
今回は機械学習における過学習(overfitting)について説明します。機械学習の全体像については以下の記事を参照ください。

過学習とは何か
過学習というのは文字通り、学習し過ぎることです。人間に例えれば、ある教科書を徹底的に学んだ結果、その教科書に書いていない問題に対応できなくなるようなイメージです。機械学習においては、予測モデルの元データから、過剰に規則性を見つけてしまうということです。以下では、例を出してできるだけ直感的に説明します。
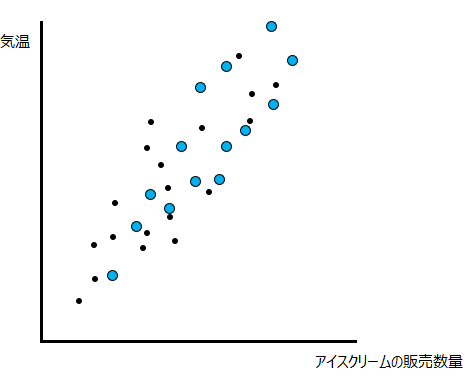
以下のグラフは、あの日の気温とその日の1日当たりのアイスクリームの販売数量に関するデータの集合の例です。例えばある日は30度で100個売れた日や、20度で50個売れた日があるようなイメージです。気温が高い方がアイスクリームが売れるということは容易に想像できると思うので、以下のデータの集合は直感的にも理解しやすいかと思います。

このデータの集合を使って、気温を入力(データ)、販売数量を出力(正解)として予測モデルを作ることを考えます。ここでいう予測モデルというのは、気温がわかれば、その日の販売数量がある程度予測できるようなものです。イメージしやすいのは以下のように1次関数のオレンジの直線を引くことでしょうか。

我々人間は気温が上がればアイスクリームが売れやすいだろうと直感的に理解できるので、上の1次関数の予測モデルは納得しやすいでしょう。なお、こういった予測モデルを線形回帰モデルと呼びます。線形回帰モデルについては今後記事を掲載しますので、お待ちください。
我々人間は直感的に上の1次関数の当てはまりが良いと思えますが、機械はモデルの当てはまりを計算で評価します。具体的にはMSE(平均二乗誤差)という損失関数が頻用されます。詳しくは最小二乗法や損失関数については以下の記事をご覧ください。
機械学習の線形回帰モデルでは、どのように線を引くのが適切なのか、コンピュータ自身が自分で元データを基に学習していき、その中でMSE(平均二乗誤差)等の指標が低くなるようにすることでより当てはまりの良いモデルを作ります。
ではこの時、機械学習のプログラムが以下のような赤線を引くのが良い、と学習したとしましょう。この時の問題点は何でしょうか?

過学習は何がマズいのか
未知のデータを予測できるか
機械学習のプログラムによって算出されたということは、赤線のMSEはオレンジの直線よりも低い。つまり誤差が少なく、元データに対してより当てはまりが良いはずです。問題は、では上の赤線が、オレンジの直線よりも、未知のデータに対する予測精度が高くなるかどうか、ということです。
機械学習でデータを読み込ませて予測モデルを作成する目的は、あくまで未知のデータが現れた時に精度高く予測することです。ただし、モデル作成時点ではもちろん未知のデータは手元に存在しませんから、既知のデータを使って機械に学習してもらうことになります。
ここがある種の落とし穴があります。既知のデータのデータ量や、機械がデータをどのくらい一生懸命学習するかは、人間が設定します。データ量が少なかったり、あまりにも厳密に学習させたりすると、既知のデータに対しては当てはまりが良いけど、未知のデータを予測できない、といった事態が発生してしまいます。これを、過学習と呼びます。
データを後から追加して予測精度を測る
機械学習では過学習を可視化するために、手元のデータをすべて学習用に読み込ませることはしません。一部は検証用データとして手元に取っておいて、残りを学習用データとして機会に学習させてモデルを作成します。そのモデルに検証用データを加えた時に、検証用データを精度高く予測できているかを見ることで、過学習が起きているかどうかを見ることができます。
例えば、元のデータ例に対して、以下のように水色の検証用データを追加します。
この時、オレンジと赤線のモデルはこの検証用データをどのくらい精度高く予測できているでしょうか。
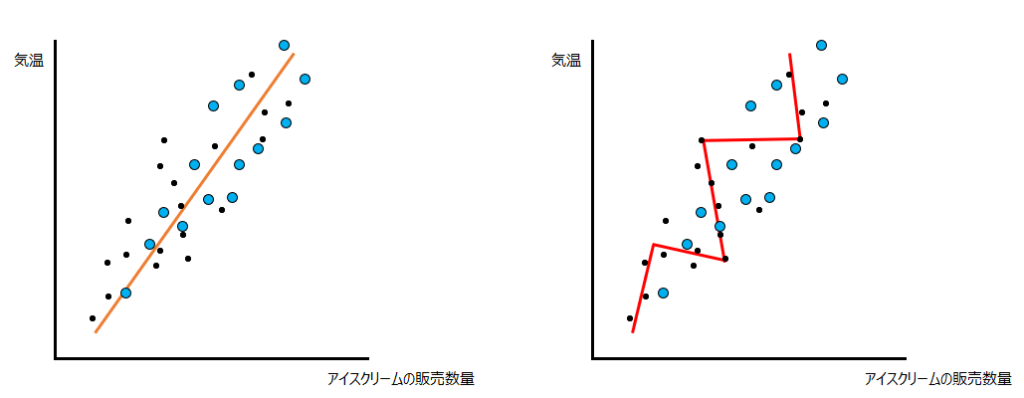
これを見る限り、赤線の方が水色のデータを距離がある=誤差が大きいように見えます。誤差が大きいということは、精度が低いということです。単純化して説明しましたが、これが過学習の問題です。学習用の元データに適用し過ぎて、未知のデータを予測しずらくなってしまうケースがあるのです。
過学習の原因と対策
では、上のような過学習はなぜ起きるのか、またどのように回避すればよいかを説明します。
データ量が少ない
上の例でも見たように、データ量が少ないと、過学習が起きやすくなります。対策はわかりやすく、データ量を増やすことです。
データが正規化されていない
データが正規化されていないことも、過学習の原因になりえます。正規化については以下の記事を参照ください。
説明変数が多すぎる
説明変数が多すぎる場合にも、過学習が起きやすくなります。その際の解決策の1つは正則化です。正則化については以下の記事を参照ください。

モデルが合っていない
機械学習には様々なアルゴリズムが存在します。SVM、決定木、ランダムフォレスト等々。これらのアルゴリズムが生み出す予測モデルもそれぞれ異なります。データ量が十分で、正規化済のデータでも過学習が起きてしまうのであれば、様々なモデルを試してみるとよいでしょう。

コメント