今回はRNNの一種であるGRU(Gated Recurrent Unit)について解説します。
GRUとは何か
GRUはGated Recurrent Unitの略で、RNNセルの一種です。GRUはLSTMに代わるより計算効率の高いアーキテクチャとして2014年の論文でKyunghyun Choらによって初めて提案されました。
GRUは、消失勾配問題により逐次データの長期依存性を効果的に捉えることができなかった従来のRNNの限界に対処するために設計された点で、LSTMと類似しています。しかし、GRUは、更新ゲートとリセットゲートの2つのゲートで構成されるよりシンプルなゲート機構を用いることで、LSTMよりも計算効率が高くなるように設計されています。
RNN及びLSTMについては以下の記事を参照ください。
LSTMとGRUの比較
GRUを紹介すると、同じくゲート機構を持つLSTMと何が違うのか、という質問がよく出てきます。
一般に、GRUとLSTMのどちらを選択するかは、アプリケーションの特定のタスクと要件に依存します。GRUは計算効率の高いモデルに適しており、リアルタイムアプリケーションやオンデバイスアプリケーションでよく使用されます。
一方、LSTMは精度が要求されるタスクに適している場合があります。最終的に、最適な選択は、タスクの特定の要件と利用可能な計算機資源に依存することになります。
LSTMとGRUのそれぞれの長所と短所を以下に纏めます。
GRUの長所
- GRUはLSTMに比べてパラメータが少なく、隠れ状態の更新に必要な計算量も少ないため、計算効率が高い。
- GRUはLSTMよりも構造が単純で、隠れ状態を保存するためのメモリが少なくて済むため、学習が容易。
GRUの短所
- GRUはLSTMよりも構造が単純であるため、LSTMほどには逐次データの長期的な依存関係を効果的に捉えることができない可能性がある。
