
2022年末にリリースされたOpenAIのサービスChatGPTが世界中で話題になっています。ChatGPTはGPT-3.5という言語モデルを使ったサービスですが、GPTというのはGenerative Pre-trained Transformerのことです。今後、ChatGPTの元ネタであるTransformerについて解説記事を掲載しますが、今回はその準備としてPositional Encodingを解説します。
Positional Encodingとは何か
以下の図はTransformerの元論文を少しだけ修正した図です。EncoderとDecoderのはじめの部分にそれぞれPositional Encodingが組み込まれていることがわかります。
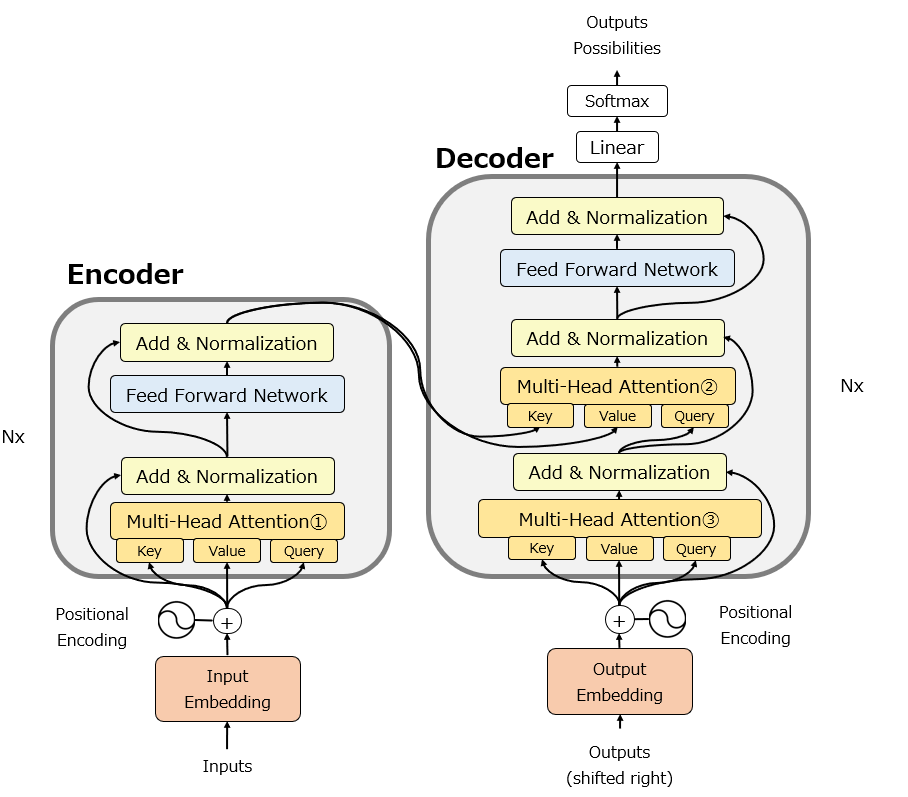
このPositional Encodingを理解するには、まずその直前の”Embedding”、つまりWord Embedding(単語埋め込み)を理解する必要があります。
Word Embeddig(単語埋め込み)
Word Embeddingは日本語では単語埋め込みと訳されます。自然言語処理で単語を扱う際、例えば”apple”という単語を扱うとき、”apple”という言葉をそのままコンピュータに処理させることはできないので、”apple”という単語に固有の番号、正確にはベクトル(方向と大きさを表す数学的表現)を与えて表現します。この処理をWord Embeddingと呼びます。
Word Embeddingのためにすぐに思いつく方法は、以下のようにどこか1つだけ”1″を振って他を0で表すOne Hot Encodingという手法です。

しかしこれだと、単語数分だけの列が必要になってしまい数十万次元という巨大なベクトルが必要になってしまう上に、単語同士の意味を反映させることができません。
2012年に発表されたword2vevはこの単語埋め込みをディープラーニングで実行することで、少ない次元数で単語をコンピュータが扱える次元数で表現できるうえに、それぞれの単語の意味も反映できるという手法でした。非常に有名な話で”王様”と”女王様”という言葉をベクトルで表現すると、”王様”-“男”+”女”が”女王様”に最も近いという数学的な演算を行うことができます。つまり、word2vecの単語埋め込みによって、”女”が”男”に関係するのと同じように、”女王”が”王”に関係することをコンピュータに理解させることができたのです。
