
前回記事では、畳み込み(Convolution)とは何かについて説明しました。前回記事は以下を参照ください。
今回は、通常の畳み込みとは異なる、特殊な畳み込みとして、Pointwise convolutionとDepthwise convolutionについて説明します。いずれも、パラメータ数を削減する工夫です。
Pointwise convolution(1×1の畳み込み)
さて、前回記事で何の気なしに使ったカーネルサイズ1×1の畳み込みについて、考えてみましょう。

これは実は非常に特殊な畳み込みで、Pointwise convolutionとも呼ばれています。上のネズミの例からもわかる通り、1×1の畳み込みを実施すると、元のチャネル5つの内、あるチャネルは大きめに、あるチャネルは小さめに評価してそれらを合体させることができます。
例えばCNNの内部で、”右目の検出器はあまり役に立たないな”となれば、右目検出器の出力を受け取ったチャネル④用のフィルターの値は0にすることができます。これはつまり、次元削減を実現していることになります。更に、カーネルサイズが1×1ということは学習時に更新されるパラメータが1つだけということです。5×5のフィルターなら学習パラメータが25個ですから、比較すると計算コストを1/25に削減できるということです。
1×1の畳み込みによる次元削減は2014年に登場したGoogLeNetに備えられているInceptionモジュールなどで使用され、今では一般的な機構になっています。GoogLeNetについては以下の記事を参照ください。

Depthwise convolution
一方、上の例では出てきていませんが、Depthwise convolutionという特殊な畳み込みの処理も存在します。入力チャネル1つに対して1枚のフィルターしか適用しないような畳み込みです。
上で一度説明したように、通常はフィルターサイズ1毎に、チャネル数分のフィルターを作成します。以下ではフィルターサイズが5(①~⑤)であり、チャネル数が3(RGB)なので、5つのフィルターはそれぞれ3枚から構成されています。フィルターの数は合計5×3= 15枚です。
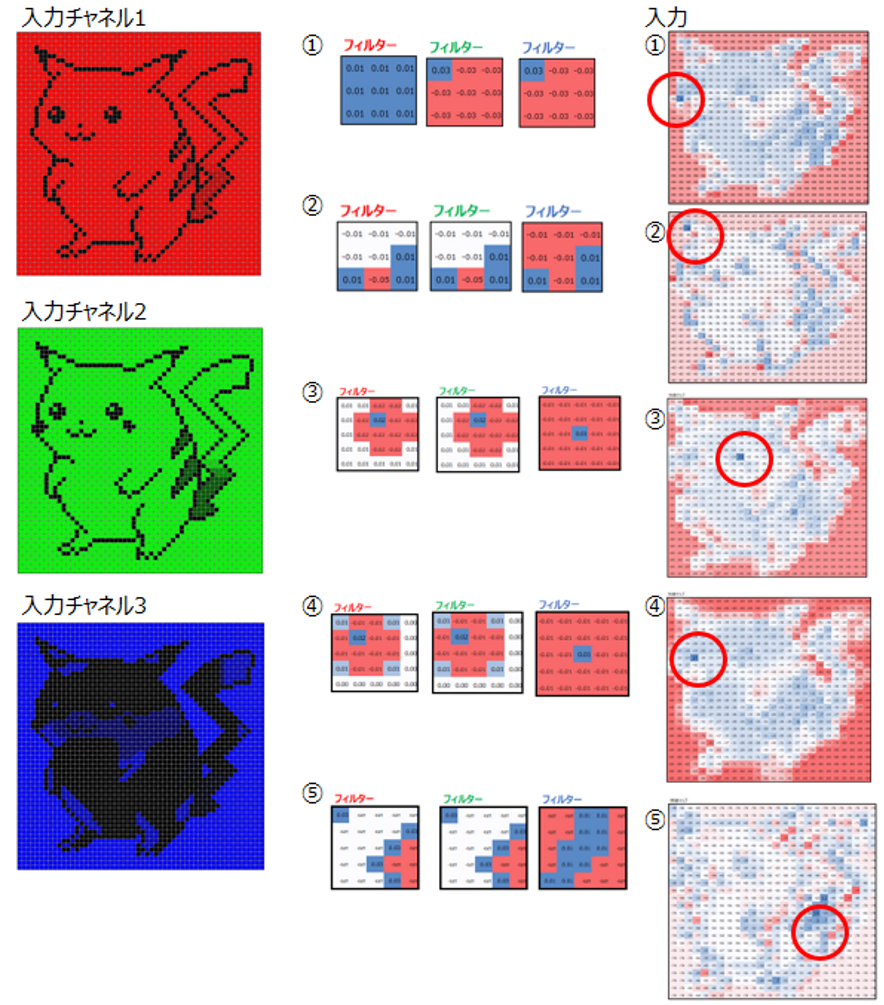
それに対してDepthwise convolutionの場合は、5つの入力チャネルに対してフィルターはそれぞれ1枚だけで構成されます。必然的に入力チャネル数と出力チャネル数は同じになります。
例えば、以下ではPointwise convolution(1×1)の前にdepthwise convolutionを挿入してみました。

