2022年末にリリースされたOpenAIのサービスChatGPTが世界中で話題になっています。ChatGPTはGPT-3.5という言語モデルを使ったサービスですが、GPTというのはGenerative Pre-trained Transformerのことです。今後、ChatGPTの元ネタであるTransformerについて解説記事を掲載しますが、今回はその準備としてMulti-Head Attentionを解説します。
AttentionとMulti-Head Attention
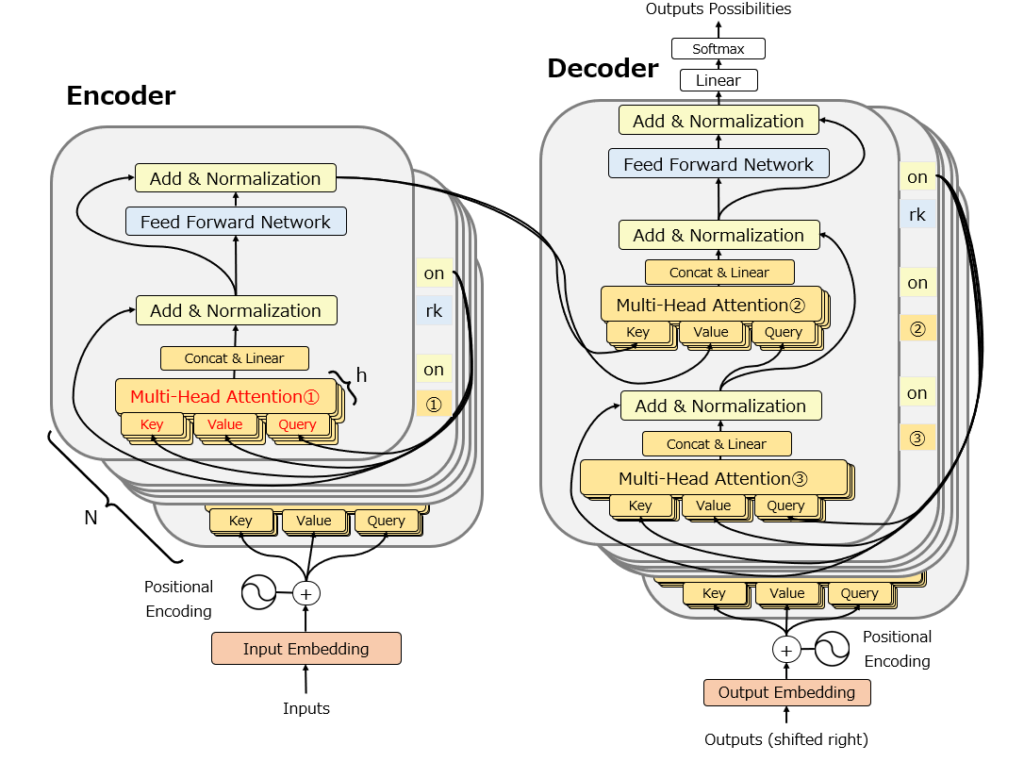
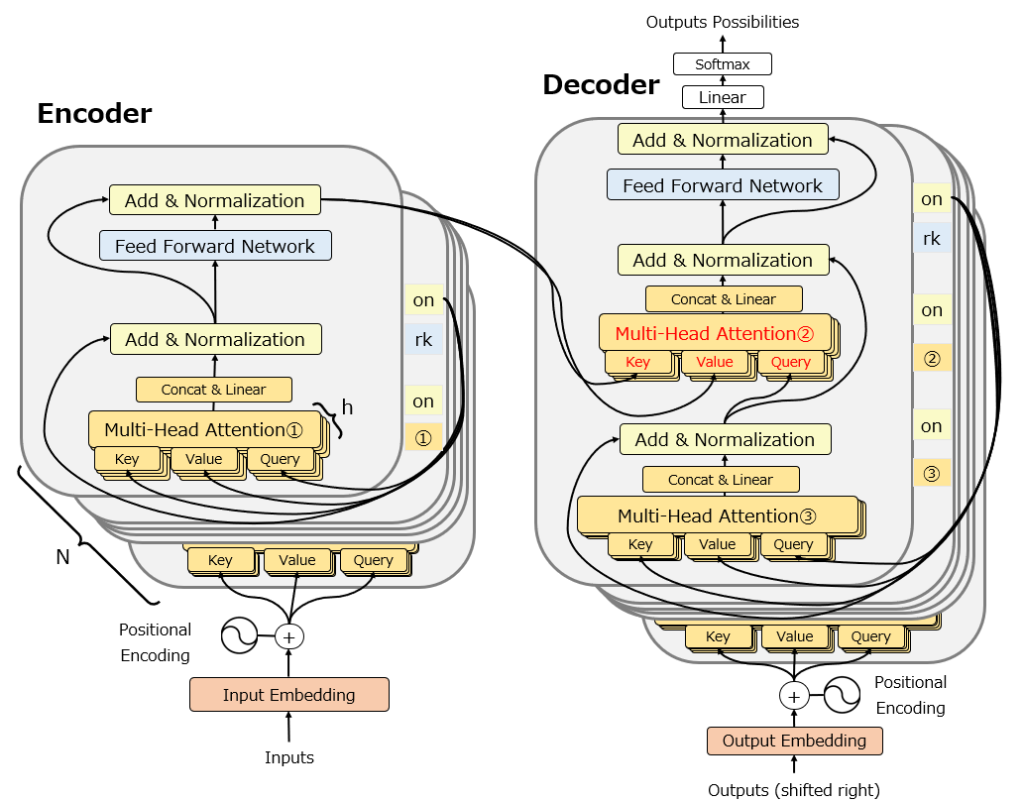
以下の図はTransformerの元論文を少しだけ修正した図です。Multi-Head Attentionが合計3か所組み込まれていることがわかります。ここが、Transformerの最重要要素です。
