今回から、画像認識の分野で用いられるAIであるCNN(Convolutional Neural Network, 畳み込みニューラルネットワーク)について解説します。過去に説明したニューラルネットワークの続きとしてご覧ください。前回までの内容は以下から参照ください。

DNN(ディープニューラルネットワーク)
過去に紹介したニューラルネットワークは、以下のように各層のニューロン同士が全て結びついて密なネットワークを形成することで関数としての表現力を増し、多様なAIモデルを構築することができます。
このような各ニューロンを全て結びつけることを全結合と呼び、全結合により構築される多層のニューラルネットワークモデルのことを、DNN(ディープニューラルネットワーク)と呼びます。

DNNのデメリット
しかし、全結合によるDNNは、画像認識の分野では現在ほとんど使われていません。これはDNNのデメリットによります。
画像認識タスクのイメージ
DNNのデメリットを説明する前に、画像認識というのがどういったタスクであるかを考えてみます。以下はアラビア数字の”6″ですが、こういった数字を識別するようなAIモデルを構築する時には、”位置情報”が重要になります。

“位置情報”とはどういうことか、もう少し具体的に説明します。AIモデルが画像を”アラビア数字の6である”と認識できるようになるためには、どのような位置情報があればいいでしょうか。
例えば以下のように、画像の中央左寄りに”まっすぐな線”があれば”6″である可能性が高いかもしれません。ただしこれだけでは”0″・”1″・”4″・”5″の可能性も高いので、確定することはできません。

続いて画像の左上に注目してみましょう。この位置に情報がなければ6の可能性が高いかもしれません。ただしこれでも、”1″・”4″・”5″の可能性も高いので、確定することはできません。

画像下部全体にかけて”円形”がある、という位置情報はどうでしょうか?”6″以外で画面下部に円形が現れるのは”8″か、もしかしたら小さく書かれた”0″かもしれません。

上では3つの位置情報の例を示しました。以下に再掲します。
- 中央左寄りに”まっすぐな線”がある
- 右上にデータがない
- 下部全体に”円形”がある
位置情報とは言い換えれば”この位置にこういったデータがある”という情報であることがわかります。この位置情報に関する各数字の特徴を学習することで、ある画像が6であるか、他の数字であるかを認識することができるようになるのです。
上で示した3つの位置情報に関する特徴を使うと、以下の画像はどう認識できるでしょうか?少し大げさに、様々な形・位置の”6″を書いてみました。
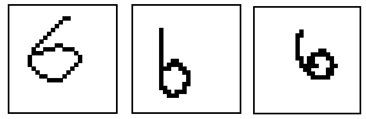
人間であれば、上の画像がアラビア数字であるという前提を与えられれば、容易く”6″であることを理解することができます。
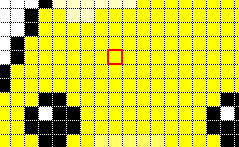
では上述した3つの位置情報を使い、AIは”6″を正しく認識できるでしょうか?以下に、赤枠を示しています。
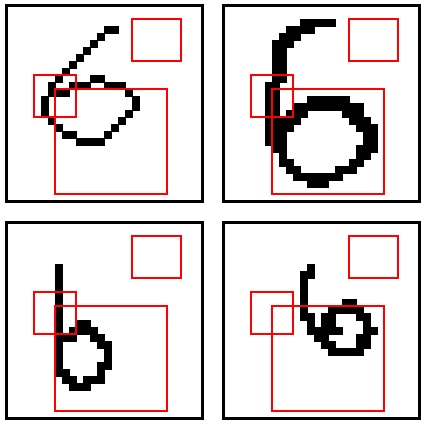
- 中央左寄りにまっすぐな線がある
- 右上にデータがない
- 下部全体に円形がある
“中央左寄りにまっすぐな線”については、右下の偏った画像が当てはまりません。2つ目の”右上にデータがない”についてはすべて画像で当てはまりそうです。3つ目の”下部全体に円形”については、左上の画像が当てはまっていないように見えます。
このようにして、“6っぽさ”を検出することで、AIはある画像が”6″であるかどうかを認識することができそうです。
位置関係を反映できない
上述の様に、位置情報を使ってAIは画像を認識します。
では、なぜ位置情報を使って画像認識をするときに、DNNではダメなのでしょうか。
以下に、全結合の図を再掲します。赤枠部分に入力データが一列に並んでいることに注目してください。
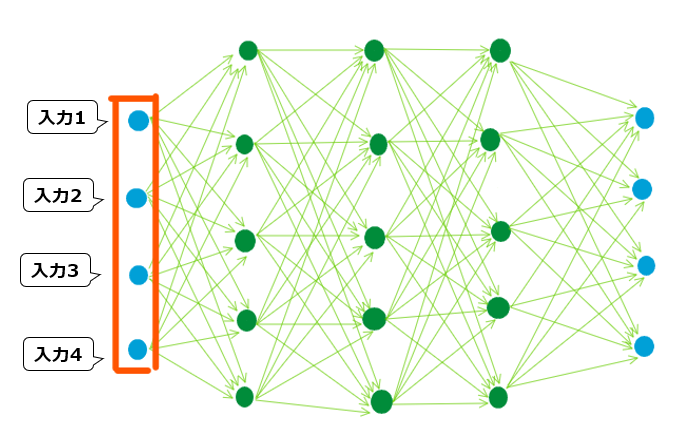
ここで画像における入力データは、以下のように各画素の情報を縦に取得した値となります。
この方法が問題なのは、”位置関係を反映させられない”ということです。
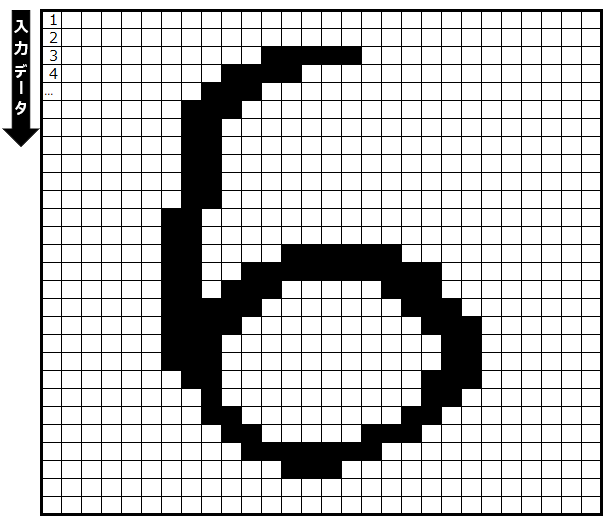
上の6の画像について、以下の赤枠部分にフォーカスしてみましょう。
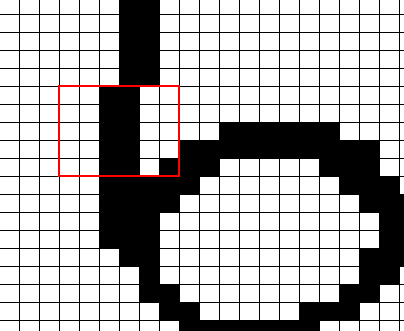
赤枠内の入力データの番号とデータ自体は以下のようになっています。なお、入力データとしては、白黒であれば1/0で表現できるでしょうし、グレースケールなら0-255、フルカラーならRGBの(0,0,0)~(255,255,255)の形式になります。今回の例では白黒なので、理解を簡単にするために白=0、黒=1と想定します。

