過去の記事で、強化学習の基本構造を解説しました。過去の記事は以下を参照ください。
強化学習をより深く理解するために、今回はMDP(マルコフ決定プロセス)を解説します。
MDP(マルコフ決定プロセス)とは何か
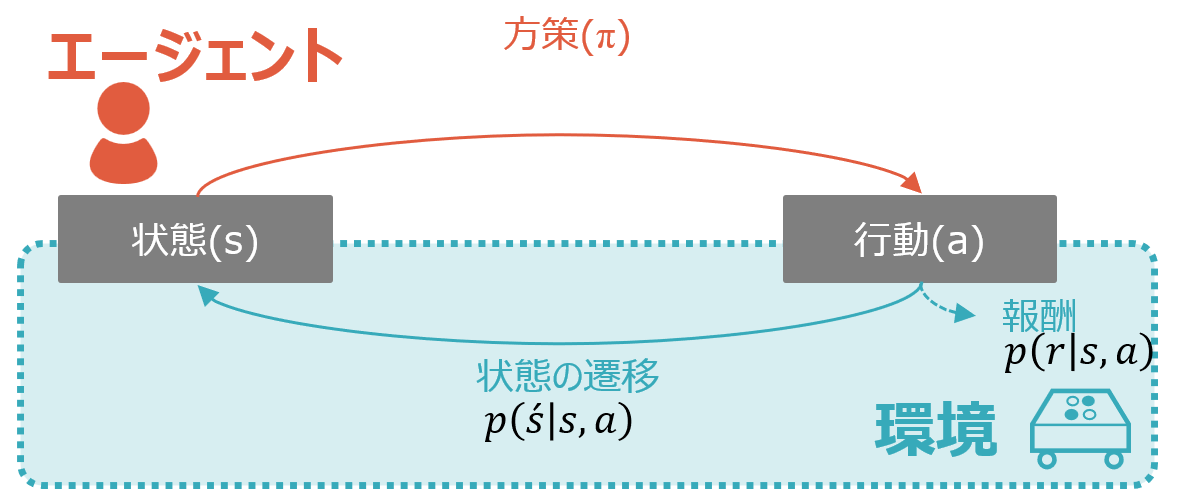
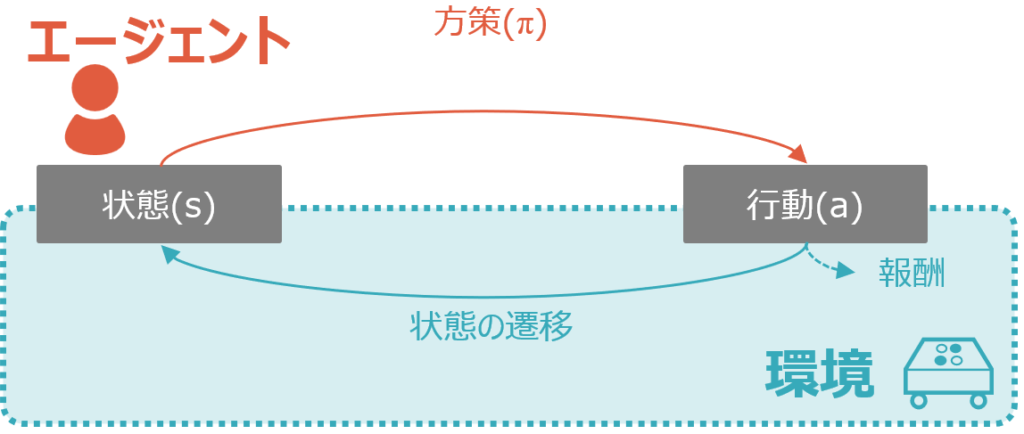
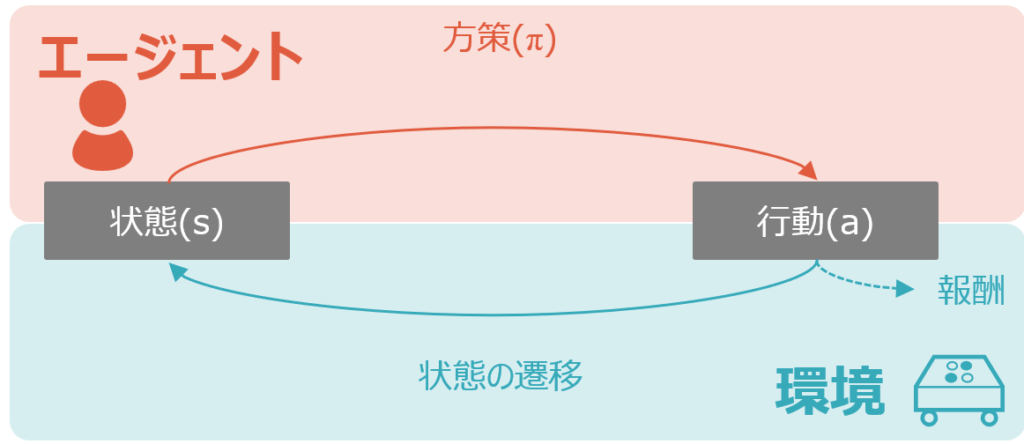
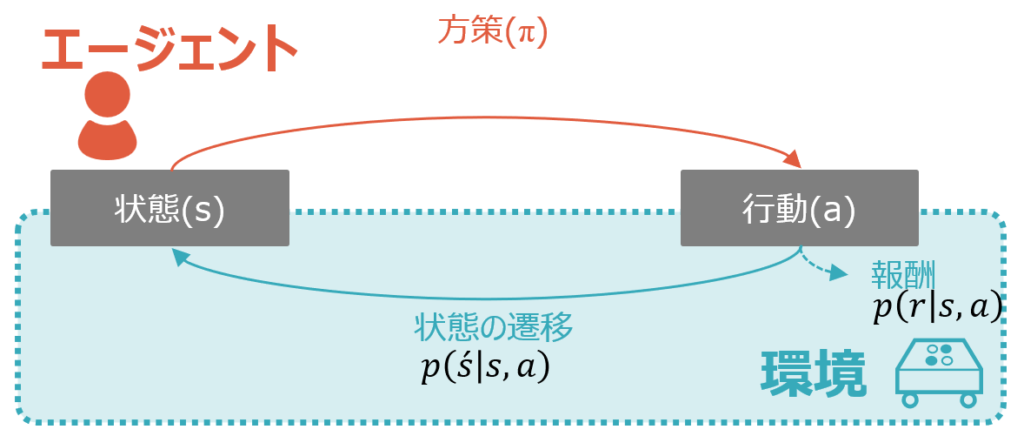
MDP(Markov Decision Process)は日本語ではマルコフ決定プロセス、もしくはマルコフ決定過程と呼ばれます。以下は過去の記事でも掲載した強化学習の基本構造の図です。MDPというのは、言ってしまえばこの環境そのもののこと、もしくは後述のマルコフ性を満たす環境のことを指します。それを端的に日本語で説明するなら、遷移後の状態と報酬が直前の状態と行動に依存する、ということになります。図中の青色部分がMDPに該当するということです。