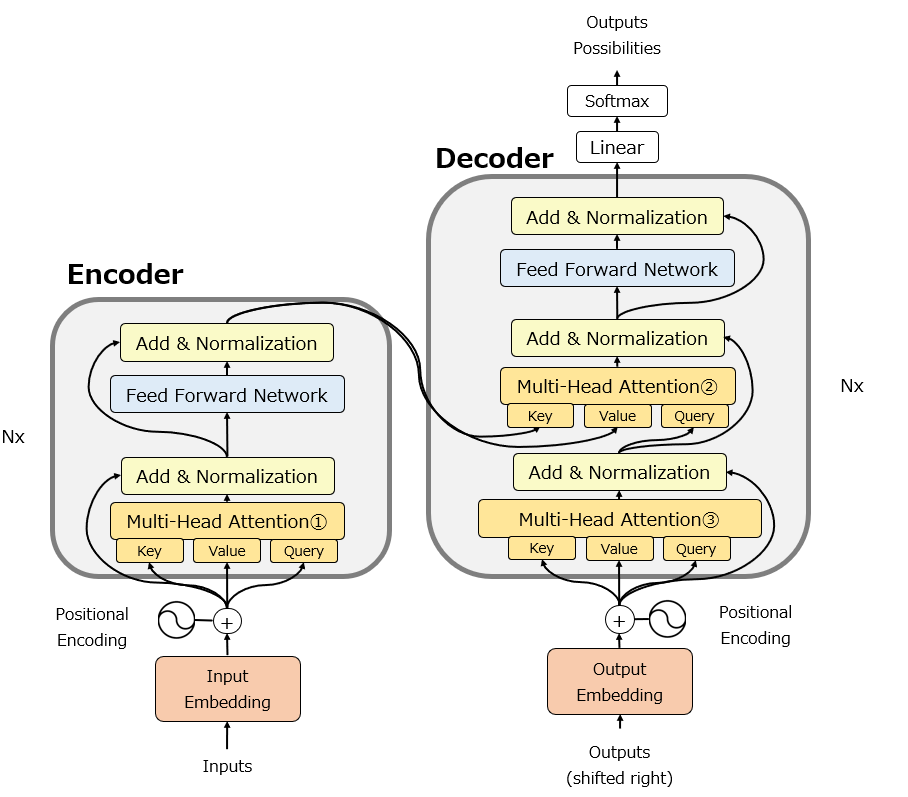
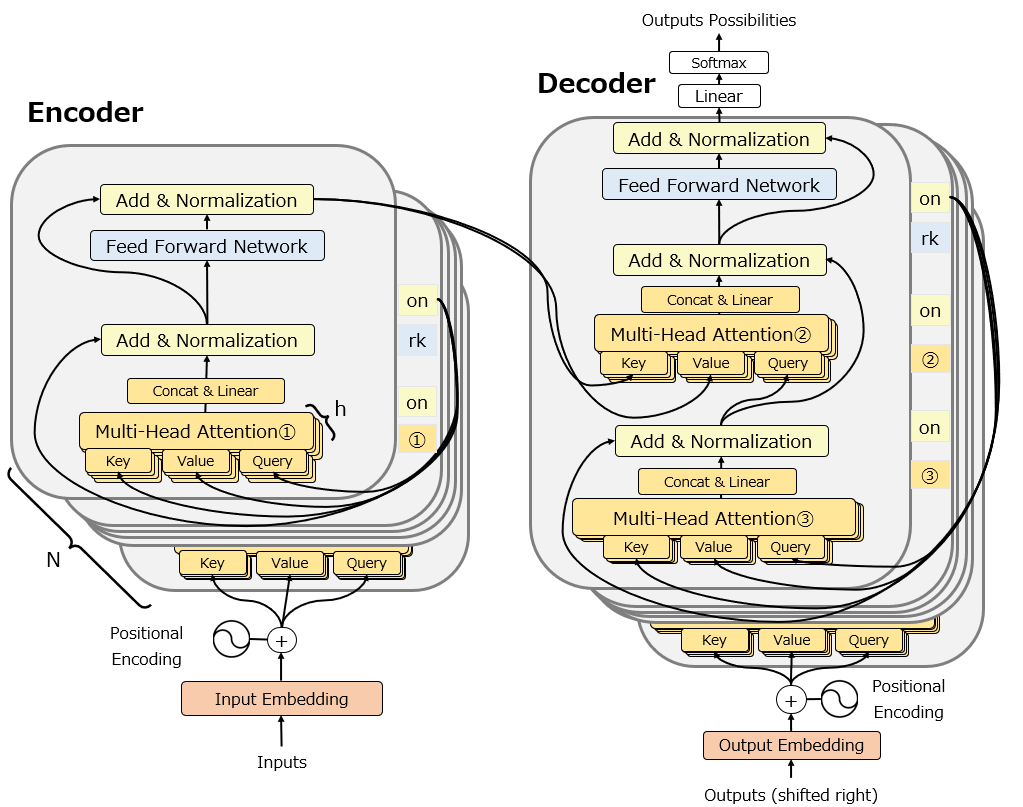
ただし、この図は個人的には省略されている部分が多く想像しにくいと感じますので、かなりbusyになりますが以下の図を使って説明します。
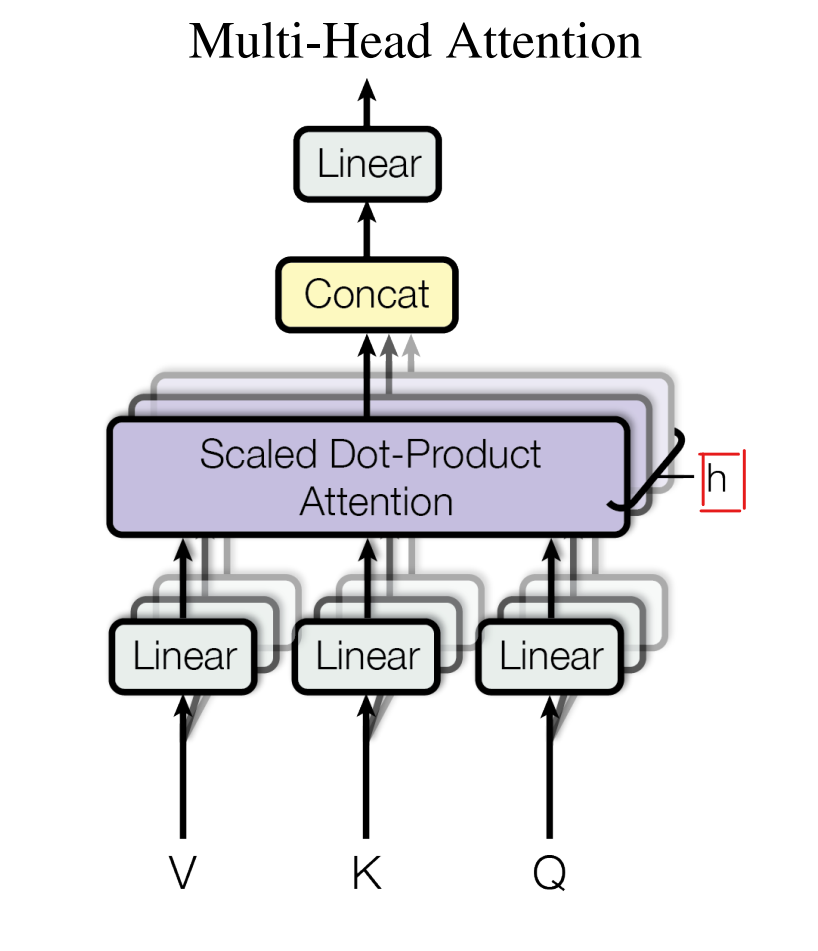
Multi-Head Attentionはその名の通り、Attention機構を重ねて使う機構です。以下は元論文の図ですが、”h”で示されている通り、Attention機構をh回分multi-headに重ねて、それぞれ別の重みを用意して学習し、その後”CONCAT”で結合しています。この構造が、単語間の関係を高速に補足するためのポイントです。
ここで注意しないといけないのは、TransformerでMulti-Headに重ねたAttentionですが、Attentionの構造は元々のAttentionの構造そのままではありません。