word embeddingのの出力としては以下のようなものをイメージしてください。ここでは4単語ですが、もっと多くの単語数を5つの特徴ベクトルだけで表現できるものとして理解してください。
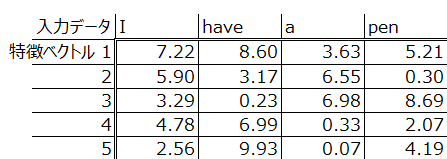
Positional Encoding
Positional Encodingは、以下のようにWord Embeddingで埋め込まれた特徴ベクトルに、更に位置ベクトルを追加します。
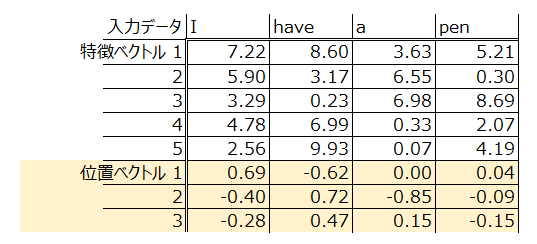
なぜ位置情報を埋め込む必要があるのかというと、RNNを使っていないTransformerの場合、どの単語が何番目だったかという情報を、個別に追加してあげないと保持できないからです。ではなぜ上記のような不思議な数字の羅列で位置情報を追加するのでしょうか。
これを理解するためには、Positional encodingに対する以下2つの要求を理解する必要があります。
- 大きすぎると入力データを意味するベクトルの向きが変わって単語の意味まで変わってしまうので、値は小さい方がいい
- 近い(1番目と2番目)単語も明確に区別したいが、遠い(1番目と100番目)単語も明確に区別したい
大きすぎない位置情報
まず、位置情報を埋め込む際に普通思いつくのが、単純に語順をそのまま付与したらいい、ということです。

なぜこれではまずいのかというと、順番は明確になりますが、位置ベクトルの値が大きすぎて、特徴ベクトル、つまり単語の意味にまで影響を与えてしまう可能性があるからです。上の図では4単語までですが、これがもっと多くなると、100とか1,000とかになり、コンピュータは”位置ベクトルに異常に大きな値がある”と認識し、それを過度に重要な値として処理してしまいます。そのため、位置ベクトルは大きすぎない値にする必要があります。
近い(1番目と2番目)単語を明確に区別したい
位置情報を大きすぎない値で表現したいのであれば、以下のように語順を小数点で表現すればいいのではないかという案も出ます。
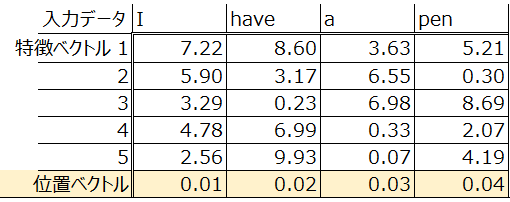
しかしこの場合問題になるのが、近い単語同士をコンピュータが明確に区別できないということです。”I”と”have”の位置情報が近いからと言ってコンピュータが”この2単語の位置に大きな違いはない”と理解してしまい ”Have I a pen”と出力してしまうようなことを避ける必要があります。
