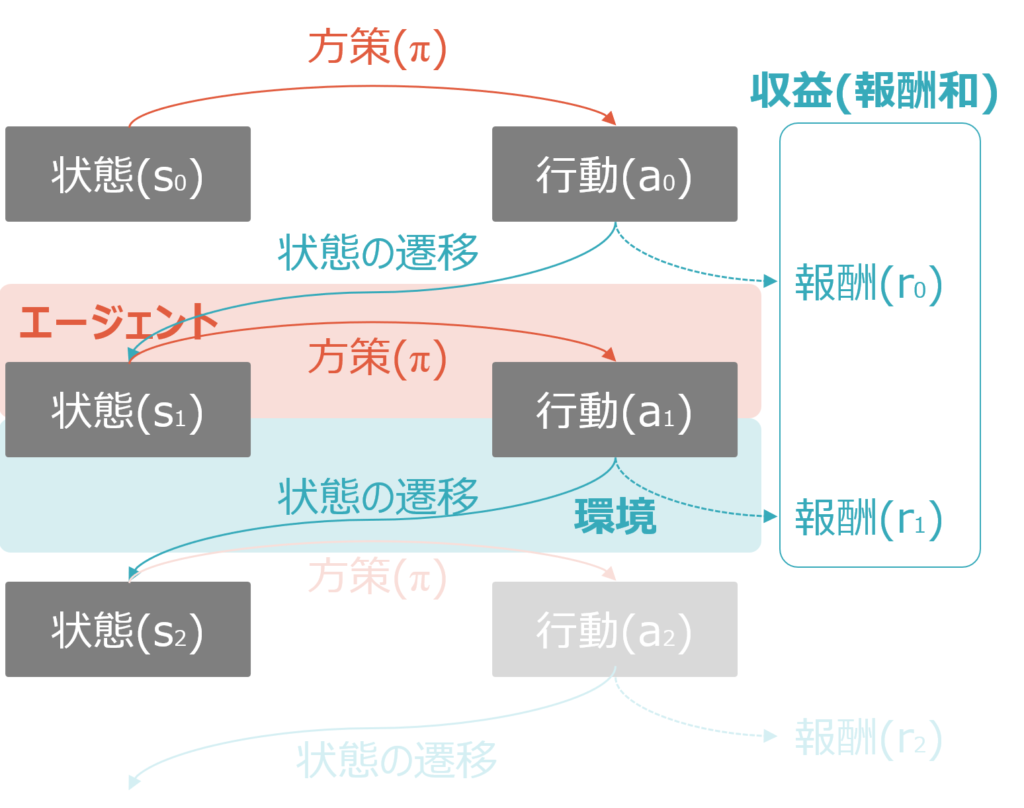
行動(a1)が実行されると、環境側がその行動の結果を受けて状態を遷移させs2とし、報酬r1を発生させます。ここまでで報酬がr0とr1の2回発生しますので、これらの合計である報酬和が収益Gとしてカウントされます。
これが強化学習の基本構造です。

コメント