
今回は機械学習の中の教師あり学習の分野における、ランダムフォレスト(Random forest)について解説します。機械学習の概要や基本的な用語の説明については以下の記事を参照ください。

ランダムフォレストとは何か
ランダムフォレストは、決定木を弱学習器としてアンサンブル学習の一種であるバギングを用いた手法です。決定木とアンサンブル学習については以下の記事を参照ください。
決定木
ランダムフォレストで用いられる決定木というアルゴリズムは、データの集合に対してある条件を適用して当てはまるか否かで2グループに分けるというプロセスを繰り返して、データを分類していきます。例えば以下のように重量と糖度のデータを有する3種類の果物について、重量と糖度を説明変数、果物の種類を目的変数とした予測モデルを構築することを想定します。
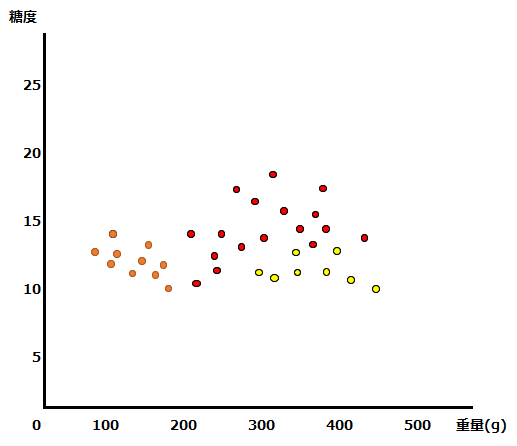
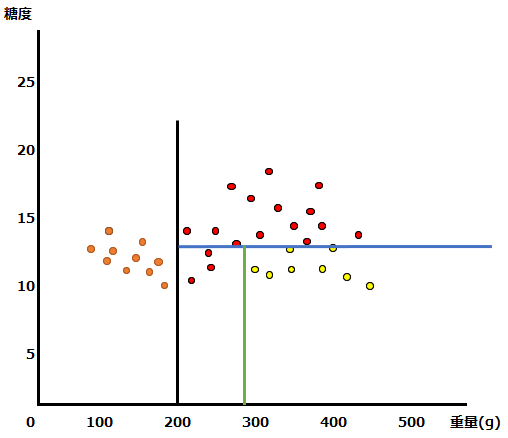
このデータに対して、糖度と重量についての条件を設定することで、重量と糖度のデータから果物の種類を予測するモデルを構築することができます。
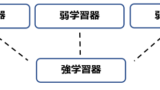
バギング(アンサンブル学習)
ランダムフォレストで用いられるバギング(Bagging)の”Bag”は”Bootstrap Aggregating”の略です。ブートストラップ法というのは、復元抽出法によってランダムにデータを抽出して作成したデータセットを基に学習や分析を進める手法です。
復元抽出法というのは一言でいうと重複してもよい抽出のことで、くじ引きでいうと一度引いたくじを箱の中に戻してから次のくじ引きをすることです。1人が同じくじを何度も引く可能性もありますし、最初に引いた人と次に引いた人が同じくじを引く可能性もあるということになります。
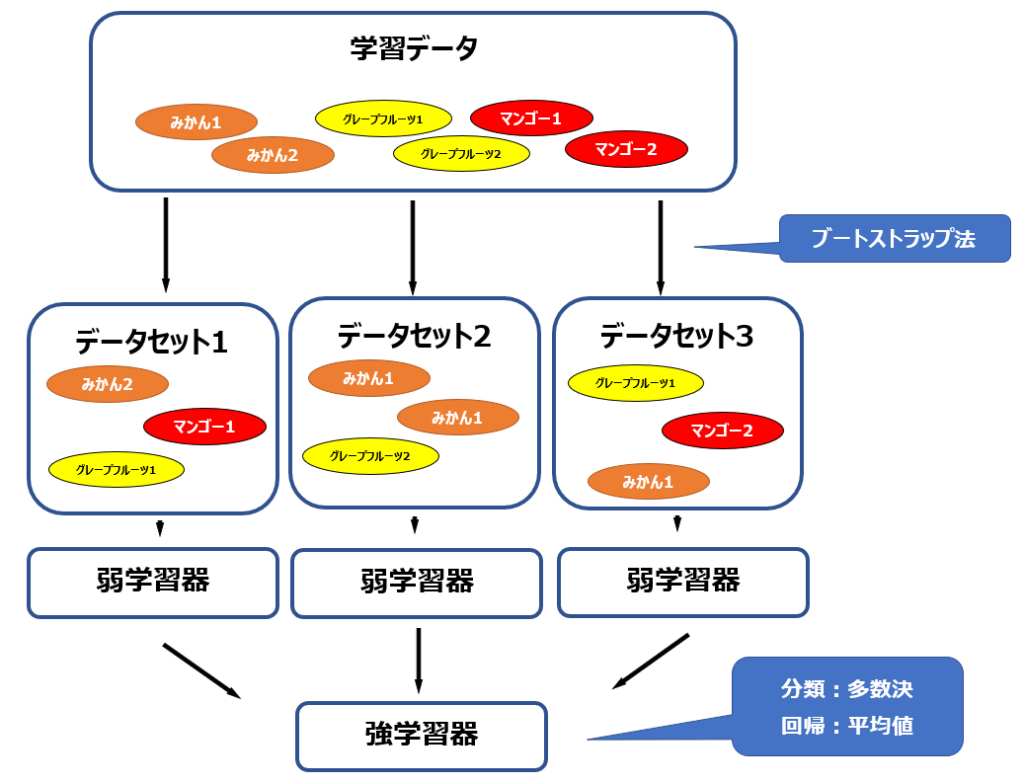
ブートストラップ法によって作成したデータセットに対して、弱学習器と呼ばれる、単体では精度の低いモデルを適用します。ランダムフォレストの場合は、この弱学習器として決定木が使われます。
最終的には、複数の弱学習器(決定木)による予測結果に対し、分類問題であれば多数決で、回帰問題であれば平均値を用いることによって予測値を出力します。


コメント