より具体的に考えてみましょう。以下も過去の記事で示した図ですが、例えば状態s0において、MDPというのは、s1とr0がs0とa0に依存するということです。同様に、s2とr1はs1とa1に依存します。
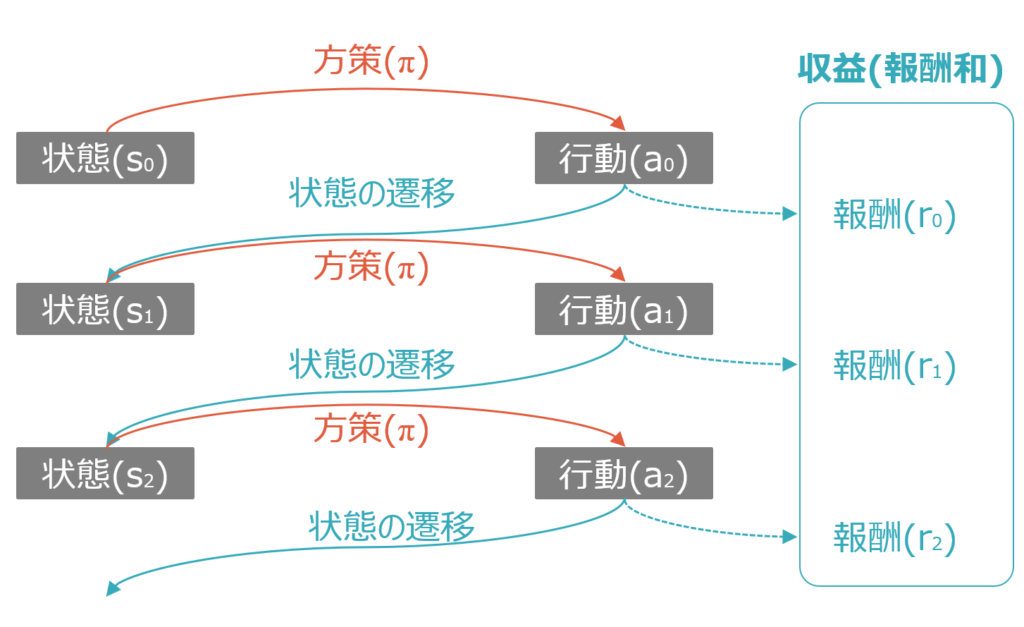
これは言い換えると、直前の状態や、状態と方策によって自動的に決まる行動に依存するMDPは、直接制御することができないことを示唆しています。エージェントの行動が依存する方策が直接制御することもできることと対照的です。
マルコフ性とは何か
上で登場したマルコフ性について説明します。
マルコフ性というのは、未来がある状態になる確率は現在の状態にのみ依存し、過去は一切関係ない、という性質です。天気を例に考えると、晴れの日の次の日の天気が50%の確率で晴れ、30%で曇り、20%で雨だとしたとき、今日が晴れなら明日も晴れる確率は50%です。この確率は、あくまで今日の天気によって決まり、その前日がどれだけ晴れていようと、どれだけ土砂降りでも、考慮しません。
強化学習においては、上述の通り行動・状態・報酬によって学習が進みますが、学習が進んだ時に過去の事象全てに依存するようなモデルを構築すると余りにも複雑になってしまうため、マルコフ性を前提とし、あくまでも1つ前の時間軸のみに依存して次の状態が決まる様にしているのです。
そして、マルコフ性が仮定できるということは、方策(Policy)が現在の状況だけに基づいて決定され、その方策に基づいて行動も決定するということです。
MDPの意義
では、そもそもMDPはなぜ重要なのでしょうか。
環境がマルコフ性を前提にしていれば、遷移後の状態と報酬を以下のように確率で表現することができます。
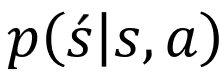
日本語訳するなら、直前の状態と行動がs,aのときの次の状態(s’)の確率(p)、となります。数学の条件付確率です。sとaがそれぞれどうなっている時に、どのくらいの確率で次の状態がどうなるかを、計算することができるのです。
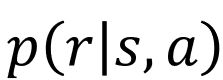
同様に日本語訳するなら、直前の状態と行動がs,aのときの報酬(r)の確率(p)、となります。
これだけだと、わざわざ数式にする意味ある?と思ってしまいますが、これが強化学習の様々な場面で当たり前のように出てきます。つまり、マルコフ性を前提としていることで強化学習の様々な理論が構築されているのです。


コメント