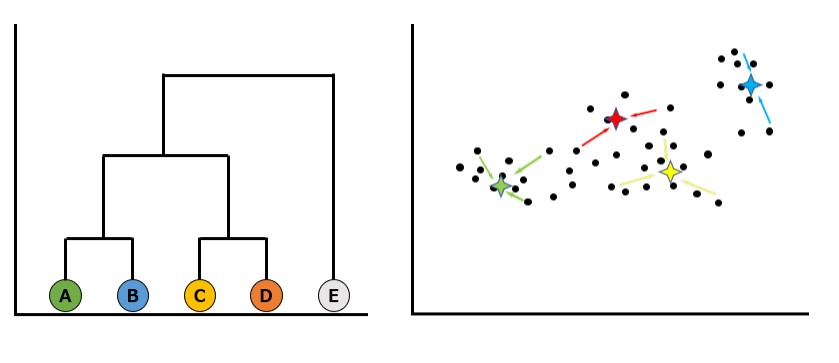
今回は、人工知能の中心的な役割を担う機械学習の中の教師なし学習の分野における、クラスタリングについて解説します。機械学習の概要や基本的な用語の説明については以下の記事を参照ください。

教師なし学習とは何か
まずは教師なし学習について、教師あり学習と比較しながら復習します。機械学習の概要に関する記事でも説明した通り、教師あり学習というのは、入力(データ、説明変数)と出力(正解、目的変数)のペアのデータを機会に学習させて、どのような入力との時に、どのような出力になるのかを予測させるモデルを構築します。例えば気温という入力からアイスクリームの販売量という出力を予測したり、花びらの大きさから花の種類を予測したりします。
それに対して教師なし学習では、学習させるのは入力のみで、出力(正解)は学習させません。正解を与えてくれる教師が存在しないから、教師なし学習です。
クラスタリングとは何か
クラスタリングというのは、ラベルのないデータをクラスター(グループ)に分ける手法です。クラスターというのは、似ている者の集合・グループという意味です。クラスターに分ける手法として、階層的クラスタリングと非階層的クラスタリングが存在します。
階層的クラスタリング
階層的クラスタリングは、クラスタリングの中でも、似ているデータ同士を1つずつグループ化したり(凝集型)、離散させたり(分割型)していく手法です。階層的クラスタリングの例として、以下ではウォード法とDiana法を紹介します。なお、階層的クラスタリングの手法の中では、ウォード法の精度が高いことが経験的に知られています。
ウォード法
凝集型の階層的クラスタリングであるウォード法は、初めにすべてのデータを1つずつのバラバラのクラスタとして、そこから似ているデータ同士を逐次的に結び付けていく手法です。以下に例を示します。
初めの状態で以下のようにA~Eの5つのデータが存在していたとします。
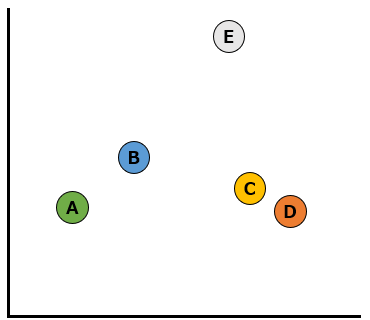
このなかで最も似ているデータはCとDです。まずはこの2つのデータをクラスターにします。