更に、Transformer内だけで3種類の異なる高校のAttentionを使っています。
そこで以下では、Attentionが発表されたときのAttentionの構造と、Transformerで使われているMulti-Head AttentionのAttention3種類の構造をそれぞれ説明します。
元々のAttention (Source-Target Attention)
Attentionの記事でも紹介した以下の図ですが、これはAttentionの中でもSouce-Target Attentionと呼ばれます。key, value, queryがそれぞれどのように作用しているかを見てみると、Encoder側にあるSource(key, value)を使ってDecoder側にあるTarget(query)を狙うようなAttentionになっている、と捉えると理解しやすいかもしれません。
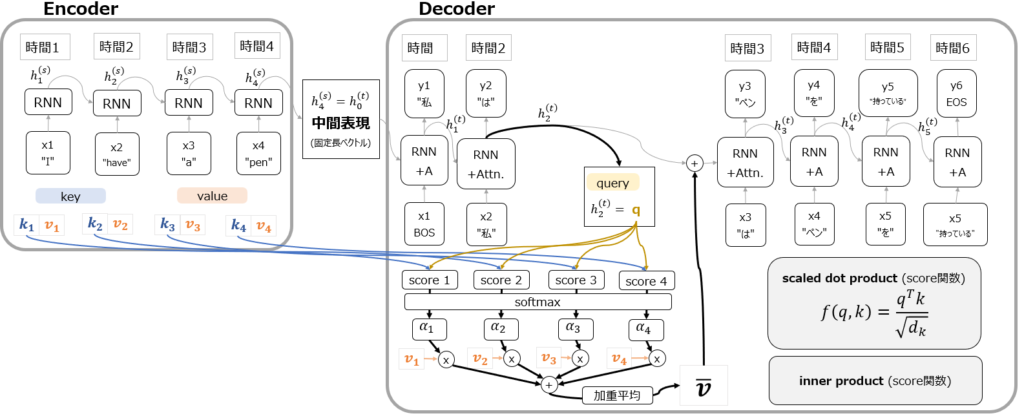
なお、Attentionの記事は以下を参照ください。
Multi-Head Attention
ではここから、Transformerで使用されている3種類のAttention機構を紹介します。
①Self-Attention
まず、Transformerの以下の図の中のMulti-Head Attention①(赤字)について説明します。
この部分のAttentionはSelf-Attentionと呼ばれています。Attentionの元論文で紹介されたSource-Target AttentionはDecoder側に配置されていて、key, valueはEncoderから、queryはDecoderから来ていました。一方TransformerのSelf-Attentionの場合は以下の図の通り、まず全ての要素がEncoderに配置されていて、またkey, value, queryすべてがEncoderの1つ前の層から情報を受け取っています。