LSTMの長所
- LSTMはGRUよりも複雑な構造を持っており、逐次データの長期的な依存関係をより効果的に捉えることができる。
- また、自然言語処理、音声認識、機械翻訳など様々なタスクで使用されており、研究者や実務家の間で定評がある。
LSTMの短所
- LSTMはGRUに比べてパラメータが多く、隠れ状態の更新に多くの計算を必要とするため、計算コストが高い。
- LSTMはGRUよりも構造が複雑で、隠れた状態を保存するためのメモリが必要なため、学習が困難。
ゲート機構
GRUの大きな特徴は、ネットワークの隠れ状態における情報の流れを制御するゲートを持つことです。GRUのゲートは、Update GateとReset Gateの2つで構成されています。
GRUやLSTMにおけるゲートの役割は、RNNの前の時間ステップからの情報の流れを調整することです。情報の流れを調整するとは、前の時間ステップから次の時間ステップに渡される情報の量と種類を制御することです。
より具体的には、0から1の値を出力するSigmoid関数を用いて、どの情報が重要かを判断する。Sigmoid関数は、現在の入力(x)と前の隠れ状態(h)を入力として、次に渡すべき情報は1に近い値、捨てるべき情報は0に近い値を生成します(そうなるように、以下の重みwを学習する)。この値が大きいほどより多くの情報を渡すべき、小さいほど情報を渡すべきでないとすることで、情報を制御しているのです。
直感的なイメージとしては、人生の重要な出来事を記録するためのノートのようなものを想像してください。GRUやLSTMのゲートは、このノートにどの情報を追加し、どの情報を忘れるかを決めているようなものです。人間の脳がどの記憶を保存し、どの記憶を捨てるかを決めていることとも関連付けて考えると、より理解しやすいかもしれません。
GRUの構造
