
今回は言語モデルについて解説します。
言語モデルとは何か
言語モデル(Language Model)は、自然言語処理の分野において文章生成、穴埋め問題、機械翻訳、質問応答などのタスクに応用される確率分布です。具体的には、言語モデルはある文章が途中まで与えられたときの次の単語の確率を計算することができ、最も確率の高い単語を出力します。
言語モデルとして現在名前が知れているのは、Transformerを使ったモデルであるGPTシリーズやBERTでしょう。これらはLLM(大規模言語モデル)と呼ばれており、特にChatGPTの登場で広く認知されるようになりました。
なお自然言語処理(NLP, Natural Language Processing)というのは自然言語をコンピュータに扱わせることを指し、具体的には文書の分類や要約、機械翻訳、対話などが含まれます。
ではそもそも自然言語(natural language)とは何かというと、英語、フランス語、日本語、手話など、人間が互いにコミュニケーションをとるための手段で、自然発生的に形成された言語のことを指します。一方特定の目的のために人間が作り出した言語のことを人工言語(artificial language)と呼びます。例としてはエスペラント、数学の数式や表記方法、モールス信号等が挙げられますが、特にコンピュータが通常処理する人工言語がプログラミング言語です。プログラミング言語のような人工言語は高度に構造化されており、曖昧さがなく、自然言語のような豊かさや複雑さがありません。そのため、自然言語をコンピュータに処理させるアルゴリズムやモデルの開発が目指されてきたのです。
LLM以前の言語モデル
LLM(Large Language Model、大規模言語モデル)登場以前にも言語モデルは存在しましたので、以下で紹介します。
n-gram
n-gramの歴史は古く、情報理論で有名なクロードシャノンが1950年代に提唱しました。n-gramは、ある単語列を与えた時の予測したい単語について、その単語からn個前までの単語から次の単語を予測するという言語モデルです。n=1であれば直前の1つの単語から次の単語を予測、n=2であれば直前の2つの単語から次の単語を、最尤推定法によって予測します。
n-gramはその単純さと計算の効率性ゆえに大量のテキストを処理するのに適し、また言語に依存しないため、どのような言語にも適用することができます。一方n-gramは遠く離れた単語間の関係を捉えられず、また未知語に弱いというデメリットがある為、現在のLLMで見られるような使い方はできませんでした。
RNN-LM
RNN-LMはword2vecを提唱したミコロフ氏らによって2010年に発表されました。その名の通り、確率の計算にRNNを使用することで、精度が大幅に向上することが示されました。これはRNNが単語間の長期依存性を捉えることができることによるものです。RNNについては以下を参照ください。
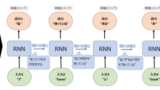
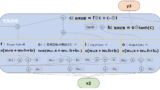
RNN-LMの論文中で使用したモデルは、BPTTなしのSimple RNNでした。単純なRNNでもn-gramのようなそれまでの手法の精度を更新しましたが、更にLSTMやGRUを使うことでより効果が高まります。LSTMやGRUについては以下を参照ください。

大規模言語モデル(LLM)
大規模言語モデル(LLM, Large-scaled Language Model)は膨大な量のテキストデータから学習し、精度の高い予測や出力を行うことができます。有名なのはOpenAIのGPT(Generative Pre-trained Transformer)シリーズやGoogleのBERT(Bidirectional Encoder Representations from Transformers)です。最近のLLMの進歩により、言語翻訳、感情分析、質問応答、テキスト分類などの自然言語処理タスクで最先端の性能を達成しています。
では大規模というのがどのくらいかを紹介します。今話題のOpenAIのサービスであるChatGPTはGPT-3.5/-4という言語モデルを基にしています。その1つ前のモデルであるGPT-3の時点で、パラメータ数は驚異の1,750億(Transformer96層、内部ベクトル表現12,288次元)、使用したデータはネット上の大量のデータやwikipedia等々の2,000単語超を学習用データとして使っています。書籍に換算したら恐らく1,000万冊を超えます。あまりに大きすぎて、どのくらい大きいのかよくわかりませんが、人間には全く達成不可能な学習量であることがわかります。またこれらの学習は費用も莫大であり、日本円で約5億円とも言われています。
LLM発展の経緯
元々ディープラーニングによる言語モデルは、数万、数十万という大量のデータを自前で揃えて初めて精度を確保できるもので、誰でも使えるものではありませんでした。
それが2018年に登場したGPT及びBERTで、事前学習済のモデルを用意して、手元では数百~数千件のデータを使ってファインチューニングすることで高精度が出るようになりました。これは非常に大きな進展で、事前学習やファインチューニングによる転移学習という手法によって、限られたリソースでもある程度の手間をかけることで高度なAIを使うことができるようになりました。
更にGPT-3になると、Few Shot/One shot、つまりほんの1-2個の自然言語による例を出すことで(もしくは例なしのZero Shotで)、高精度な出力を出せるようになりました。例えば2020年8月にはGPT-3によるブログ記事生成では、記事のタイトルと最初の数行の内容だけを与えただけで生成された記事がニュースサイトのランキングで1位になったことで話題になりました。
ChatGPTの登場
GPT-3の登場によって、ついにはファインチューニングもなしに、事前学習されたモデルさえあれば文章を生成することができるようになりました。これは、プログラミング言語のスキルやディープラーニングの構造への理解がなくとも、言語モデルを誰でも使える可能性を示していました。
こういった状況で2022年の年末にリリースされたのが、ChatGPTです。これはGPT-3のアップデート版であるGPT-3.5という事前学習済モデルを使ったチャットサービスで、その概要は恐らくここで説明するまでもないでしょう。正に革命的なサービスであり、だからこそリリースから2ヶ月でユーザー1億人を突破するほどのモーメントになったのでしょう。
なお、ほんのわずかな使い方の例として、以下のような記事を作成していますので、ご興味があれば参照ください。



