
G検定の出題範囲に含まれる、AIの開発と契約に関する事項ついて纏めます。
AI開発に関わる概念
CRIPS-DM
産業間で共通するデータマイニングの標準プロセスのことで、以下を指す。
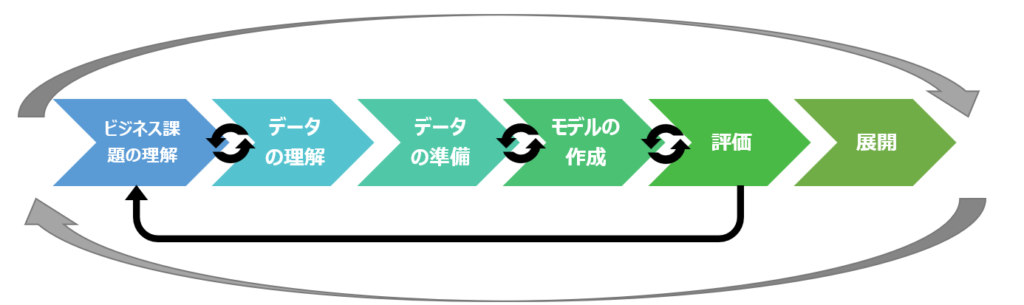
ポイントは以下の通り
- “とりあえずデータを分析してみる”ではなく、ビジネス課題を理解するところから始める
- 循環矢印の部分は、必要に応じて行き来する。
- サイクルを何度も回す
ML Ops
機械学習を表すML(Machine Learning)と運用を表すOps(Operations)を合わせた言葉。機械学習の開発チームと運用チームが協調し、実装から運用までの一気通貫の管理体制を構築することを指す。
一般的なAIの開発プロセス
以下の通り、4段階に分かれる。
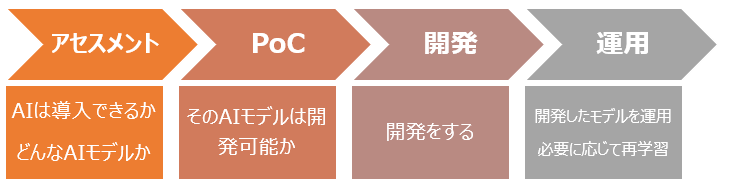
アセスメント(Assesssment)
AIが導入できるかどうか調査、評価し、KPIを設定する。評価するためにデータ・情報を集めるため、秘密保持契約(NDA)を締結することが多い。AI導入可能となったらモデルの選定、ROIの計算、本格的なデータ収集などを行う。
PoC (Proof of Concept)
アセスメントフェーズで設定した内容を達成できるかどうかを、収集したデータを用いて簡易的にでもモデルを構築することで検証する。
開発
実運用のためのモデルを開発し、納品する。
運用
運用開始後は精度をモニタリングし、随時精度向上のための再学習がされることが多い。
各開発フェーズと法律
経済産業省が以下の通り纏めている。

参照元:007_s01_00.pdf (meti.go.jp)
特許権
データの状態では発明とは認められないので対象外。AIソフトは対象となるが、そのパラメータである行列・関数は発明とは認められない。
著作権
生データそれ自体は通常創作性が認められないが、学習用データセットなどで体系的に構成され創作性を有するデータベースなどは対象となりえる。
AIソフトウェアは対象だが、リバースエンジニアリングによるモデルは対象外。
不正競争防止法
営業秘密の条件である①秘密管理性、②有用性、③非行知性の三要件を満たす場合には対象となる。ただしリバースエンジニアリングによるモデルは保護対象外。
AIと法律
詳細は以下を参照

