
過去の記事で物体検出、セマンティックセグメンテーション、インスタンスセグメンテーションの違いについて解説しました。

今回はセマンティックセグメンテーションの各モデルについて解説します。
セマンティックセグメンテーション
復習になりますが、セマンティックセグメンテーションモデル(Semantic Segmentation Model)は、画像中に何の種類の物体が含まれるかをピクセル単位で特定する技術で、物体検出よりも画像をより詳細に理解することができます。
“Semantic”は「意味論的」という意味の言葉で、言葉や記号などが持つ意味や関連性を研究する学問領域から来ています。セマンティックセグメンテーションの文脈では、画像の各ピクセルにおける”意味”が”物の種類”や”カテゴリー”として現れるものとして扱っています。言い換えるとセマンティックセグメンテーションは、画像内の各ピクセルが何を表しているのか、つまりどの種類の物体に該当するのかという「意味」を把握するために用いられます。
セマンティックセグメンテーションの代表的なモデルとしては、今回紹介する”FCN(Fully Convolutional Network)”、”U-Net”、”SegNet”などがありますがこれらはいずれもEnd-to-Endモデルで、1つのモデルで入力から出力までを直接生成することができます。これらの登場以前にはRandom Forestやクラスタリングなどがセマンティックセグメンテーションに使用されていましたが、CNNベースの深層学習を用いたEnd-to-Endモデルは大きく精度と効率を向上させました。
Down SamplingとUp Sampling
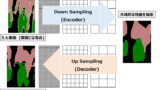
各モデルの説明をする前に、Down SamplingとUp Samplingについて理解しておく必要があります。一言で言えば、CNNを用いた画像分類タスクというのはDown Samplingのみを必要とし、セマンティックセグメンテーションはUp Samplingも必要とします。
ここでDown Samplingは解像度の高い画像を入力としてその解像度を低くするプロセスであり、画像をマクロにとらえること、Up SamplingはDown Samplingで解像度を落としたデータを再び解像度を高くするプロセスです。
詳細は以下の記事を参照ください。
セマンティックセグメンテーションのモデル
では以下では、各モデルについて解説します。
FCN(Fully Convolutional Network)
2015年に発表されたFCNは、ILSVRCで活躍したCNNモデルであるAlexNet、VGG Net、ResNetなどを使い、それらの最終部分にある全結合層(1次元配列にして各クラスの予測をする部分)を畳み込み層に変更し、すべてのアーキテクチャを畳み込み層に変えてしまう(Fully Convolutional)ことで、各クラスの予測ではなく元画像のどこにどういう情報があるかを示すヒートマップを出力させ、これをUp Samplingに使うことでセマンティックセグメンテーションが可能になる、ということを提案しました。
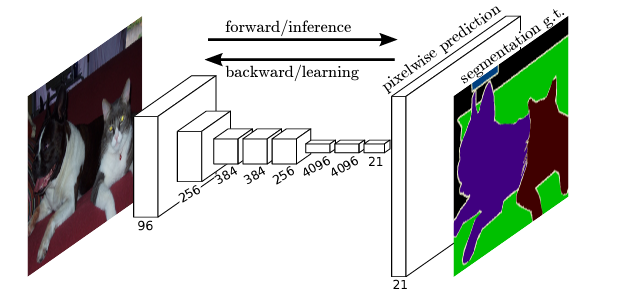
詳細は以下を参照ください。
U-Net
U-Netは2015年に”Convolutional Networks for Biomedical Image Segmentation”というタイトルで発表されました。タイトルからわかる通り、生物医学の分野で適用するためのモデルとして公開されました。U-Netのアーキテクチャは”U”字型の形をしたEncoder-Decoder構造であり、FCNと同じくスキップ接続を有しています。
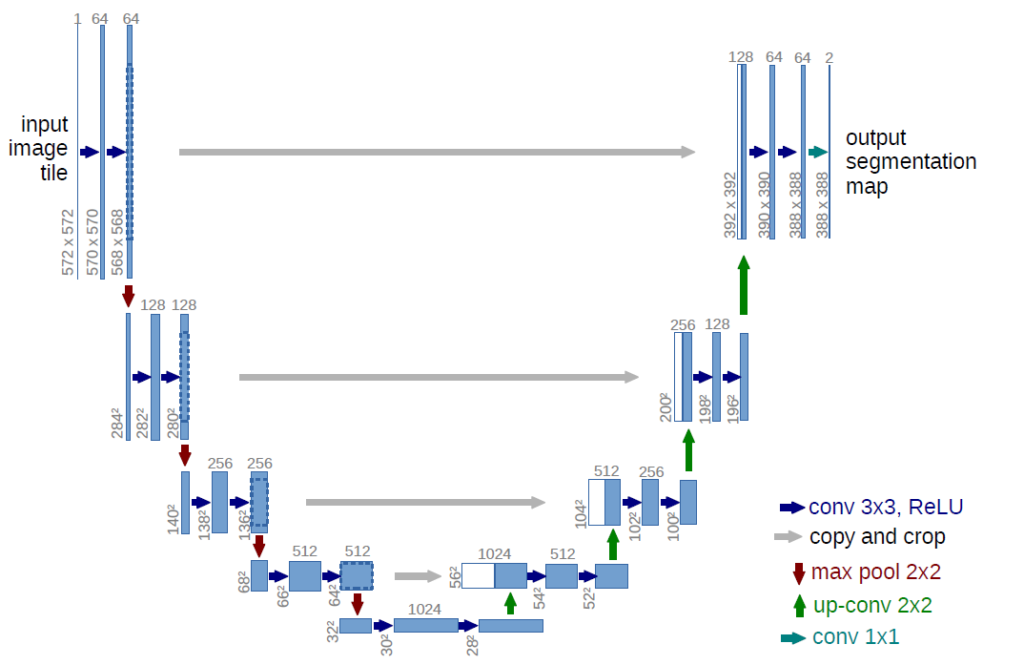
詳細は以下を参照ください。

