
過去の記事で勾配降下法について解説しました。過去の記事は以下から参照ください。


今回は、バッチ学習とオンライン学習を説明した上で、確率的勾配降下法、バッチ勾配降下法、ミニバッチ勾配降下法を解説し、更に関連事項としてバッチ正規化についても説明します。
バッチ学習とオンライン学習の違い
確率的勾配降下法、バッチ勾配降下法、ミニバッチ勾配降下法の違いはわかりにくいですが、理解するためには前提知識としてバッチ学習とオンライン学習について理解する必要があります。
バッチ学習は機械学習の進め方に関する手法の一つで、一度にデータセット全体を用いて学習することです。この方法では、学習を開始する前にすべてのデータをPCのメモリにロードする必要があります。
一方オンライン学習では、データを小出しに提示しながら学習していきます。この方法では、新しいデータが利用可能になるとリアルタイムでモデルを更新することができます。
次項から詳細を説明しますが、概要としては以下の図の通りです。

バッチ学習
まずはバッチ学習についてですが、そもそもバッチという言葉がわかりにくいので、ここから解説します。
英単語のbatchは、日本語で”群”や”束”などと訳されますが、英英辞典を和訳すると以下のような説明を見ることができます。
“一度に生産される量、または委託された品物”
“同時に扱われる、または類似の種類とみなされる物や人のグループ”
このバッチという言葉、IT分野では元々はデータを記録する際にパンチカードに穴を開けていた時代に、効率化のために1枚ずつではなく、纏めてカードの穴あけ処理を実行し、そのカードの纏まりをバッチと呼んでいました。

ここから、IT分野において”バッチ処理“とは、一定量もしくは一定期間に取得したデータを一括で処理するプロセス、または複数の手順を事前に記憶させておき、それらを自動で順次処理していくプロセスを指すようになりました。
機械学習においては、モデルを一定のデータセットを使って一度に学習させるプロセスをバッチ学習と呼びます。バッチ学習のメリットは大量のデータを一度に処理できるため、(データ量が同じであれば)データを1つずつ処理するよりも効率的、またデータセット全体を利用して予測を行うため、オンライン学習よりも精度が高くなりやすいという特徴があります。

一方デメリットは、データセット全体を一度に処理する必要があるため、処理速度が遅く、計算コストが高くなります。またモデルが古くなり更新が必要になった時、バッチ学習のモデルは古いデータと新しいデータを全て再度取り込んで学習し直す必要があります。
オンライン学習
オンライン学習は、バッチ学習のように固定のデータセットで一度に学習するのではなく、データを1つずつ利用します。また新しいデータが入手可能になると、そのデータからモデルが継続的に学習する手法です。”オンライン”という言葉は、PCがネットワークに接続することで、バッチ処理と比較してリアルタイムに処理することができるという特徴に由来すると思われます。
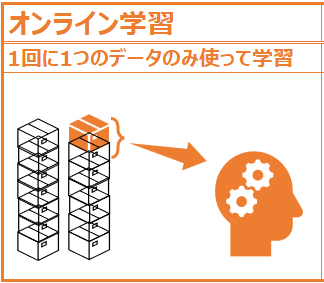
オンライン学習のメリットは、データを1つずつ処理するためデータ量が少なくバッチ学習よりも高速で効率的、また新しいデータが入手可能になるとそれに適応することができるので、データが常に変化しているような状況で非常に有効であることです。
一方デメリットは、データセット全体を使用して予測するわけではないので、バッチ学習よりも精度が落ちることがあります。また、データを処理する順序に敏感で、モデルの性能に影響を与える可能性があります。
ミニバッチ学習
勾配降下法では、”ミニバッチ”という言葉も出てきます。これはいわばバッチ学習とオンライン学習の中間的な方法で、データの1部を”ミニバッチ”という塊に分けて学習を行います。詳しくは後述します。
学習プロセスを比較
上記で説明したオンライン学習、バッチ学習、そしてミニバッチ学習について、それぞれどのような学習プロセスを経るか、図解します。
まず1週目のステップです。オンライン学習では1つ目のデータしか使わずに学習が進み、ミニバッチ学習ではミニバッチ(ある一定の量のデータの塊)が使用され、バッチ学習では全データが学習に使用されています。

