過去の記事で物体検出、セマンティックセグメンテーション、インスタンスセグメンテーションの違いについて解説しました。

今後はセマンティックセグメンテーションについての記事を掲載しますが、その関連項目として、今回はDown SamplingとUp Samplingについて解説します。
Down Sampling
各モデルの説明をする前に、まず一言で言うと、CNNを用いた画像分類タスクというのはDown Samplingのみを必要とし、セマンティックセグメンテーションはUp Samplingも必要とするのです。
ここでDown Samplingは解像度の高い画像を入力としてその解像度を低くするプロセスであり、画像をマクロにとらえること、Up SamplingはDown Samplingで解像度を落としたデータを再び解像度を高くするプロセスです。
まず、Down Samplingについては、通常のCNNが行っている動作です。畳み込みとプーリングを行うことで、画像の局所的な特徴だけでなく、より大域的な情報や高次元的な特徴(物体の全体的な形状や関連性など)を抽出することができます。これが、セマンティックセグメンテーションにおけるDown Samplingの重要性です。以下に、SSDの記事で掲載した図を参考までに貼り付けます。
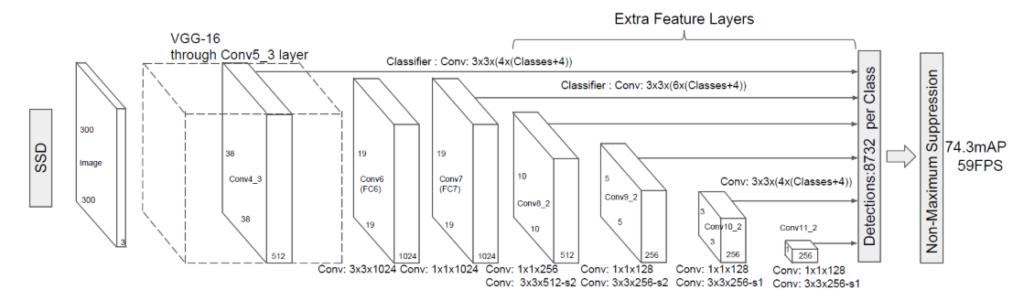
SSDについては以下を参照ください。

Up Sampling
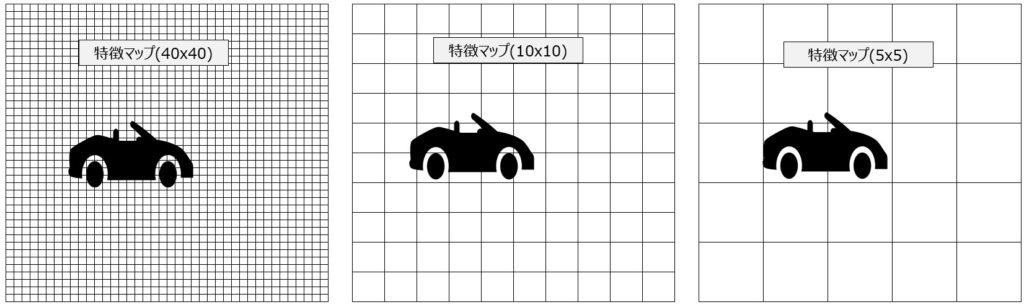
一方、Down Samplingすると、それに伴い詳細な空間情報が失われます。セマンティックセグメンテーションでは、元の画像の各ピクセルにラベル(人、車、背景など)を割り当てる必要があるため、この詳細な空間情報を失うことは問題です。上の車の画像をDown Samplingしたままセグメンテーションすると、以下のようになり、これではどこに何があるのかさっぱりわかりませんね。
そこで、Up Samplingによって画像の解像度を上げ、画像の大きさを元の大きさに戻すプロセスが必要になります。これにより、Down Samplingで得られた高次元的な特徴を利用しつつ、元の画像と同じ解像度でピクセル単位の予測を行うことが可能となります。Down Samplingについては画像分類のためのCNNの発展とともに様々な手法が開発されていましたから、セマンティックセグメンテーションの分野では特にUp Samplingをどのようにするのがいいのか、というのが大きな問題になったのです。
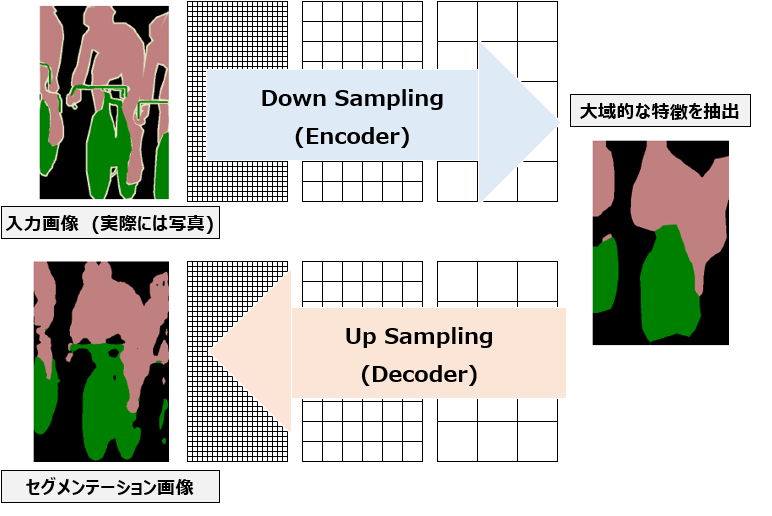
セマンティックセグメンテーションのネットワークを簡単に図示すると以下のようになります。入力画像が与えられた時、その画像はDown Samplingの過程(Encoder)を経て特徴マップに変換され、その特徴マップはUp Samplingの過程(Decoder)を経て最終的なセグメンテーションマップに変換されます。
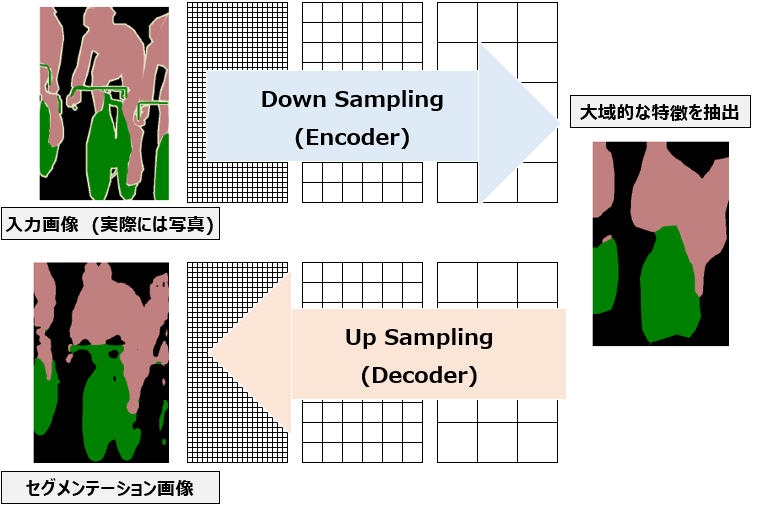
今後紹介するモデルの一つであるFCNの原著論文では、Down Samplingによって画像に”何”があるかを認識し、Up Samplingによってそれが”どこ”にあるのかを認識する、と書かれています。わかりやすいですね。
このようにEncoderで抽象化してDecoderで出力するモデルをEncoder-Decoderモデルと呼びます。今後紹介するモデルの内、FCNは厳密にはEncoder-Decoderモデルではありませんが、Down SamplingとUp Samplingの組み合わせ方により同様の効果を実現しています。Encoder-Decoderモデルについては自然言語処理のseq2seqモデルの記事も参照ください。
コメント