前回記事で、物体検出、セマンティックセグメンテーション、インスタンスセグメンテーションについて解説しました。

今回はその続きとして、インスタンスセグメンテーションについて、より詳しく解説します。
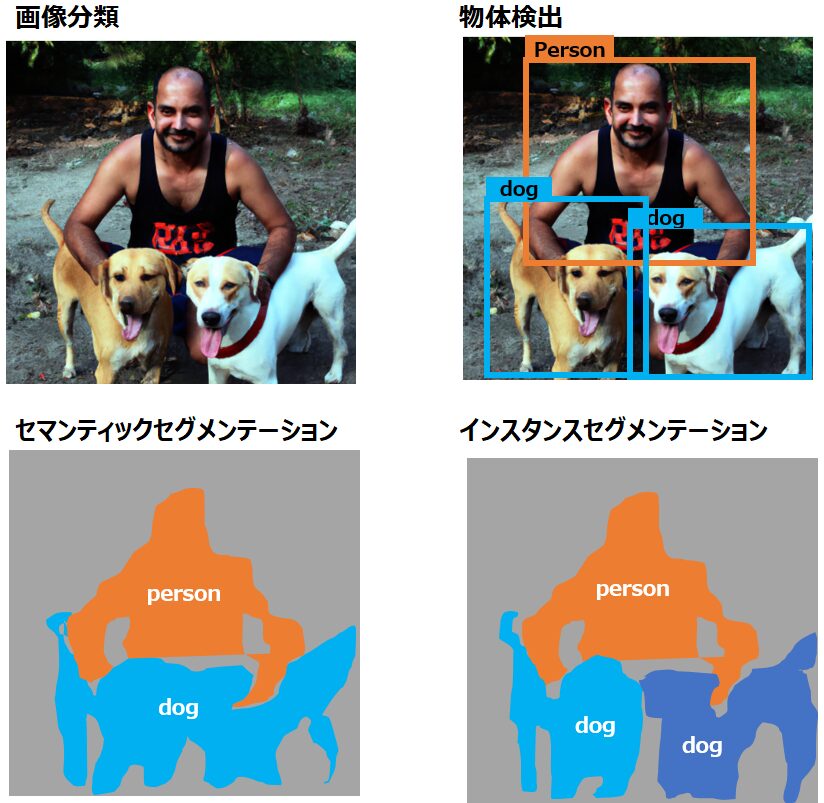
インスタンスセグメンテーションとは
インスタンスセグメンテーションモデル(Instance Segmentation Model)は、セマンティックセグメンテーションをさらに進めた技術です。”Instance”とは「事例」や「実例」といった意味がありますが、ここでは”個別の実体”を意味します。つまり、インスタンスセグメンテーションとは「個々の物体を個別の実体として認識するセグメンテーション」のことを指します。セマンティックセグメンテーションでは物体の種類が同じ場合は同じカテゴリーとしてセグメンテーションしますが、インスタンスセグメンテーションの場合は同じカテゴリーの物体であっても別々の物体として識別します。そのため、冒頭で示したように、同じ”犬”というカテゴリーに属する2つの物体をそれぞれ別のものとしてセグメンテーションできるのです。
インスタンスセグメンテーションの代表的なモデルとしては、2018年に発表された”Mask R-CNN“が挙げられます。Mask R-CNNは、物体検出手法の一つであるFaster R-CNNを基に開発されました。Faster R-CNNが画像内の物体の位置とクラスを同時に推定するのに対し、Mask R-CNNはさらにその物体の形状をピクセルレベルで推定します。具体的には、ROI(Region of Interest) Poolingではなく、より精密な形状を得ることができるROI Alignを用いて、対象物体のセグメンテーションマスクを生成します。このように、Mask R-CNNは物体検出とセグメンテーションを一度に行うことができるため、詳細な画像認識タスクにおいて非常に有用なモデルとなっています。
以下は、Mask R-CNNの元論文に掲載されているセグメンテーション画像です。

モデルの紹介
インスタンスセグメンテーションの有名なモデルとしては、R-CNNから派生したMask R-CNNと、YOLOから派生したYOLACTが挙げられます。
Mask R-CNNはFaster R-CNNに基づいており、物体検出部分(クラスとBBの出力)にセグメンテーション用の部分を追加した2段階のアプローチを採用しています。
YOLACTは、リアルタイムのインスタンスセグメンテーションを目指したモデルです。YOLACTの重要な特徴は、セグメンテーションマスクを直接予測するのではなく、一連の固定の基底マスク(プロトタイプマスク)と、それらのマスクの係数を予測するという点です。最終的な物体マスクは、これらの基底マスクとその係数の線形結合として生成されます。このプロトタイプベースのアプローチは計算コストを大幅に削減し、リアルタイム性を達成します。
Mask R-CNN
Mask R-CNNはインスタンスセグメンテーションの有名なモデルです。物体検出のFaster R-CNNのフレームワークをベースにしており、このモデルの2段階のアプローチ(物体候補の生成と物体の検出)を踏襲しています。ただし、Mask R-CNNではFaster R-CNNの物体検出の部分に、セグメンテーションのための構造を追加しています。
Mask R-CNNでは、R-CNNシリーズで使われていたROI Poolingの代わりに、ROI Alignという手法を導入しました。ROI Poolingは固定サイズにリサイズする時にプーリングによって”間引く”ような動作をしますが、ROI Alignの場合は特徴マップをただ間引くのではなく、 バイナリ補間処理 によって、より多くのピクセルの情報を使うことで推定の精度を上げられました。
この新たなブランチでは、各物体候補領域に対してバイナリマスクを予測します。これにより、物体の正確な形状を把握することができます。このマスク予測のためのブランチが、インスタンスセグメンテーションの実現に貢献しています。
このブランチの追加はシンプルなように見えますが、Mask R-CNNの最も重要な工夫点は、「RoIAlign」の導入です。RoIAlignはFaster R-CNNの「RoIPooling」を改良したもので、ピクセルレベルでの精度を求めるセグメンテーションタスクにおいて、位置のズレを引き起こす量子化の問題を解決します。
以上のような設計により、Mask R-CNNは物体検出とセグメンテーションの高精度な結果を同時に提供することができ、コンピュータビジョンの多くの応用領域で活用されています。
なお、Mask R-CNNは学習プロセスでも工夫をしています。一般的な物体検出タスクに加えてセマンティックセグメンテーションのタスクも解くことで、つまりマルチタスク学習をすることで精度を向上させています。



コメント