自分(self=Encoder)で自分に注意を向けるような構造になっていることから、Self-Attention、と呼ばれます。
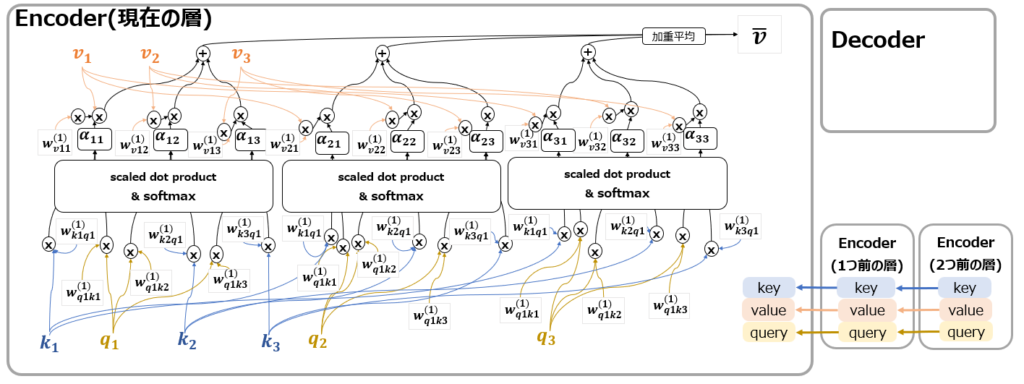
ただし、基本構造はSource-Target Attentionと同じく、keyとqueryの類似度を測り、そこにvalueを掛け合わせたものであることがわかると思います。またSource-Target Attentionの説明図では省略していましたが、key, query, valueに対して多くの重みパラメータwが配置されていることもわかると思います。これらが学習の対象になるわけです。
更に、上の図は言うならば”Single-Head Self Attention“です。これを重ねてMulti-Headにすると、以下のようになります(2つ重ねているのでdouble-head?)。
