今後セマンティックセグメンテーションについての記事を掲載します。今回はU-Netを扱います。
関連項目として、過去に”Down SamplingとUp Sampling”、”FCN”、及び”U-Net”について解説しました。本記事ではこれらの内容を前提に書きますので、必要に応じて以下から過去記事を参照ください。

DeconvNet
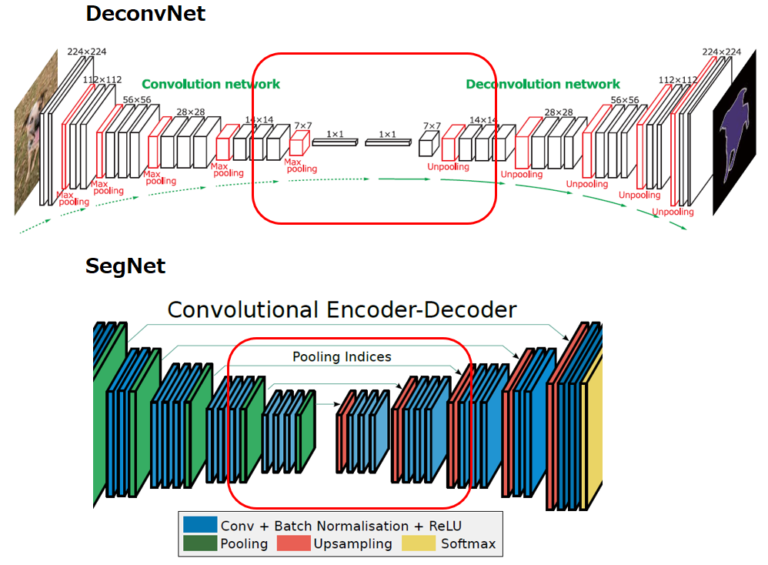
2015年に提案されたDeconvNetはFCNの発展形です。アーキテクチャは以下の通り、わかりやすくEncoder-Decoderモデルの構造をしていて、その特徴はDeconvolutionとUnpoolilngです。スキップ接続は採用していないことに注意しましょう。
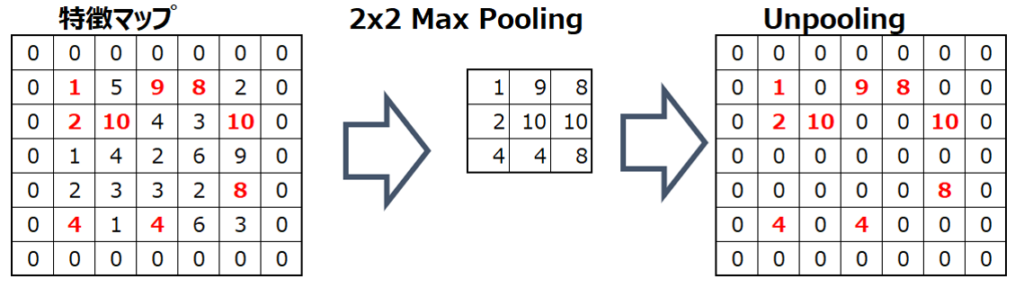
DeconvolutionについてはFCNやU-Netが採用しているTransposed Convolutionと同じです。FCNやU-Netと異なる最大の特徴がUnpoolingです。UnpoolingとはPoolingした際にどの位置のデータを取得したかを記憶しておき、Up Sampling時にはその位置情報を使う手法です。
Unpoolingについては以下も参照ください。
リンク
Unpoolingが実現しているのは位置情報の再利用です。同じUp Samplingの手法でもDeconvolution(Transposed Convolution)はパラメータが必要かつ演算量が多くなりますが、Unpoolingは元の位置に最大値を戻しているだけなのでメモリ効率が良く計算コストを削減することができます。
原著論文は以下です。