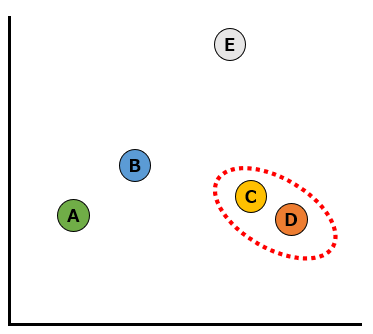
次に似ているデータはAとBなので、2つのデータをクラスターにします。以下の赤い破線のように、2つのデータのクラスターが2つになりました。
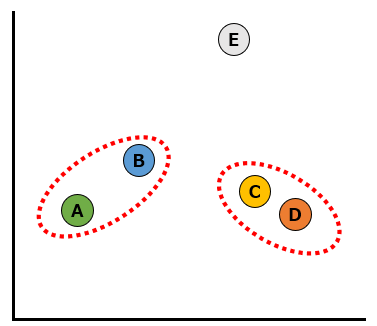
次に似ているデータは、赤い破線のAとBのクラスターとCとDのクラスターです。この2つのクラスターを青い波線での通り1つのクラスターにします。
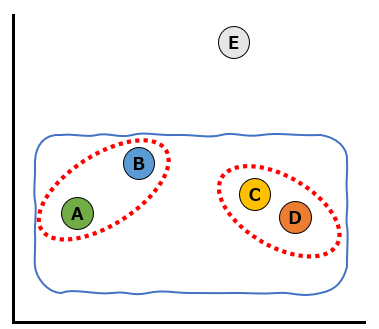
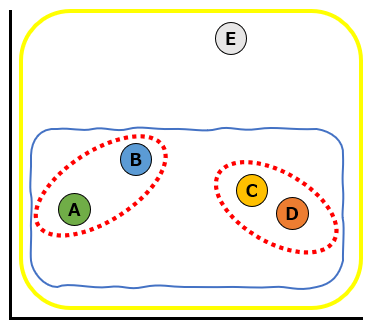
最後に一番似ていないデータであるEも含めて、以下の黄色い実線のようにクラスターにしました。
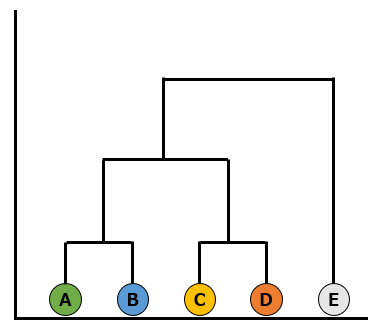
デンドログラム
こういった階層的クラスタリングでクラスターを構築していく過程を図式化したものをデンドログラムと呼びます。以下のように、デンドログラムを使うことで、クラスター形成の様子を視覚化することができます。
Diana法
1つずつのバラバラのクラスターから少しずつ凝集していくウォード法に対し、分割型の階層的クラスタリングであるDiana法は、初めに1つのクラスターの中にすべてのデータを入れて、そこから似ていないデータを逐次的に分離させていきます。あまり使われることのない手法でもあるので、ここでは詳細は割愛します。
k-means法(非階層的クラスタリング)
k-means法は、元データからグループ構造を発見し、自分で定めた任意の”k個”のクラスターに纏める手法です。以下例のように、①から⑤までの手順でクラスタリングが行われます。
①初期状態ではラベリングのされていないデータが存在しているだけです。この状態で、まずはクラスターの数である”k”を指定します。以下ではk=4として進めます。
②指定した数のクラスターを形成するための元になる点(シード)をランダムに生成します。以下の色のついた4つの星印がシードです。