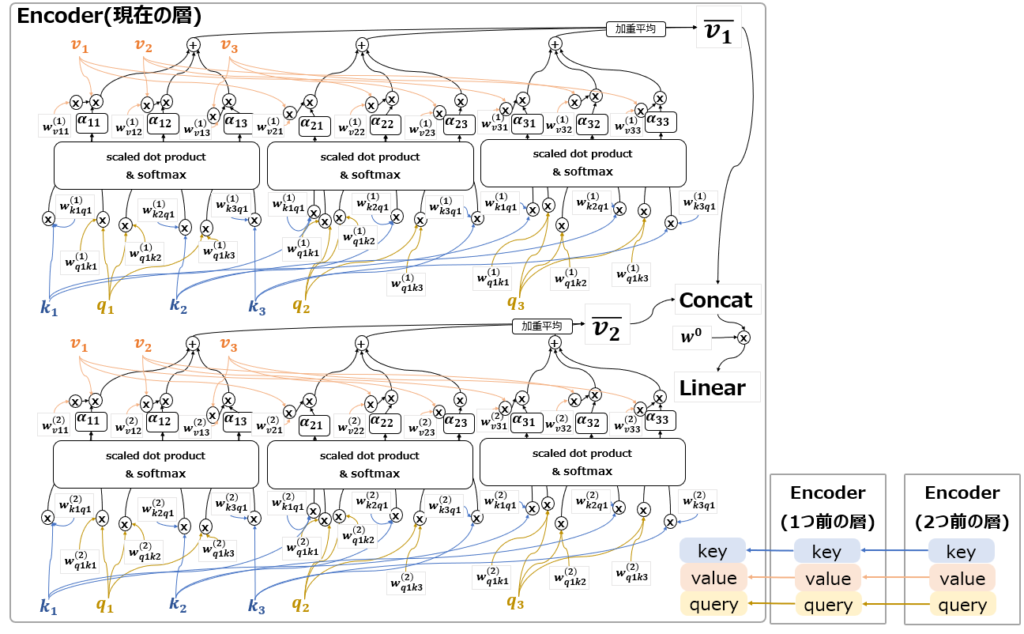
複雑な図の為Multi-Headと言いつつ2つしか書けませんでしたが、元論文ではMulti-Headの高さh=8としています。
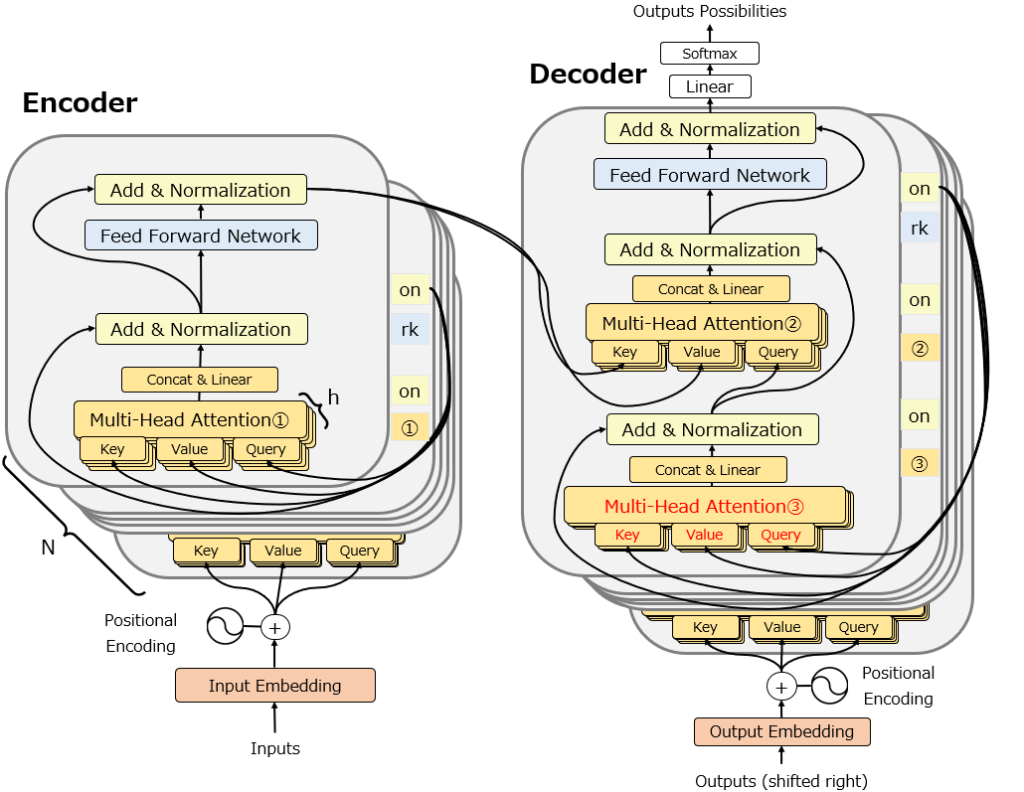
②Cross-Attention
次に、Multi-Head Attention②(赤字)について説明します。
この部分のAttentionはCross-Attentionと呼ばれています。以下の図の通り、基本的にはSelf-Attentionと似ていますが、そもそもがDecoderに配置されていることに加え、keyとvalueはEncoderの出力から、queryはDecoderの前の層から来ています。
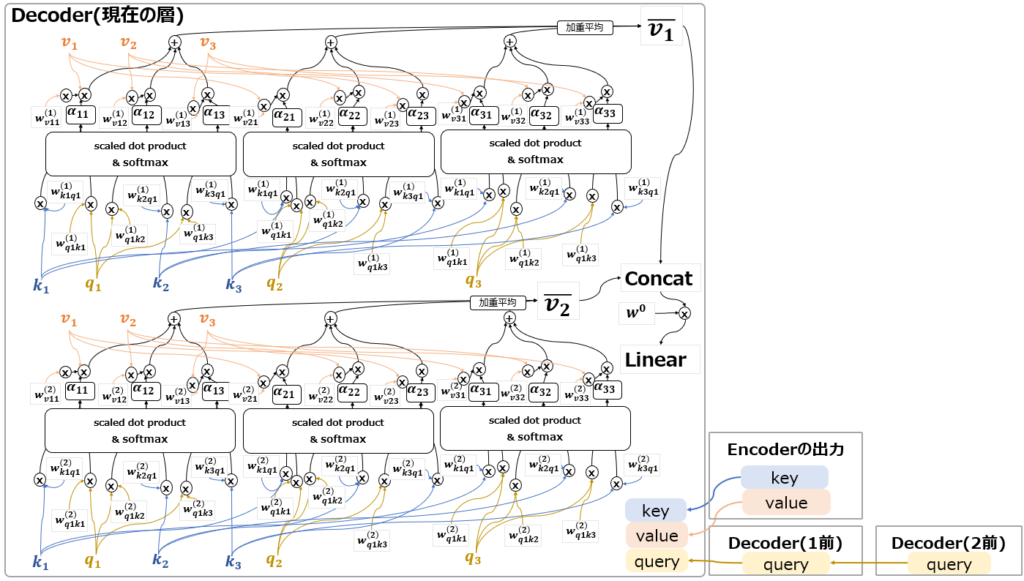
③Masked Self-Attention