続いて学習2週目です。オンライン学習では2つ目のデータが使用され、ミニバッチ学習では2つ目のミニバッチ(塊)が使用され、バッチ学習では再度全データが使用されています。
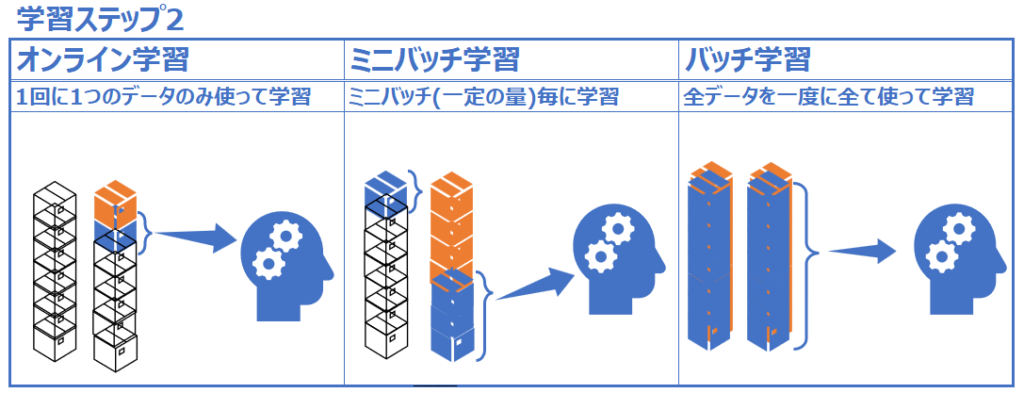
3週目以降も同様です。
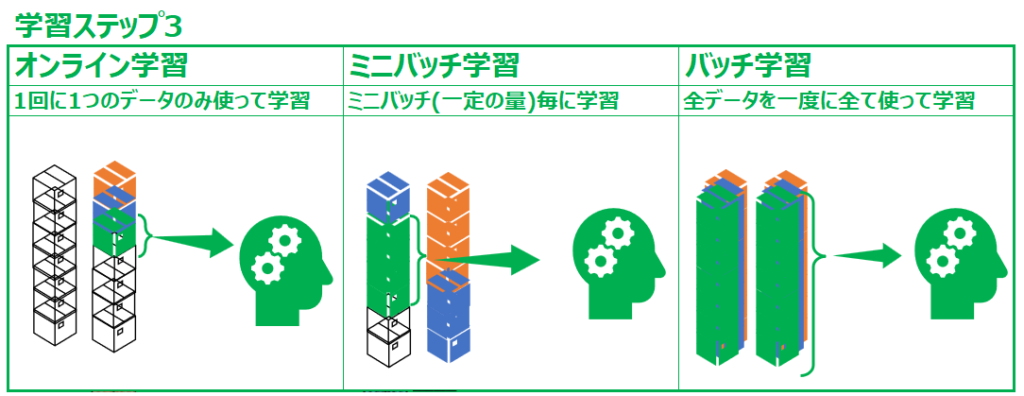
この図から、それぞれの学習の違いを理解してもらえればと思います。
勾配降下法の種類
では、上のそれぞれの学習方法を基にした勾配降下法について解説します。
バッチ勾配降下法
バッチ勾配降下法(Batch Gradient Descent)は、バッチ学習の項目の通り、すべての学習データを使って学習を進める方法です。勾配降下法はすべての入力データについて偏微分をし、学習率をかけてパラメータを更新します。そのため入力データが膨大になるとパソコンでも計算しきれないような事態が発生し、バッチ勾配降下法では対応できない可能性があります。
確率的勾配降下法(SDG)
確率的勾配降下法(SDG, Stochastic Gradient Descent)は、オンライン学習の項目の通り、ランダムで選んだ1つのデータのみを使用して学習を進める方法です。パラメータ更新ごとに1つのデータしか用いないため、処理が速いというメリットがありますが、一方でデータを1つしか使わないため学習結果が不安定です。
ミニバッチ勾配降下法(Mini-Batch SGD)
ミニバッチ勾配降下法(Mini-Batch Stochastic Gradient Descent)は、バッチ勾配降下法とSDGの長所を組み合わせたような手法です。オンライン学習の確率的勾配降下法と併せてSGDと呼ばれています。