ここで、大きすぎない値で、かつ近い単語の位置を区別する方法として考えつくのが(文系には思いつきませんが)、三角関数なのです。以下はsin関数とcos関数がどのような出力をするのかを図示しています。縦軸yが、上述の位置ベクトルの値、横軸tが語順と捉えてください。上の文例で言えば、t=0が”I”、t=1が”have”ということです。
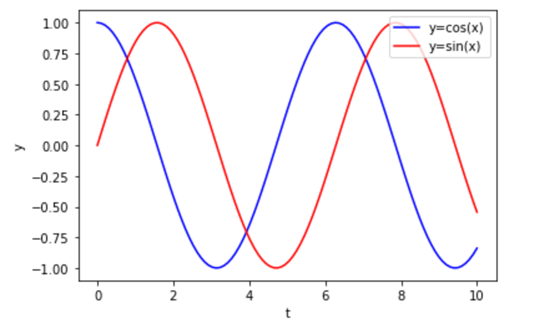
この時、sin関数を使うことで、まず1つ目の条件である”大きすぎない値”についてはクリアできます。sin関数やcos関数の出力は、必ず-1~+1の値の値となります。また、1単語目の”I”の時は出力値”0″、2単語目の”have”の時は出力値”1″、となり、近い単語同士を明確に区別しやすくなりました。
近い(1番目と2番目)単語も明確に区別したいが、遠い(1番目と100番目)単語も明確に区別したい
しかし、単にsin関数を使うだけでは、近い単語同士と遠い単語同士を同時に明確に区別できません。以下のように、例えばtが0の時以外にもy=0の点はたくさん出現し、これらとt=0を区別できません。

そこで、sin関数をたくさん重ねて使うことが提案されました。それぞれsin関数に投入するxを何倍かにすることで、sin関数の波の振幅をコントロールできています。
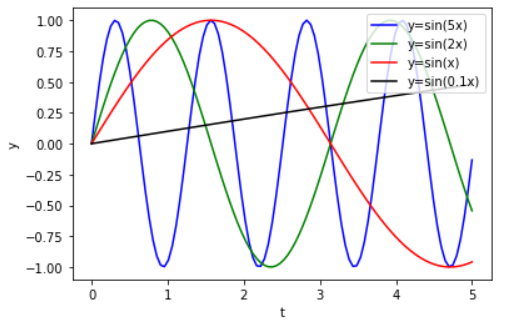
Positional encodingの例
以下では、具体的に4つのsin関数を使って語順をどのように埋め込むことができるか、イメージを説明します。
まず1語目と2語目は、sin(2x)の値が大きく異なるので、ここで区別できそうです。
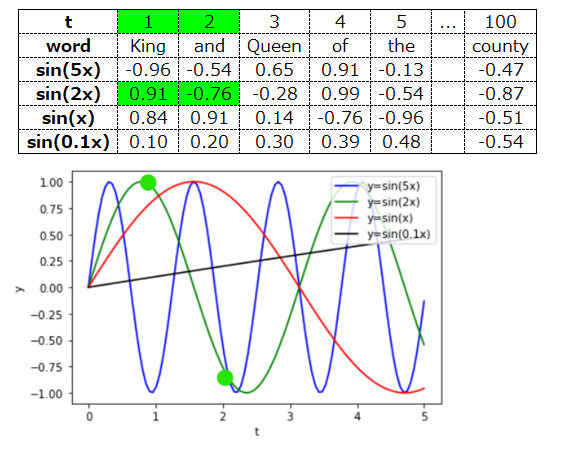
次に1語目と4語目ですが、これはsin(5x)の値が大きく異なるので、これで区別できそうです。
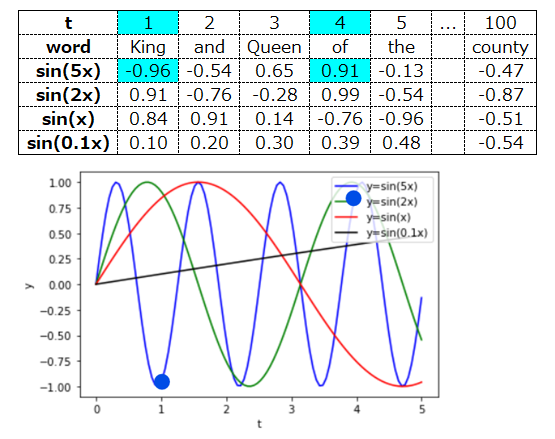
更に1語目と5語目は、sin(x)の値が大きく異なるので、区別できそうです。
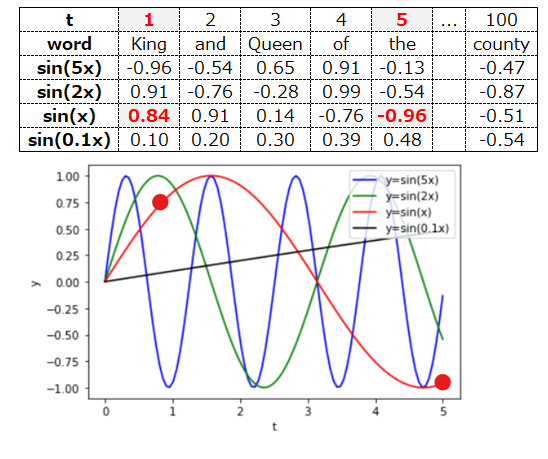
最後に5語目と100語目ですが、これはsin(0.1x)の値で区別できそうです。
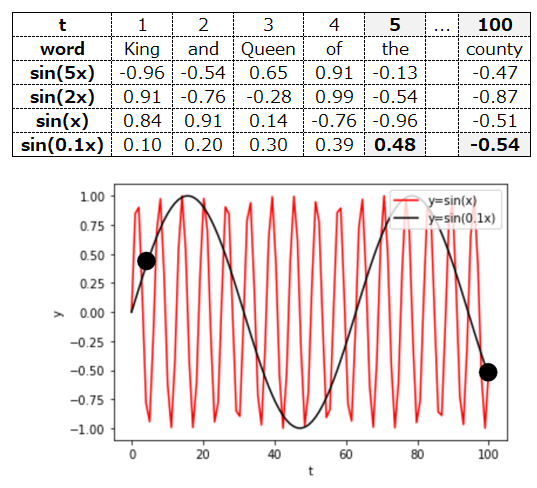
このように、様々なsin関数を組み合わせることで、大きすぎない値を使って語順を明確に区別するのが、positional encodingです。今後の記事で、Transformerの他のアーキテクチャについても説明しますのでお待ちください。
コメント