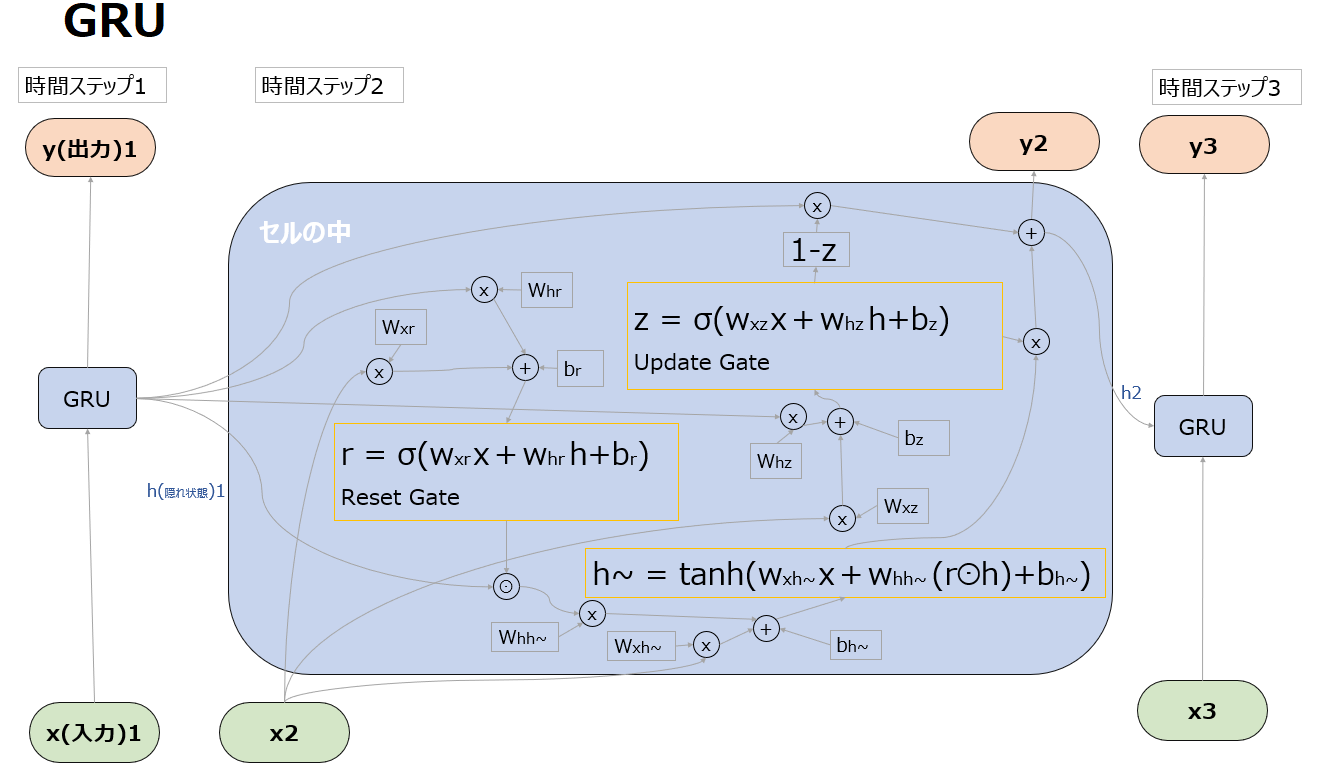
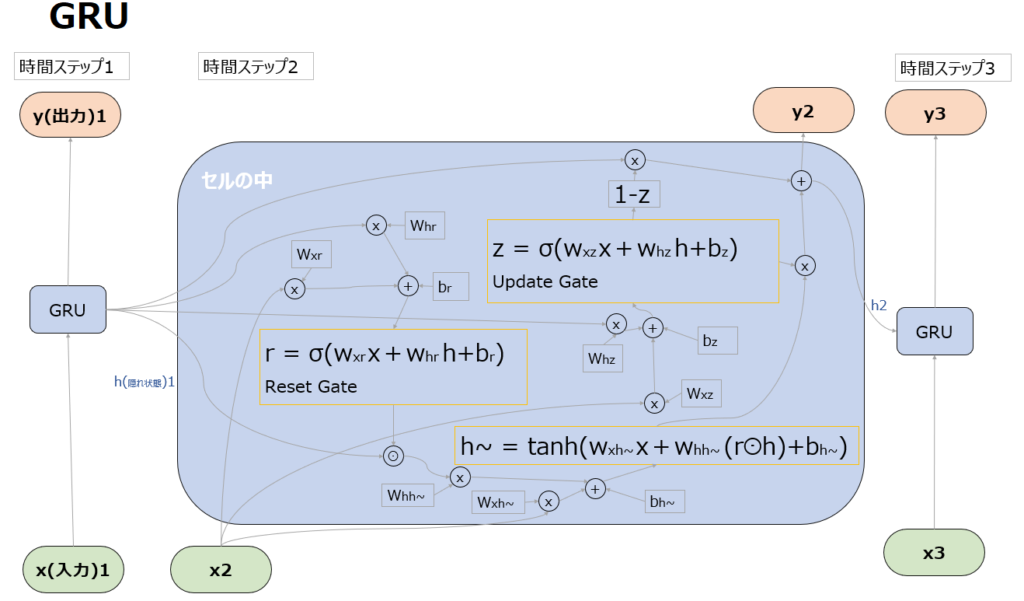
具体的には後述しますが、以下はGRUの全体像です。尚以下では、隠れ状態hについては、イメージがしやすいように”記憶”や”理解”といった言葉も用いて説明します。
また下記ではSigmoid関数やtanh関数という活性化関数が登場します。活性化関数については以下の記事を参照ください。
Update Gate
Update Gateは、以前の隠れ状態(h1)をどれだけ現在の隠れ状態(h2)に引き継ぐかを決定し、ネットワークがどの情報を残し、どの情報を捨てるかを決定します。
Update Gate を計算するSigmoid関数(σ)は、現在の入力(x2)と以前の隠れ状態(h1)を入力とし、隠れ状態に適用すべき”更新(Update)”の度合いを表す値を生成します。
この値がどのように作用するかどうかは、以下の”yとhを出力”の項目で解説します。

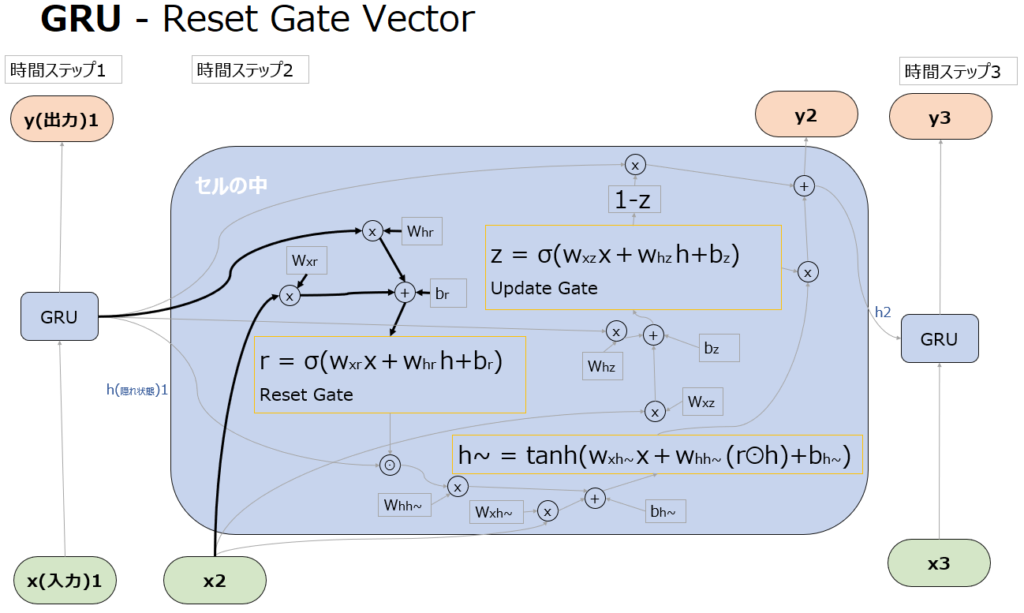
Reset Gate
Reset Gateでは、現在の隠れ状態(h2)の候補を生成する際に以前の隠れ状態(h1)をどれだけリセットするかを決定します。Reset Gateは0から1の値を出力するSigmoid関数として実装されています。Sigmoid関数は現在の入力(x2)と以前の隠れ状態(h1)を入力として受け取り、隠れ状態に適用すべき”リセット”のレベルを表す値を生成します。
この値がどのように作用するかどうかは、以下の”yの更新候補を生成する”の項目で解説します。
hの更新方針
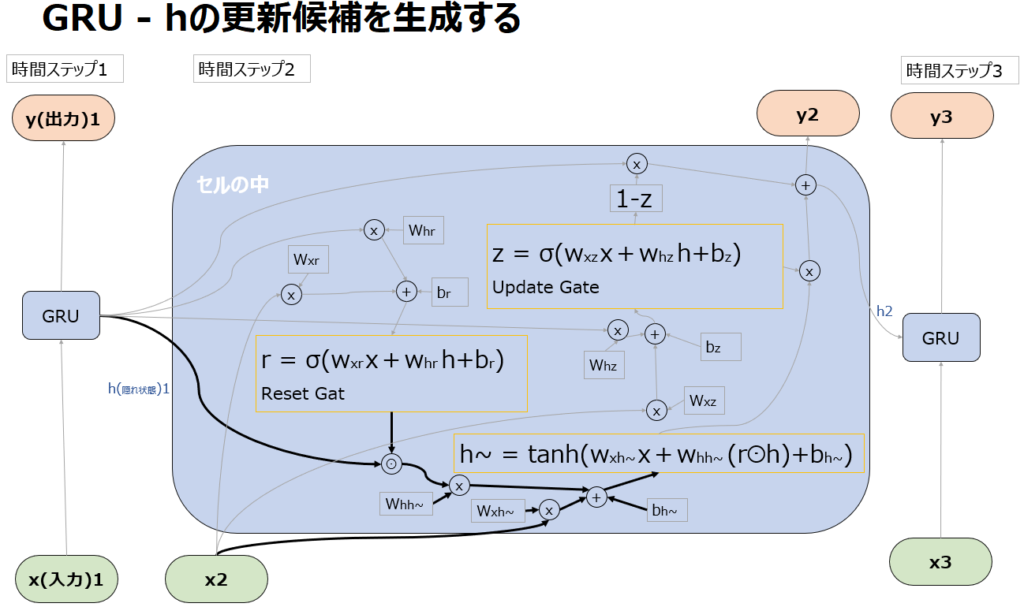