ミニバッチ勾配降下法ではミニバッチと呼ばれる小さなデータ集合をいくつかランダムに選び、そのミニバッチに対して勾配降下法を適用します。このミニバッチのサイズは、全てのコンピュータが扱いやすいように2の累乗、更に特定のコンピュータが8進法の仕組みを有していることから32,64,128などがよく用いられます。
バッチ正規化(Batch Normalization)
上記で見た通り、SGD(確率的勾配降下法もしくはミニバッチ勾配降下法)の場合、全てのデータを使って学習を進めるわけではないため、学習のたびごとに入力値のスケールが異なることがあります。例えば最初のミニバッチの学習の結果では入力は大きな値ばかりが選ばれたが、次のミニバッチでは小さな値ばかりとなる可能性もあります。このようなケースでは学習ごとの入力値のばらつきにより、ステップを重ねても学習がうまく進まないことがあります。
例えば以下の図例では、前半のミニバッチは大きな値だけが選ばれていて、後半のミニバッチでは小さな値だけが選ばれています。
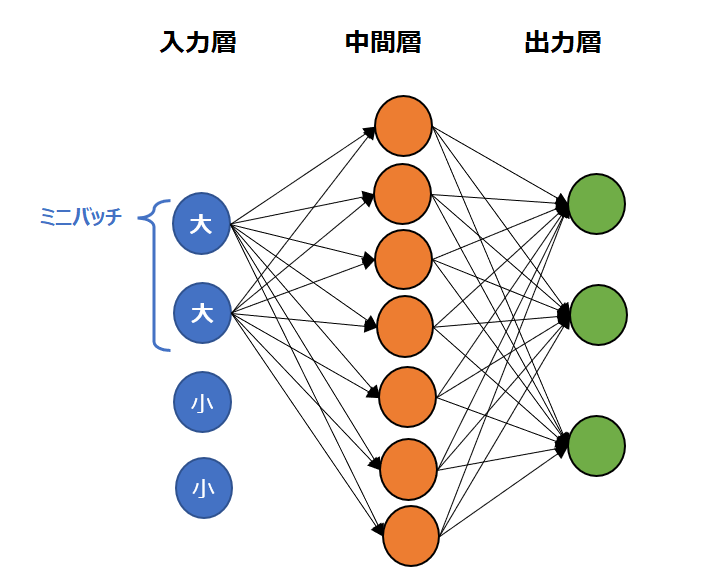
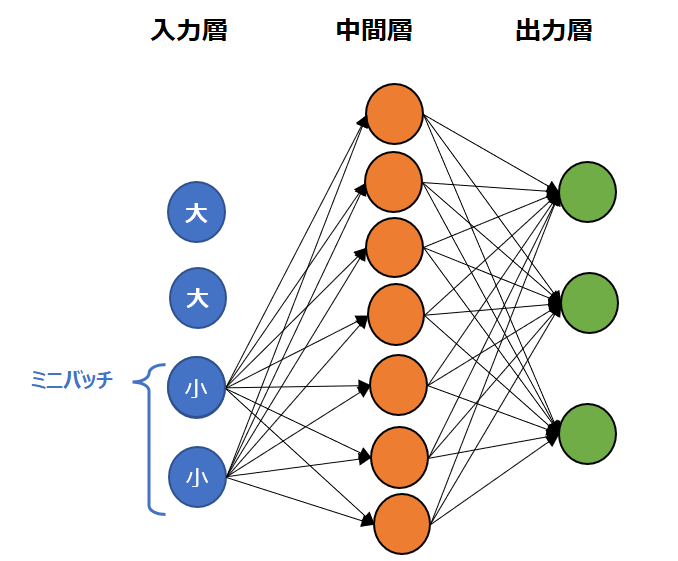
これでは学習が円滑に進まないので、ミニバッチを平均0、標準偏差1となるように正規化します。これがバッチ正規化(Batch Normalization)です。
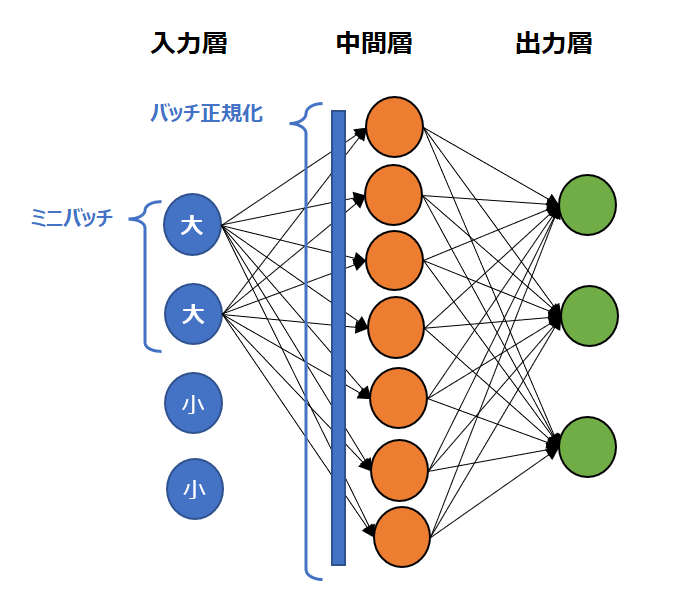
なお、正規化については以下を参照ください。
コメント