今回は強化学習を学ぶ上で欠かせない価値関数について説明します。過去の記事については以下の記事を参照ください。
価値関数とは何か
価値関数というのは、ある状態にいることやある行動をすることにどのくらいの価値があるのかを示す関数です。スポーツで言えば、その時点での両チームの得点や控え選手の状況などが価値を表すと言えます。ボードゲームの場合は盤面です。
なぜ価値関数を用いるのか
強化学習の目標は報酬を最大化することですが、それを達成するための手段の一つが価値関数です。望ましい状態や行動を価値が高いと評価することで、結果的に報酬を最大化することが狙いです。
今回は以下のような非常に簡単な迷路問題について、ある状態や行動の価値を評価するにはどうすればいいかを考え、最後に数式を示してその意味を考えてみます。
状態価値
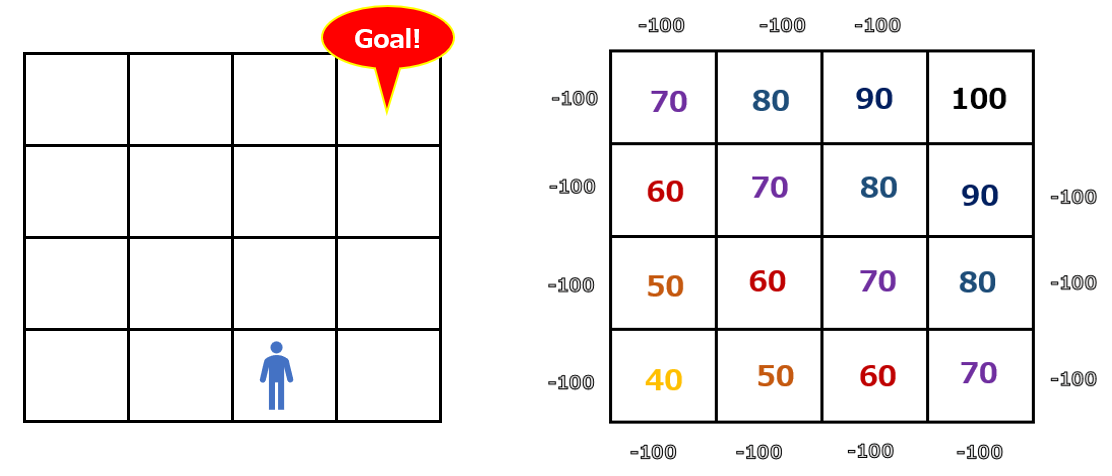
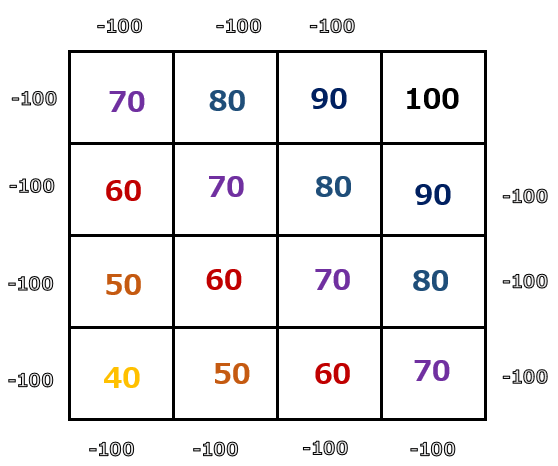
ある状態の価値を評価するのが状態価値です。例えば今回の迷路問題であれば、ゴールを100点として、ゴールからマスが離れるほど点数が低くなっていくとしましょう。以下のようなイメージです。エージェントが欄外に出てしまわないように、欄外にはマイナス100点を設定しています。
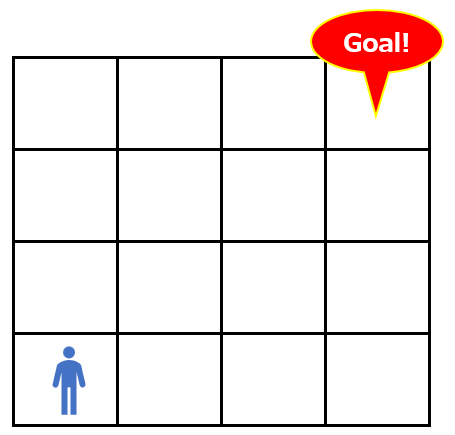
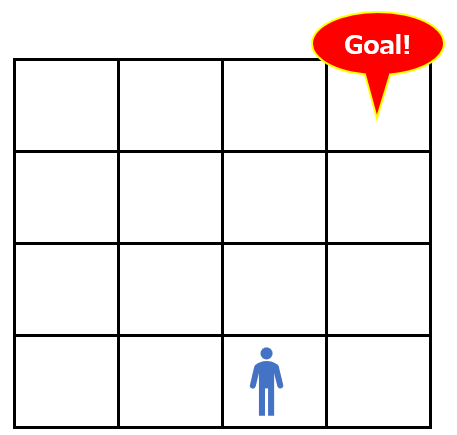
この時、エージェントが以下のマスにいたとします(状態)。この時の点数はいくつでしょうか?