SegNet
2017年に提案されたSegNetはDeconvNetなど先行モデルを参考にし、特に道路や建物などの屋外環境のセマンティックセグメンテーションに焦点を当てて開発されました。DeconvNetよりも浅い構造にして計算効率を向上させながら、スキップ接続によって精度を保ったことが特徴です。アーキテクチャは以下の通りです。
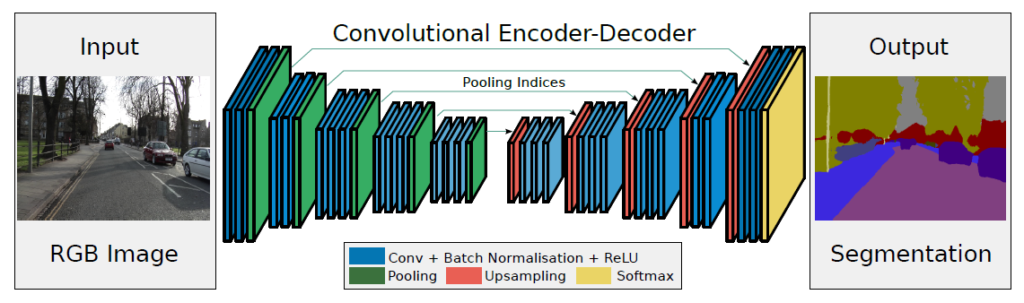
Encoder-Decoderモデルであること、DeconvolutionやUnpoolingを適用していることなどはDeconvNetと同じですが、最も異なるのは以下の赤枠部分です。DeconvNetは1×1まで解像度を落とした全結合層を用意してDown Samplingしており、これが精度向上に寄与している一方で計算コストが高いという欠点がありました。そこでSegNetは全結合しない代わりに、FCNやU-Netで採用されたスキップ接続によって精度を維持しました。
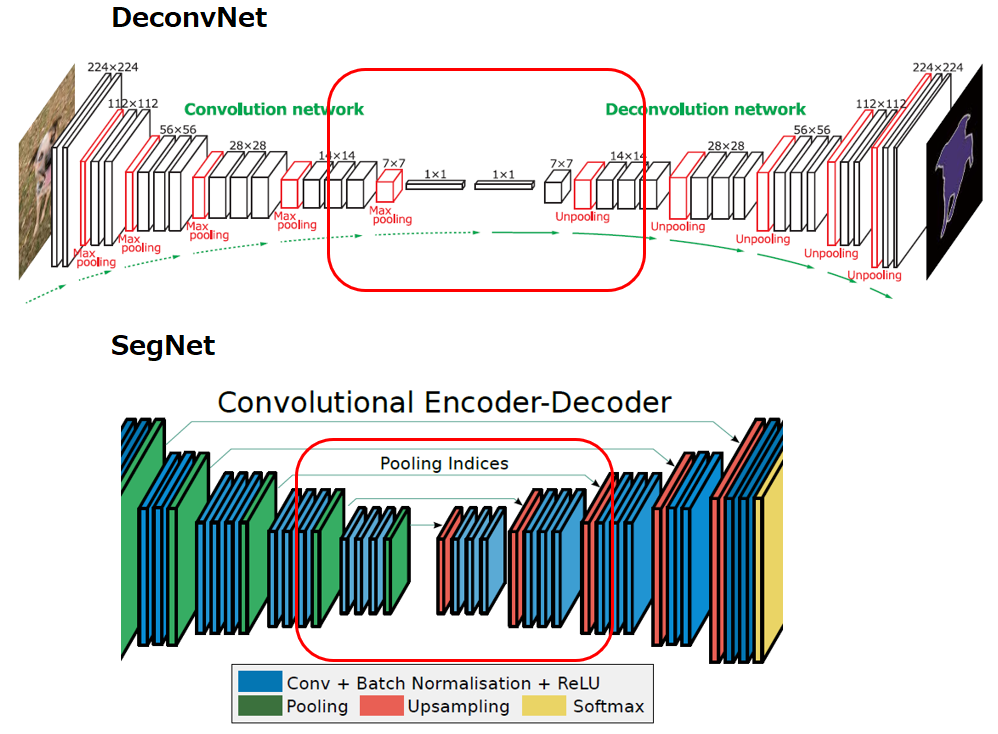
その意味では、SegNetはFCN、U-Net、DeconvNetなど既存モデルの好いとこどり、バランスを取ったモデルと言えるかもしれません。その効率性と軽量性から、SegNetは現在でもリアルタイム性やリソースの制限が厳しいタスクにおいて広く用いられています。元々開発のターゲットだった自動運転車両の周囲の環境理解にとどまらず、その計算コストの低さからエッジデバイスでのセマンティックセグメンテーションにも適用されています。
原著論文は以下です。

コメント