今回は機械学習の中の教師あり学習の分野における、kNN法(k-Nearest Neighbor method, k近傍法)について解説します。機械学習の概要や基本的な用語の説明については以下の記事を参照ください。

kNN法とは何か
kNN法というのは、特徴区間における最も近い訓練例に基づいた分類アルゴリズムの1つです。
K-NNと頻繁に呼ばれ、似たようなデータをK個集め、それらの多数決から目的とする値を求めるアルゴリズムとなっています。
アルゴリズム
- 入力データと学習データの距離を計算する
- 入力データに近い方からk個の学習データを取得する
- 学習データのラベルで多数決を行い、分類結果とする
kNN法のイメージ
手持ちの学習データで以下のように赤のデータと黒のデータが分布していたとします。
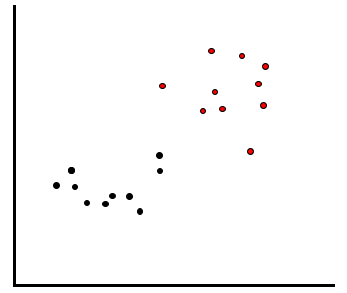
ここで、予測対称である未知のデータが以下の黄色の□ように得られたとします。このデータは赤と黒、どちらと予測すればよいでしょうか。
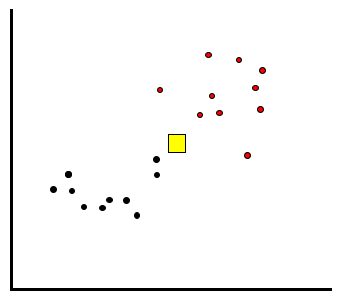
kNN法では、予め決めるパラメータであるkに従って、未知のデータから近いデータk個を取得し、多数決で未知のデータのクラスを予測します。
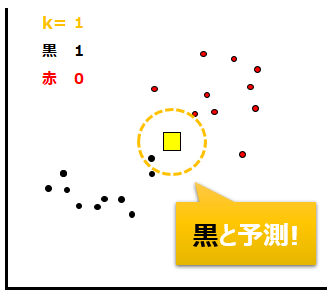
例えばk=1だったら、黄色の途データから最も近い1つのデータによって予測します。すると以下のように黒が最も近いので、未知のデータも黒と予測されます。
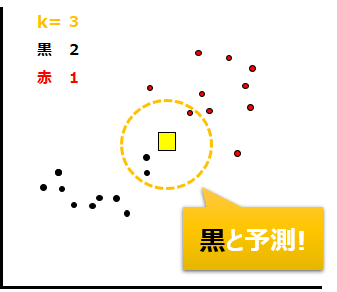
もしk=3だったら、以下のように最も近い3つのデータを用います。黒が2つ、赤が1つなので、上と同じく黄色の途データは黒であると予測されます。
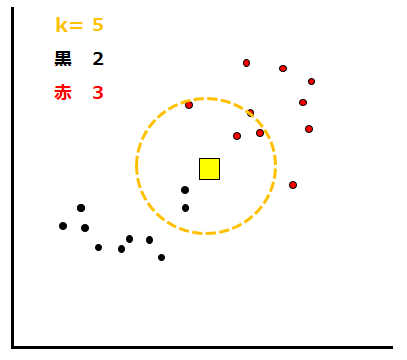
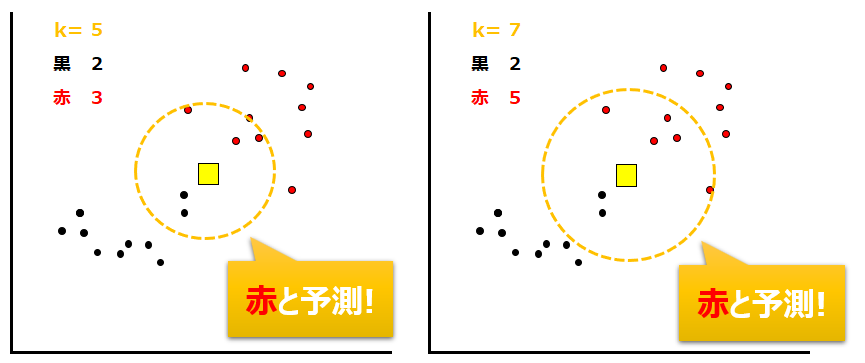
同様にk=5及びk=7の場合も下に示します。今度は赤いデータが多く含まれるので、予測結果も赤となります。
これがkNN法です。
なお、上の図からもわかる通り、多数決を行うため、kの値は奇数が推奨されます。
また、このk値はGridSearchによって最適な値を探索することが可能です。
kNN法のメリットとデメリット
メリット
kNN法のメリットは何と言っても、直感的に理解しやすい点です。近くのデータを取ってきたら”XXのデータが多かったので、XXと予測する”というアルゴリズムは人間がイメージしやすく、受け入れやすい内容になっています。
また複雑な関数を必要としないため学習も不要、すぐにモデルを構築し始められる点もメリットです。
デメリット
一方、機械が一旦すべてのデータとの距離を計算しないといけないので、データの量が多いと計算コストが非常に高くなってしまうことがデメリットとして挙げられます。データ量が多い場合は不適切といえるでしょう。

コメント