最後に、Multi-Head Attention③(赤字)について説明します。
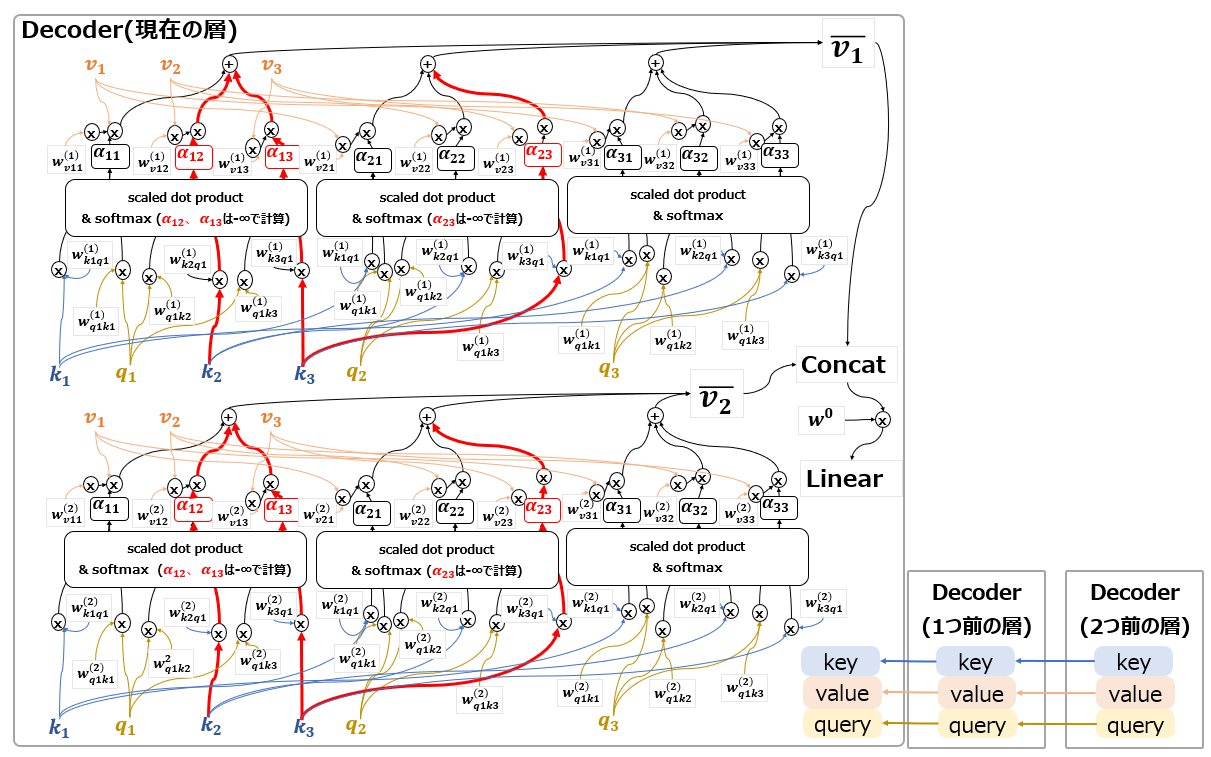
このAttentionはMasked Self-Attentionと呼ばれています。以下の図の通り、基本的にはDecoderに配置されたSelf-Attentionという感じですが、大きく異なるのは”Masked”の部分です。
機械翻訳を想像してもらえればわかりますが、実際にDecoderを使って出力するときは、必ず過去の単語を踏まえて次の単語を出力します。未来の単語を踏まえて出力することはありません。だからこそTransformer以前のモデルは系列データ処理に適性のあるRNNを使用していました。Attentionの元論文でも、Source-Target Attentionの結果をRNNに渡して処理しています。