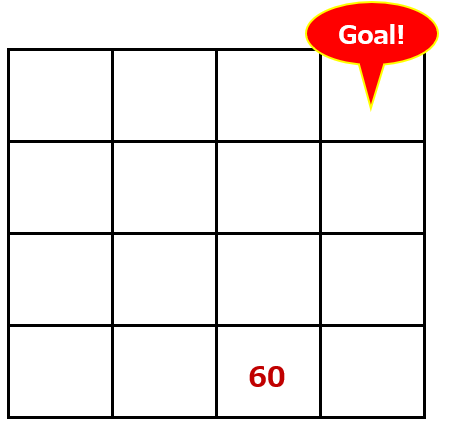
上の点数表を元に、60点であることがわかります。これが状態価値のイメージです。点数が高いほど、ゴールに近く、状態の価値が高いと言えます。
ここで評価された状態価値は、V(s)と表現されます。状態(Statusのs)の価値(Value)を評価している、という意味です。
状態行動価値
状態行動価値は、ある状態におけるエージェントの行動の価値を評価しています。先ほどと同じ問題で、同じマスにエージェントがいるとします。この状態では状態価値は60点です。
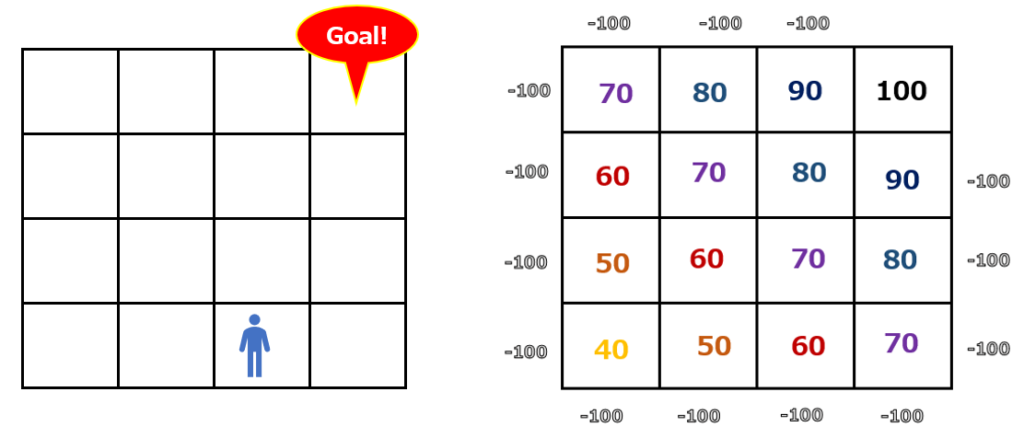
この時、エージェントが進むマスは上下左右4通りが考えられます。その4通りそれぞれに進んだ場合(行動)に状態がどう変化するのかを示しているのが以下の図です。
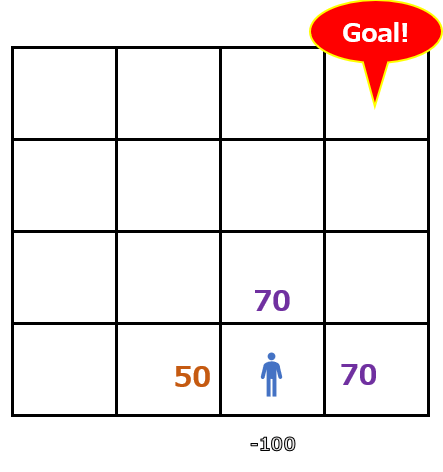
上または右に進むという行動は70点ですが、左は50点、下はマイナスです。この状態では上または右に進むという行動に価値が与えられていることがわかります。ここで評価されている状態行動価値はQ(s, a)と表現され、この値をQ値と呼びます。ある状態(Statusのs)における行動(Actionのa)の本質的な価値を評価している、という意味です。
強化学習ではこのQ値がよく出てきます。Q学習、DQNなど、手法の名前にもQが出てきます。なお、Qの由来については諸説ありますが、1つにはQualityの”Q“だと言われています。
価値関数の数式の意味
では最後に、状態価値と状態行動価値をそれぞれ関数式にした形を見てみましょう。
状態価値関数V(s)
まず、状態価値関数はV(s) の数式は以下のように表されます。
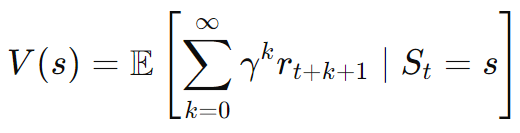
この数式を日本語訳します。
エージェントがある状態(St=s)にいるときに、今(k=0)から将来(k=無限大)にわたって得られる報酬(rt+k+1)の合計(Σ)の期待値(E)を示しています。その際、将来得られる報酬については割引率γを使って評価しています。つまり、価値関数で計算した期待値が大きくなることが、強化学習の目的である収益の最大化と適合するのです。ここが、強化学習で価値関数が活用される背景になります。
割引率については以下を参照ください。
状態行動価値関数Q(s, a)
次に、状態行動価値関数Q(s,a) の数式は以下のように表されます。
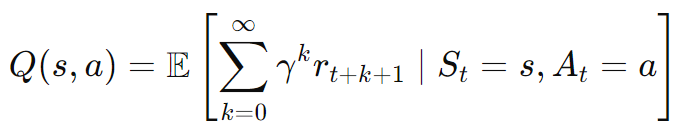
エージェントがある状態(St=s)にいて、特定の行動(At=a)を取った場合に、今(k=0) から将来(k=無限大) にわたって得られる報酬 (r t+k+1)の合計 (∑) の期待値 (E) を示しています。この際、将来得られる報酬については割引率γを使って評価しています。

コメント