③各データを、生成したシードのうち最も距離の近いシードと紐づけます。

④各シードに紐づけられたデータの平均値とシードの値が異なる場合には、シードをデータの平均値に移動します。例えば緑色のシードは、シードは(3,1)という値ですが、データの平均は(3,7)なので、緑のシードを(3,7)に移動します。このときの平均値のことを、重心と呼びます。
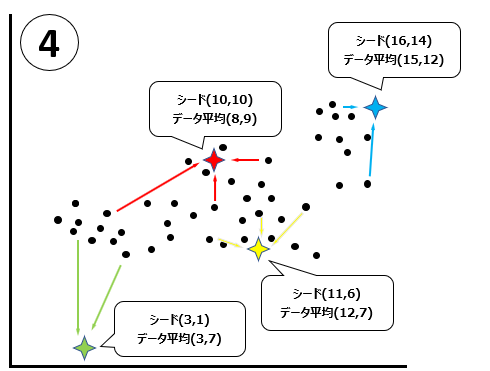
⑤4つのシードの移動が完了しました。ここから、③~⑤のプロセスを繰り返します。

③’各データを、生成したシードのうち最も距離の近いシードと紐づけます。この時1回目の③と必ずしも紐づけられるシードが同じにならないことに注意してください。例えば以下で赤線で緑のシードに紐づけられているデータは、1回目の③では赤いシードに紐づけられていましたが、今回は緑のシードの方が距離が近いため、緑のシードに紐づけられています。
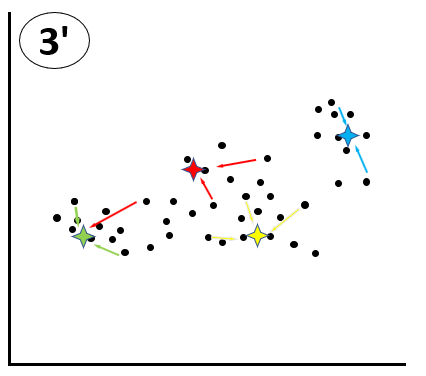
④再び、各シードに紐づけられたデータの平均値とシードの値が異なる場合には、シードをデータの平均値に移動します。青のシードではデータの平均とシードの値が一致しているため、移動は発生しません。

⑤移動が完了しました。
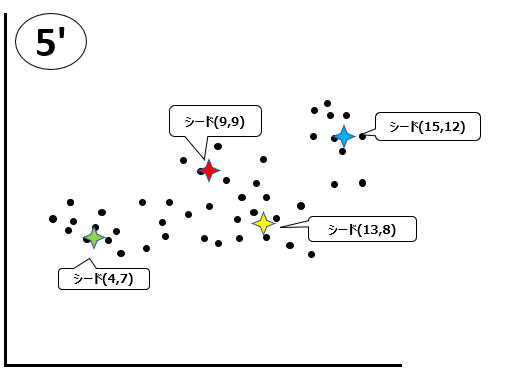
③ここから、更に③~⑤のプロセスを繰り返していき、最終的にシードが動かなくなった時点で、クラスタリングが完了します。
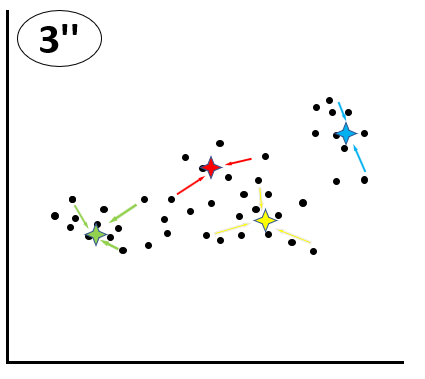
メリットとデメリット、両手法の使い分け
では、階層的クラスタリングと非階層的クラスタリングの長所と短所、両者の使い分けを整理します。
階層的クラスタリング
メリット
- デンドログラムで簡単に視覚化および解釈できるツリー状の構造を生成できる。
- クラスタの数をあらかじめ指定する必要がない。
- 階層構造を分析することでデータ間の関連を見つけるために使用できる。
デメリット
- 計算量が多く、大規模なデータセットでは実行できない場合がある。
- データの外れ値やノイズに敏感であり、クラスタの構造に影響を与える可能性がある。(外れ値は他のクラスタとうまく結合できず、小さくてまばらなクラスタを作り出す可能性)
- データポイント間の類似性を計算するために使用されるメトリック(誤差の測定方法)に依存し、主観的になる可能性がある。(階層化の具体的手順を決めるのは人間の為)
非階層的クラスタリング
メリット
- データ中の外れ値やノイズの影響を受けにくい。
- より客観的で、距離メトリックの選択に依存しないことができる。
デメリット
- クラスタ数を事前に指定する必要があり、データセットによっては困難な場合がある。
- 初期値におけるクラスタ中心の選択が不適切な場合、最適でない結果が得られることがある。
- クラスタの階層構造を提供しないため、クラスタ間の関係を解釈することが困難になる可能性がある。
両者の使い分け
階層型クラスタリングは、データセットが小さく、個々のデータ間の関係が複雑で非線形であり、データ中のクラスタ数に関する事前知識がない場合に有効です。特にデータについて深入りする前段階に全体を俯瞰するような探索的分析において有効で、得られたデンドログラムを視覚的に確認し、データをどのようにグループ化するかを決定することができます。デンドログラムで確認したい時には、必然的に階層的クラスタリングが選択されます。
一方、非階層的クラスタリングは、データセットが大きく、データ間の関係が比較的単純で数学的に表現できる場合に有効です。
実際には、階層型クラスタリングと非階層型クラスタリングの選択は、データセットの特定の特性と分析の目標に依存します。特定の状況下でどちらが最も効果的かを判断するために、両方の方法を試してみることが必要な場合もあります。
コメント