GRUにおいては、tanh関数を使った処理も出てきます。これはzやrのようにxやhをどのくらい次に渡すかを調整しているわけではないのでゲートではなく、rを使って新たな一時的な隠れ状態の”候補”を計算しています。この隠れ状態の候補が、後続の処理でzと組み合わされ、最終的に次の隠れ状態(h2)を生成します。
具体的にはrをhとかけた(⊙はアダマール積)状態で、入力xとともにtanh関数に突っ込み、-1~+1の値を出力します。
ここでrが1の場合、1つ前の記憶を最大限生かすように新しいh~つまり新しいhの候補を生成します。
またrが0の場合、1つ前の記憶を全く使わずに新しいh~つまり新しいhの候補を生成します。
ここでようやくresent gate vectorであるrの役割が、どれだけ前の記憶を弱めてresetするかを決めるものであることが理解できます(0がreset)。
そしてh~は、hをどのくらい使って更新するかというrの結果を受けて-1~1の範囲で新しい候補を生成します。
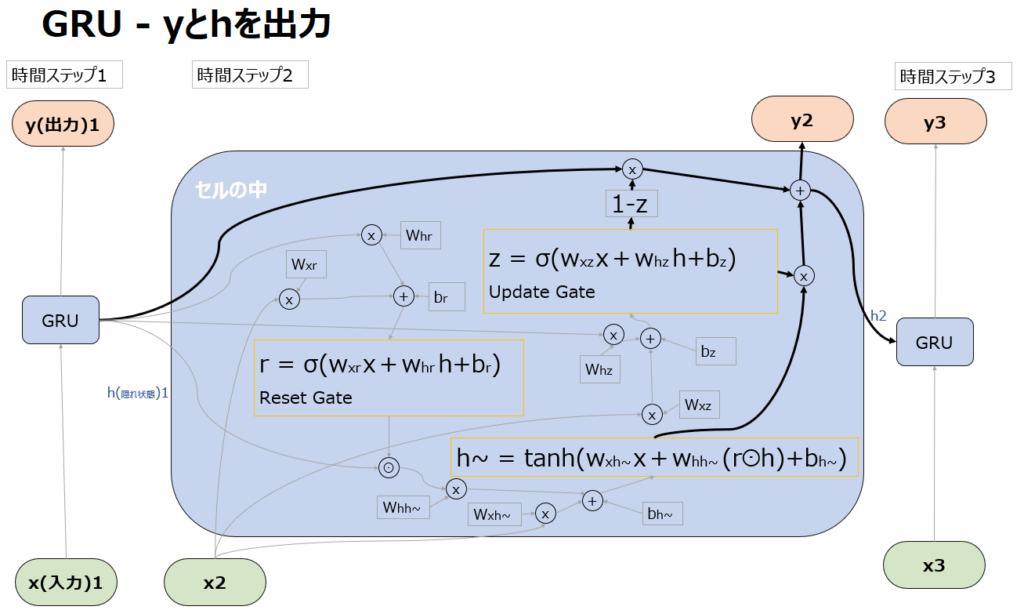
y2とh2の出力
まずUpdate gateの出力zが1に近い=記憶を最大限更新したいケースでは、後続の”1-Z”が0となり、次のステップに引き継ぐ記憶のほとんどをh~に委ねることになります。
逆にzが0に近い=記憶を更新したくないケースでは、1-zが1となり、次のステップに引き継ぐ記憶を形成する上で前回の記憶=隠れ状態であるh1が次のステップに引き継ぐ記憶の形成に大きく影響することになります。(過去からの記憶が生かされる。)
またこの計算はベクトルの成分ごとに行うため、成分ごとに記憶を更新するか前の記憶を引き継ぐかを変えることもできます。
例えば成分によっては”野球”というトピックは続いている(更新しない)が、”Positive”から”Negative”に内容が変わった(更新する)といった処理が可能になります。
以上がGRUの構造です。


コメント