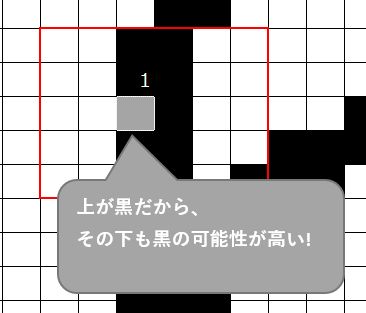
この時、上述の様に枠内にまっすぐな線が現れていたら6の確率が高いと判断したいことを思い出してください。そうであれば、例えば赤枠内の”入力182番”が白か黒かという情報は、この赤枠外の入力よりも重要なはずです。例えばもしこの画像が仮に”6″だとしたら、入力182番が黒なのだから、その1個下の”入力183番”も黒の可能性が高いと言えます。
一方、赤枠外の、離れた画素ではどうでしょうか?
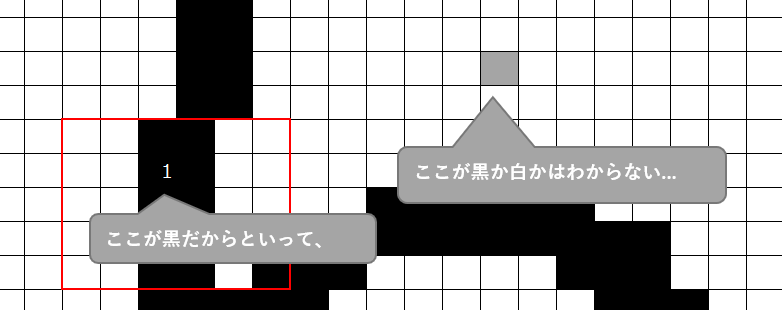
この話はカラー画像の方がイメージしやすいかもしれません。 例えば以下のネズミのキャラクターについて、