AI開発時に締結する契約
以下内容は、前回記事でも紹介した”AI・データの利用に関する契約ガイドライン”(経産省)を参照している。
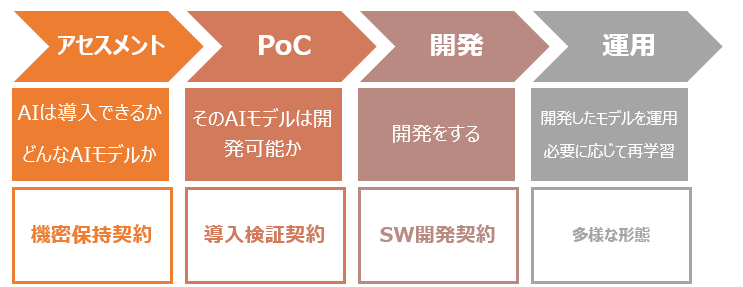
機密保持契約(NDA)
アセスメント段階で締結される。ベンダーとクライアントの間で、何が機密なのかを定義したり、機密を保持する年限を定めたりする契約。
NDAもしくは個別に、データについての取り決めも行う。本データをXXの目的のみに使用する、とか、完全性・正確性・有用性については保証しないなど。
導入検証契約
PoCの初期段階で締結される。ベンダーとクライアントの間で、一定のサンプルデータを用いた学習済モデル生成や精度向上作業を行い、開発可否や妥当性を検証し、その結果を報告することが盛り込まれる。準委任型契約が望ましい。
業務委託契約(民法)
業務委託契約は、委任型・準委任型・請負型で性質が異なる。代理店契約など、主に法律行為を委任する委任型契約に対し、準委任型契約では実際の事務処理も委任するため、広く用いられている。請負型契約の場合は、仕事の完成が契約の内容に盛り込まれるため、クライアントの望む成果を得られない場合に債務不履行に該当する可能性がある。
ソフトウェア開発契約
開発段階において締結される。ベンダーとクライアントの間で、特定の機能を有するAIプログラムの開発を規定する。契約形態は準委任型、開発形態は非ウォーターフォール型が望ましい。
非ウォーターフォール型
従来のソフトウェア開発は完成形を予め設計し、それに沿って後工程を進めることから、”滝”になぞらえてウォーターフォール開発と呼ばれている。工程を後戻りしない前提であり、最初の設計・前提に基づいてのちの工程が進むことから演繹的開発とも呼ばれる。
それに対してAIの開発はアジャイル(機敏)開発と呼ばれ、設計から開発・テストまでのプロセスを素早く繰り返す中でブラッシュアップするのが一般的。個々のフィードバックから設計や前提を書き換えていくことから、帰納的開発とも呼ばれる。
追加学習に関する契約
追加学習段階では多様な契約形態が想定され、必ずしも個別の契約を締結しない。開発段階におけるソフトウェア開発契約書の中で定めることや、保守運用契約書を締結することなどが考えられる。
学習済モデルについていずれかの契約で定めるべき事項としては以下が挙げられる。
データの取り扱い
データの質と量。提供の可否や遅延の取り扱い。データの保護。
製品(ソフト)に関する事項
AIソフトの完成義務の有無やAIソフトの性能・品質。
知財の権利帰属と利用条件
最終成果物(モデル・データセット等)や開発途中で生じた知的財産、派生モデルなどの権利がベンダーとクライアントのいずれに帰属するか、またその利用条件。
責任帰属
開発頓挫、品質不足、自己、知財侵害時の責任がベンダーとクライアントのいずれに帰属するか。通常、作成したAIの責任はベンダーに帰属するが、準委任契約を取る為、必ずベンダーが責任を取らないといけないわけではない。
クラウドとエッジ
クラウドはWebサービスとして提供する方法。エッジは、エッジデバイスにモデルをダウンロードする方法。
どちらも、常に最新の状態になるように更新されるようにする。
クラウド
Web APIを用いて、ネットワーク越しにシステム間で情報をやりとりできるようにすることで、モデルに入力データを送り、推論結果を返すことができる。
モデルの更新が楽で、装置の故障がないことがメリット。ただし、ネットワーク遅延の影響を受け、ダウンした時の影響が大きいことがデメリット。
オートスケール
クラウドを用いるケースで、サーバーの不可に応じて自動的にクラウドサーバーの台数を調整する機能。システムの安定稼働に寄与する。
エッジ
PC内でモデルを動かし、入力に対する推論結果を返す。カメラやその画像と共に使われやすい。
リアルタイム性が高く、通信量が少ないので、ネットワーク遅延を考える必要がないこと故障の影響範囲が小さいことがメリット。一方、モデルの更新が難しく、危機を長期間メンテする必要があるのがデメリット。
その他
フィードバック機構
データが蓄積され、データのフィードバックが行われ、そのデータをAIに継続的に学習させるサイクルのこと。フィードバック機構によって、AIの精度が向上し、より少ないコストで大きな成果を生みだすことができる。
AI開発においては、技術上、ビジネス上、2つの視点でフィードバック機構が必要であり、片方では不十分。
BPR(Business Process Re-engineering)の必要性
AIを利活用する場合、BPRが必須である。AIを導入した場合の業務プロセスにおいては、デジタル空間にデータを記録しながら実行することが重要。
一方、AI導入後のコストが現プロセスより増大する見込みであれば、AIの適用箇所と技術の連携範囲を再検討する必要がある。
学習済みモデルを保護する方法
既にパラメータが調性されている学習済のニューラルネットワークは、以下の3つの観点から保護が可能
- 技術:技術的工夫。例えばモデルをクラウドに置き、出力のみをサービスとして提供するなど
- 契約:条件違反の場合の賠償責任を定めた契約を締結する
- 法律:特許法、著作権法、不正競争防止法を適用する

コメント