フィルターがそれぞれ1枚ずつしか存在しないことがわかります。
これはつまり何をしているかというと、各チャネルの特徴をより強調させるようなフィルターを作成し、処理しているということです。入力チャネル数に対してフィルター1枚でよいため、更新パラメータが非常に少なく済みます。実際のCNNでも、このDepthwise convolutionによってエッジ協調の画像を得たり、特定の模様を検知することができます。
Depthwise convolutionがどのくらいパラメータ数を削減できるのか具体例を出して考えてみましょう。入力チャネルと出力チャネルが5個ずつ、フィルターは3×3とすると、以下の通り5x5x3x3=225個のパラメータが学習対象となります。

Depthwise convolutionの場合は以下の通り5x3x3=45となります。出力チャネル数分の削減、このケースでは、1/5の削減効果があります。

それぞれの名前の由来のイメージ
Pointwise convolution(1×1)は文字通り、1×1というpoint(点)で畳み込みをすると思えばイメージしやすいと思います。
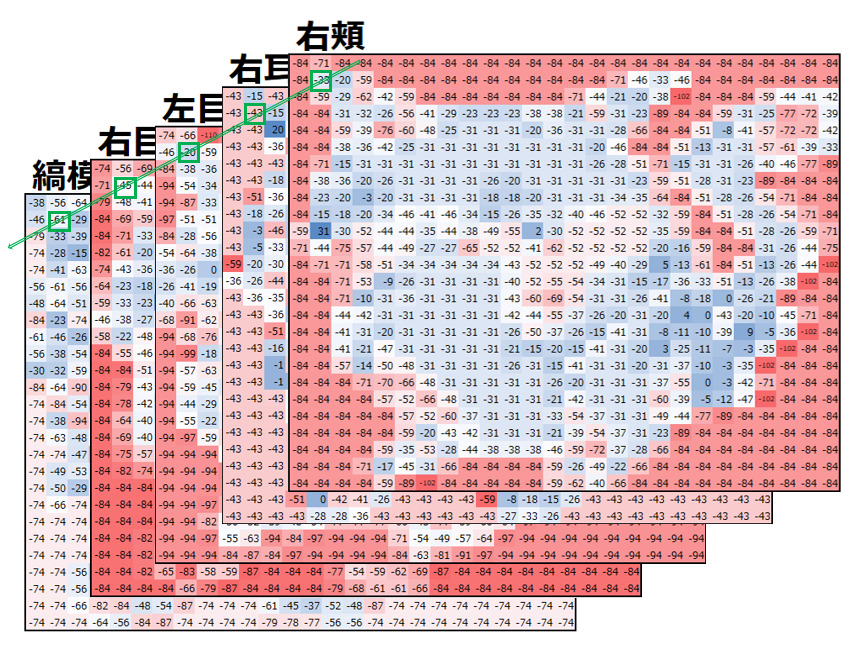
一方Depthwise convolutionのDepthwiseは直訳すると”深さごと”ですが、ここでいう深さはチャネル数と思ってください。”チャネルごと“に共通の1つのフィルターで畳み込みを実施するからDepthwise convolution、と理解してもらえればイメージしやすいのではないでしょうか。
Depthwise Separable Convolution
Depthwise Separable Convolutionは2017年に発表されたMobileNetというモデルに搭載されています。MobileNet以前のCNNは処理能力・メモリ・バッテリー寿命が限られているモバイルデバイスで実行するには計算量が多すぎました。この問題に対処するために、MobileNetはモバイルデバイス上で効率的に実行できる軽量のアーキテクチャを持つよう設計されました。
そこで使用されているのがDepthwise Separable Convolutionで、標準的なConvolutionを、Depthwise convolutionとPointwise convolutionに分割しています。分けて畳み込んでいるので”Separable”です。Depthwise Separable ConvolutionにおけるPointwise convolutionはフィルターサイズも1のため、結果的にDepthwise Convolutionが前層のチャネル数分の出力をしたらそれらを線形結合(重み付き線形和)する役割を果たしています。

コメント