以下の赤枠の付近の画素も、赤枠内と同じような黄色である可能性が高いことが直感的に理解できるのではないでしょうか。
一方DNNの図を見ると、入力データは1列に並べられていて、”位置関係”に関係なく、全ての入力データが平等に扱われています。1つ下の入力であるとか、1つ右の入力であるということは考慮されません。

そのため、画像認識において重要な”位置関係”をディープニューラルネットワーク上で反映することができないのです。これが、DNNのデメリットの1つ目となります。
位置ずれに弱い
もう1つのDNNのデメリットは位置のずれに弱いということです。以下の画像は、上の6の画像をそれぞれ左右に2列ずつずらしています。人間であれば、何の問題もなくこれらの画像が上と同じ6であることを認識することができます。
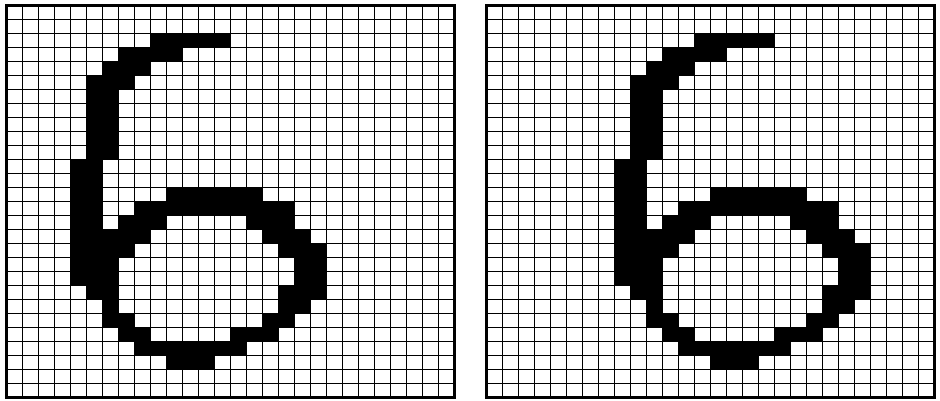
では、DNNの場合どのような問題があるのか。それを理解するために、今度は以下の赤枠にフォーカスしてみましょう。
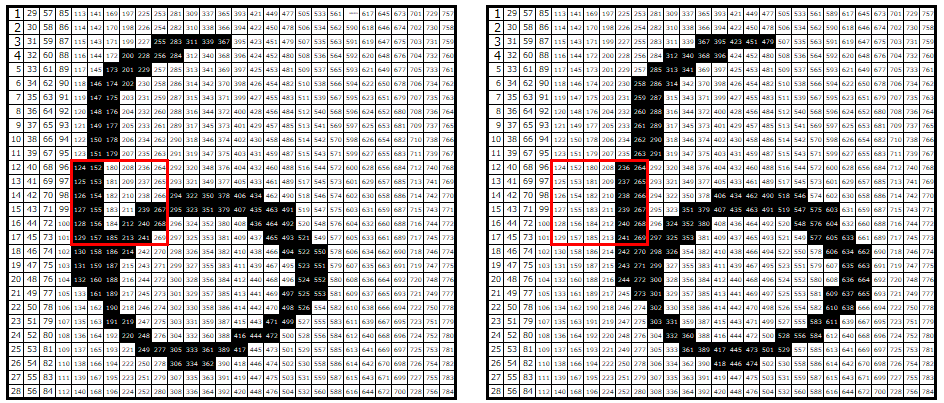
赤枠を拡大すると以下のようになっています。わかりやすいように、入力データ番号を予め振ってあります。
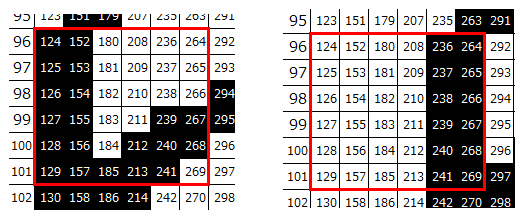
黒い部分と白い部分が大きく異なっていることがわかると思います。左の画像では赤枠内の左の2列に黒が多いのに対し、右の画像では右の2列に黒が多くなっています。
一方、度々掲載しているようにDNNでは入力データを縦1列に並べて処理するので、これを”横にずれた”と認識するのではなく、”全く異なる入力データ”と認識してしまうのです。

今後の記事で紹介するようにCNNではあまり影響を受けずに認識することができる”位置ずれ”の画像を、DNNの場合では全く異なる入力データとして認識してしまうということです。CNNと比較して、DNNでは6を認識するためのルールを学習することがとても難しいということができます。
これらが、DNNのデメリットです。
画像認識にはCNN
上述のDNNのデメリットを回避することができるのが、CNN(Convolutional Neural Network, 畳み込みニューラルネットワーク)です。その根幹となるConvolution(畳み込み)について、今後の記事で解説します。少々お待ちください。

コメント