LLMの思想、展望、課題
Scaling Law(スケーリング測)
Scaling Lawは直訳すると、スケーリングに関する法則です。これは言語モデルが大きくなるにつれて、その性能も改善するという考え方です。つまり、モデルが大きくなればなるほど、それが解決できる語学タスクも増えていくという予測ができるのです。
ただし、これは一概に”モデルが2倍大きくなれば、性能も2倍上がる”というわけではありません。むしろ、モデルが大きくなるにつれて性能は上がるものの、その上昇幅は徐々に小さくなるという傾向があります。しかし、それでもモデルを大きくすることで、言語モデリング、質問応答、機械翻訳などのさまざまな言語タスクで見られる性能は確実に上がります。このモデルの大きさと言語モデルの精度に綺麗な関係性がみられるとしたのが、OpenAIの研究者らが発表した2020年の論文”Scaling Laws for Neural Language Models”です。
In Context Learning / Meta Learning / Multi-Task Learning
In Context Learning、Meta learning、Multi-Task Learningは、LLM(大規模言語モデル)をどのように学習させるかという学習戦略です。
In Context Learning(文脈依存学習)
言語モデルが特定の状況や分野で学習し、その範囲内でより正確な推測を行う能力を強化するというものです。これは、例えばチャットボットやバーチャルアシスタントなどのアプリケーションで、モデルがユーザーの特定の状況を把握し、適切な反応を提供することが求められる場合に非常に役立ちます。
Meta Learning(メタ学習)
言語モデル自身が他の課題から得た知識や経験を活かし、新しい課題や分野に対して最小限の学習データだけで素早く対応する学習方法を身につけることです。これは、例えばオンライン学習やレコメンドシステムなど、新しい環境や課題に迅速に対応することが求められる場面で使われます。
Multi-Task Learning(マルチタスク学習)
個別の課題ごとに別々のモデルを学習させるのではなく、複数の関連した課題を同時に処理できるように言語モデルを訓練することです。異なる課題間で共有できる知識やパターンの利用方法を学び、モデルの効率性と有効性が向上する可能性があります。たとえば、感情分析とテキストの分類を同時に行う能力を持つモデルは、テキスト内の同じ特徴やパターンを利用して、両方の課題を一度に処理する学習方法を身につけることができます。
LLMの課題
LLMは、自然言語処理の領域で驚くべきスピードで進歩していますが、以下のように課題も残っています
- バイアス: トレーニングデータに存在するバイアスがモデルに取り込まれる可能性があり、これがモデルの出力に影響を与える可能性があります。これは特に、性別、人種、宗教などの敏感な主題に関連する課題で顕著です。
- データのプライバシー: LLMは大量のテキストデータを学習しますが、これらのデータにはプライバシーに関連する情報が含まれる可能性があります。モデルがこれらの情報を暗示または明示的に出力するリスクは、重大なプライバシー侵害をもたらす可能性があります。
- エネルギー消費と環境への影響: LLMを訓練するためには大量の計算リソースが必要で、これは大量の電力消費につながります。これにより、環境に対する負荷が増大し、カーボンフットプリントが大きくなる可能性があります。
- モデルの理解と透明性: LLMの中身は完全なブラックボックスで、どのようにして特定の結論や予測に至るかを理解するのは実質不可能です。
- 汎用性と特化: LLMは幅広いタスクでパフォーマンスを発揮する一方、特定のタスクやドメインに特化したモデルを訓練することは困難な場合があります。
- モデルの悪用: LLMの能力が高まると、それらは不適切または危害を与えるような内容を生成するツールとして悪用される可能性があります。例えば、偽のニュース記事の生成、誤導的な情報の広まりを助長するための文章生成、またはオンラインでのハラスメントなどに利用される可能性があります。

コメント