DeconvNet
2015年に提案されたDeconvNetはFCNの発展形です。アーキテクチャは以下の通り、わかりやすくEncoder-Decoderモデルの構造をしていて、その特徴はDeconvolutionとUnpoolilngです。スキップ接続は採用していません。
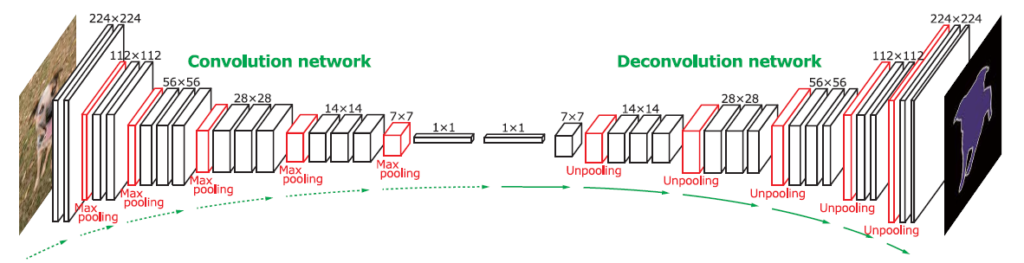
詳細は以下を参照ください。

SegNet
2017年に提案されたSegNetはDeconvNetなど先行モデルを参考にし、特に道路や建物などの屋外環境のセマンティックセグメンテーションに焦点を当てて開発されました。DeconvNetよりも浅い構造にして計算効率を向上させながら、スキップ接続によって精度を保ったことが特徴です。アーキテクチャは以下の通りです。
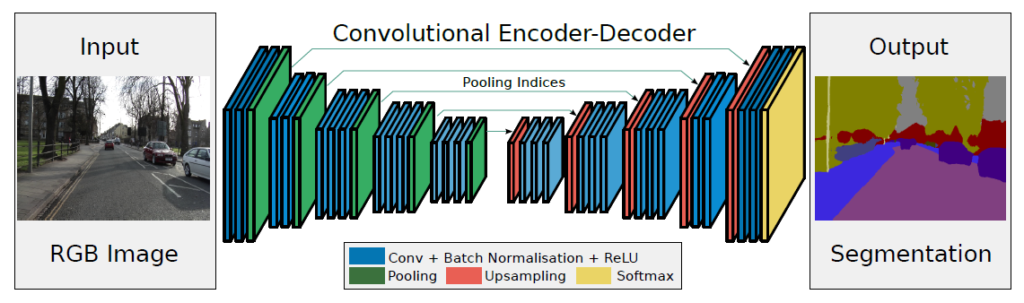
SegNetはFCN、U-Net、DeconvNetなど既存モデルの好いとこどり、バランスを取ったモデルと言えるかもしれません。その効率性と軽量性から、SegNetは現在でもリアルタイム性やリソースの制限が厳しいタスクにおいて広く用いられています。元々開発のターゲットだった自動運転車両の周囲の環境理解にとどまらず、その計算コストの低さからエッジデバイスでのセマンティックセグメンテーションにも適用されています。
詳細は以下を参照ください。
コメント