一方Transformerは、Encoder側ではSelf-Attentionによって過去の入力から未来の入力を参照でき、逆に未来の入力は過去の入力を参照できるので、RNNのように時間単位ごとに処理せずにEncoderへの入力データを一気に学習することができます。
しかし、翻訳文を生成するDecoder側では、結局単語を1つ1つ前から順番に出力する必要があります。このため、Decoder側にRNNと同じように過去の単語にしか注意を向けないような仕掛けが必要になります。ここで出てくるのが、Masked Self-Attentionです。
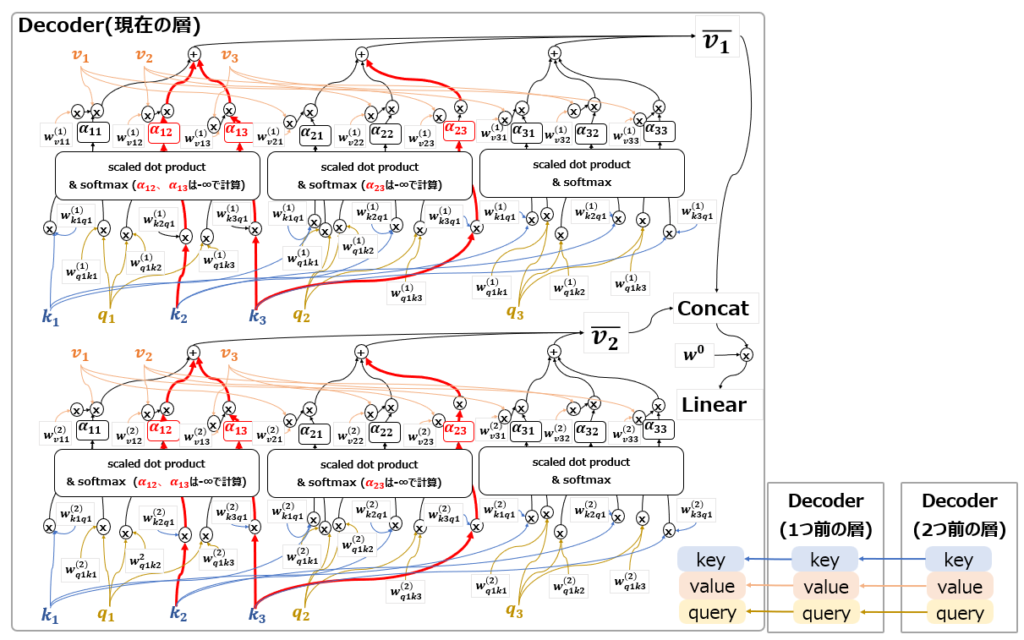
図からわかる通り、未来のデータを参照してほしくない部分には、-∞という値を掛け算することで、事実上無効化、Maskしています。
以上が、Transformerの最重要要素であるMulti-Head Attentionの説明でした。今後の記事で、それ以外のTransformerのアーキテクチャについても説明しますのでお待ちください。
コメント